本文首发于公众号:机器感知
任务导向的扩散模型压缩;万物皆可成像;根据舞蹈生成音乐;LLM长上下文对齐;LLM KV缓存量化;通过运动场辅助扩散模型图像编辑
Task-Oriented Diffusion Model Compression

As recent advancements in large-scale Text-to-Image (T2I) diffusion models have yielded remarkable high-quality image generation, diverse downstream Image-to-Image (I2I) applications have emerged. Despite the impressive results achieved by these I2I models, their practical utility is hampered by their large model size and the computational burden of the iterative denoising process. In this paper, we explore the compression potential of these I2I models in a task-oriented manner and introduce a novel method for reducing both model size and the number of timesteps. Through extensive experiments, we observe key insights and use our empirical knowledge to develop practical solutions that aim for near-optimal results with minimal exploration costs. We validate the effectiveness of our method by applying it to InstructPix2Pix for image editing and StableSR for image restoration. Our approach achieves satisfactory output quality with 39.2% and 56.4% reduction in model footprint and 81.4% and 68.7% decrease in latency to InstructPix2Pix and StableSR, respectively.
Spatial-and-Frequency-aware Restoration method for Images based on Diffusion Models

Diffusion models have recently emerged as a promising framework for Image Restoration (IR), owing to their ability to produce high-quality reconstructions and their compatibility with established methods. Existing methods for solving noisy inverse problems in IR, considers the pixel-wise data-fidelity. In this paper, we propose SaFaRI, a spatial-and-frequency-aware diffusion model for IR with Gaussian noise. Our model encourages images to preserve data-fidelity in both the spatial and frequency domains, resulting in enhanced reconstruction quality. We comprehensively evaluate the performance of our model on a variety of noisy inverse problems, including inpainting, denoising, and super-resolution. Our thorough evaluation demonstrates that SaFaRI achieves state-of-the-art performance on both the ImageNet datasets and FFHQ datasets, outperforming existing zero-shot IR methods in terms of LPIPS and FID metrics.
Image Anything: Towards Reasoning-coherent and Training-free Multi-modal Image Generation
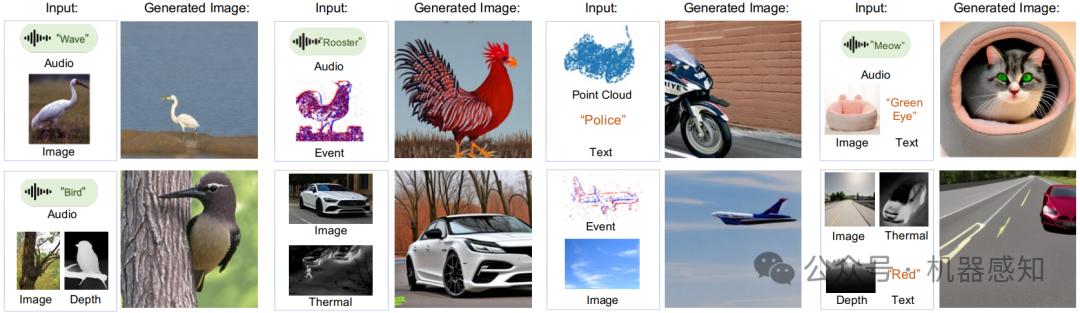
The multifaceted nature of human perception and comprehension indicates that, when we think, our body can naturally take any combination of senses, a.k.a., modalities and form a beautiful picture in our brain. For example, when we see a cattery and simultaneously perceive the cat's purring sound, our brain can construct a picture of a cat in the cattery. Intuitively, generative AI models should hold the versatility of humans and be capable of generating images from any combination of modalities efficiently and collaboratively. This paper presents ImgAny, a novel end-to-end multi-modal generative model that can mimic human reasoning and generate high-quality images. Our method serves as the first attempt in its capacity of efficiently and flexibly taking any combination of seven modalities, ranging from language, audio to vision modalities, including image, point cloud, thermal, depth, and event data. Our key idea is inspired by human-level cognitive processes and involves the integration and harmonization of multiple input modalities at both the entity and attribute levels without specific tuning across modalities. Accordingly, our method brings two novel training-free technical branches: 1) Entity Fusion Branch ensures the coherence between inputs and outputs. It extracts entity features from the multi-modal representations powered by our specially constructed entity knowledge graph; 2) Attribute Fusion Branch adeptly preserves and processes the attributes. It efficiently amalgamates distinct attributes from diverse input modalities via our proposed attribute knowledge graph. Lastly, the entity and attribute features are adaptively fused as the conditional inputs to the pre-trained Stable Diffusion model for image generation. Extensive experiments under diverse modality combinations demonstrate its exceptional capability for visual content creation.
Dance-to-Music Generation with Encoder-based Textual Inversion of Diffusion Models
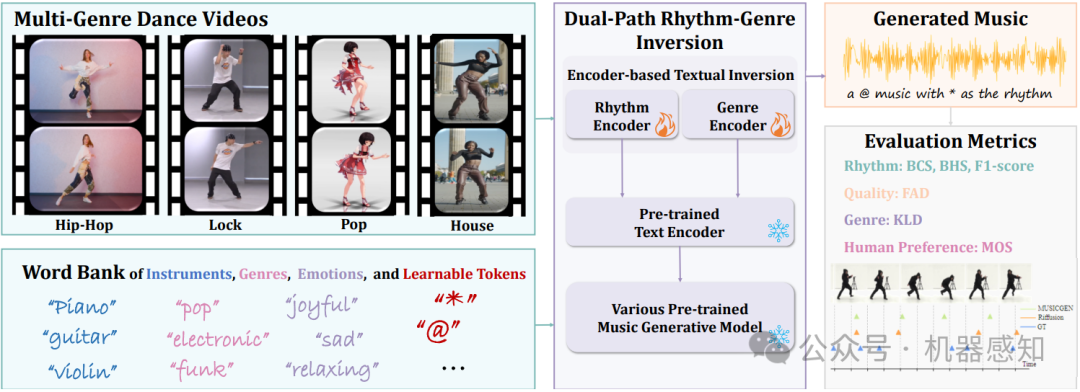
The harmonious integration of music with dance movements is pivotal in vividly conveying the artistic essence of dance. This alignment also significantly elevates the immersive quality of gaming experiences and animation productions. While there has been remarkable advancement in creating high-fidelity music from textual descriptions, current methodologies mainly concentrate on modulating overarching characteristics such as genre and emotional tone. They often overlook the nuanced management of temporal rhythm, which is indispensable in crafting music for dance, since it intricately aligns the musical beats with the dancers' movements. Recognizing this gap, we propose an encoder-based textual inversion technique for augmenting text-to-music models with visual control, facilitating personalized music generation. Specifically, we develop dual-path rhythm-genre inversion to effectively integrate the rhythm and genre of a dance motion sequence into the textual space of a text-to-music model. Contrary to the classical textual inversion method, which directly updates text embeddings to reconstruct a single target object, our approach utilizes separate rhythm and genre encoders to obtain text embeddings for two pseudo-words, adapting to the varying rhythms and genres. To achieve a more accurate evaluation, we propose improved evaluation metrics for rhythm alignment. We demonstrate that our approach outperforms state-of-the-art methods across multiple evaluation metrics. Furthermore, our method seamlessly adapts to in-the-wild data and effectively integrates with the inherent text-guided generation capability of the pre-trained model. Samples are available at \url{https://youtu.be/D7XDwtH1YwE}.
Leveraging Swin Transformer for Local-to-Global Weakly Supervised Semantic Segmentation
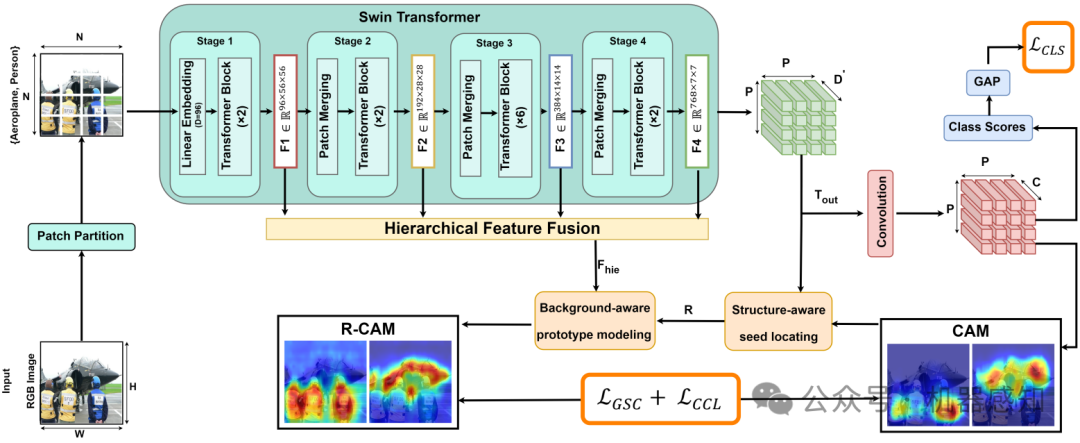
In recent years, weakly supervised semantic segmentation using image-level labels as supervision has received significant attention in the field of computer vision. Most existing methods have addressed the challenges arising from the lack of spatial information in these labels by focusing on facilitating supervised learning through the generation of pseudo-labels from class activation maps (CAMs). Due to the localized pattern detection of Convolutional Neural Networks (CNNs), CAMs often emphasize only the most discriminative parts of an object, making it challenging to accurately distinguish foreground objects from each other and the background. Recent studies have shown that Vision Transformer (ViT) features, due to their global view, are more effective in capturing the scene layout than CNNs. However, the use of hierarchical ViTs has not been extensively explored in this field. This work explores the use of Swin Transformer by proposing "SWTformer" to enhance the accuracy of the initial seed CAMs by bringing local and global views together. SWTformer-V1 generates class probabilities and CAMs using only the patch tokens as features. SWTformer-V2 incorporates a multi-scale feature fusion mechanism to extract additional information and utilizes a background-aware mechanism to generate more accurate localization maps with improved cross-object discrimination. Based on experiments on the PascalVOC 2012 dataset, SWTformer-V1 achieves a 0.98% mAP higher localization accuracy, outperforming state-of-the-art models. It also yields comparable performance by 0.82% mIoU on average higher than other methods in generating initial localization maps, depending only on the classification network. SWTformer-V2 further improves the accuracy of the generated seed CAMs by 5.32% mIoU, further proving the effectiveness of the local-to-global view provided by the Swin transformer.
LongAlign: A Recipe for Long Context Alignment of Large Language Models
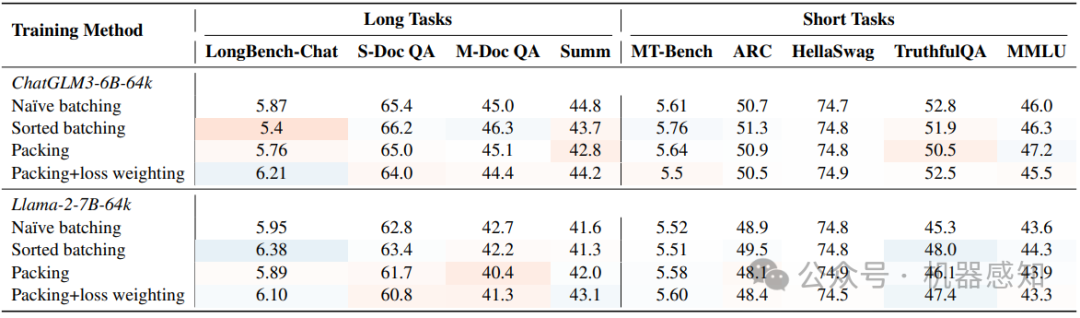
Extending large language models to effectively handle long contexts requires instruction fine-tuning on input sequences of similar length. To address this, we present LongAlign -- a recipe of the instruction data, training, and evaluation for long context alignment. First, we construct a long instruction-following dataset using Self-Instruct. To ensure the data diversity, it covers a broad range of tasks from various long context sources. Second, we adopt the packing and sorted batching strategies to speed up supervised fine-tuning on data with varied length distributions. Additionally, we develop a loss weighting method to balance the contribution to the loss across different sequences during packing training. Third, we introduce the LongBench-Chat benchmark for evaluating instruction-following capabilities on queries of 10k-100k in length. Experiments show that LongAlign outperforms existing recipes for LLMs in long context tasks by up to 30\%, while also maintaining their proficiency in handling short, generic tasks. The code, data, and long-aligned models are open-sourced at https://github.com/THUDM/LongAlign.
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
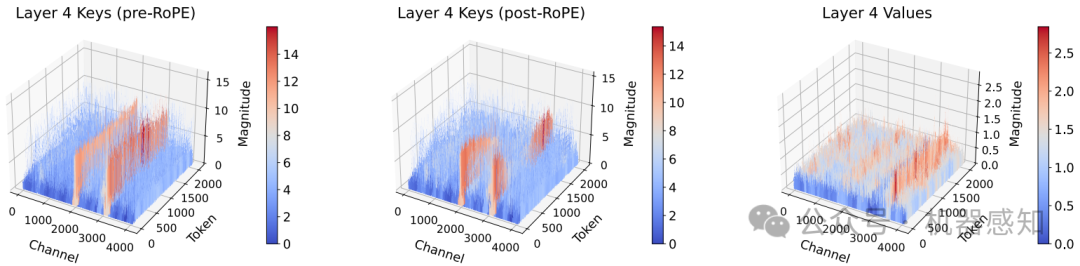
LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
Motion Guidance: Diffusion-Based Image Editing with Differentiable Motion Estimators

Diffusion models are capable of generating impressive images conditioned on text descriptions, and extensions of these models allow users to edit images at a relatively coarse scale. However, the ability to precisely edit the layout, position, pose, and shape of objects in images with diffusion models is still difficult. To this end, we propose motion guidance, a zero-shot technique that allows a user to specify dense, complex motion fields that indicate where each pixel in an image should move. Motion guidance works by steering the diffusion sampling process with the gradients through an off-the-shelf optical flow network. Specifically, we design a guidance loss that encourages the sample to have the desired motion, as estimated by a flow network, while also being visually similar to the source image. By simultaneously sampling from a diffusion model and guiding the sample to have low guidance loss, we can obtain a motion-edited image. We demonstrate that our technique works on complex motions and produces high quality edits of real and generated images.