导语:
调用链跟踪系统,又称为tracing,是微服务设计架构中,从系统层面对整体的monitoring和profiling的一种技术手
背景说明
由于我们的项目是微服务方向,中后台服务调用链路过深,追踪路径过长,其中某个服务报错或者异常很难追踪到对应链路和报错,且各个服务/模块之间的调用关系复杂,部分服务与服务之间还存在一些proxy服务(实现服务的多活部署)。这些现象就导致在开发调试、问题跟踪上都会逐步出现问题。因此,对MDC进行了调研。
MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 、logback及log4j2 提供的一种方便在多线程条件下记录日志的功能。MDC 可以看成是一个与当前线程绑定的哈希表,可以往其中添加键值对。MDC 中包含的内容可以被同一线程中执行的代码所访问。当前线程的子线程会继承其父线程中的 MDC 的内容。当需要记录日志时,只需要从 MDC 中获取所需的信息即可。MDC 的内容则由程序在适当的时候保存进去。对于一个 Web 应用来说,通常是在请求被处理的最开始保存这些数据。
跟踪链

图示中,A~E五个节点表示五个服务。用户发起一次请求RequestX到A,同时由于该请求依赖服务B与C,因此A分别发送RPC请求到B和C,B处理完请求后会直接返回到A,但是服务C还依赖服务D和E,因此还要发起两个RPC请求分别到D和E,D和E处理完毕后回到C,C才继续回复到A,最终A会回复用户ReplyX。对于这样一个请求,简单实用的分布式跟踪的实现,就是为服务器上每一次发送和接收动作来收集跟踪标识符和时间戳。
Trace和Span是两个很重要的名词。我们使用Trace表示对一次请求完整调用链的跟踪,而将两个服务例如上面的服务A和服务B的请求/响应过程叫做一次Span,trace是通过span来体现的, 通过一句话总结,我们可以将一次trace,看成是span的有向图,而这个有向图的边即为span。为了可以更好的理解这两个名词,我们可以再来看一下面的调用图。
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)上图中,包含了8个span信息
tracing过程的spans图
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
Spans的时间轴关系图
而分布式跟踪系统要做的,就是记录每次发送和接受动作的标识符和时间戳,将一次请求涉及到的所有服务串联起来,只有这样才能搞清楚一次请求的完整调用链。
设计思路
如何获取 TraceId?
虽然TraceId 贯穿于整个 IT 系统,只不过大部分时候,它只是默默配合上下文承担着链路传播的职责,没有显式的暴露出来。常见的 TraceId 获取方式有以下几种:
- 前端请求 Header 或响应体 Response:大部分用户请求都是在端上设备发起的,因此 TraceId 生成的最佳地点也是在端上设备,通过请求 Header 透传给后端服务。因此,我们在通过浏览器开发者模式调试时,就可以获取当前测试请求 Header 中的 TraceId 进行筛选。如果端上设备没有接入分布式链路追踪埋点,也可以将后端服务生成的 TraceId 添加到 Response 响应体中返回给前端。这种方式非常适合前后端联调场景,可以快速找到每一次点击对应的 TraceId,进而分析行为背后的链路轨迹与状态。
- 网关日志:网关是所有用户请求发往后端服务的代理中转站,可以视为后端服务的入口。在网关的 access.log 访问日志中添加 TraceId,可以帮助我们快速分析每一次异常访问的轨迹与原因。比如一个超时或错误请求,到底是网关自身的原因,还是后端某个服务的原因,可以通过调用链中每个 Span 的状态得到确定性的结论。
- 应用日志:应用日志可以说是我们最熟悉的一种日志,我们会将各种业务或系统的行为、中间状态和结果,在开发编码的过程中顺手记录到应用日志中,使用起来非常方便。同时,它也是可读性最强的一类日志,即使是非开发运维人员也能大致理解应用日志所表达的含义。因此,我们可以将 TraceId 也记录到应用日志中进行关联,一旦出现某种业务异常,我们可以先通过当前应用的日志定位到报错信息,再通过关联的 TraceId 去追溯该应用上下游依赖的其他信息,最终定位到导致问题出现的根因节点。
- 组件日志:在分布式系统中,大部分应用都会依赖一些外部组件,比如数据库、消息、配置中心等等。这些外部组件也会经常发生这样或那样的异常,最终影响应用服务的整体可用性。但是,外部组件通常是共用的,有专门的团队进行维护,不受应用 Owner 的控制。因此,一旦出现问题,也很难形成有效的排查回路。此时,我们可以将 TraceId 透传给外部组件,并要求他们在自己的组件日志中进行关联,同时开放组件日志查询权限。举个例子,我们可以通过 SQL Hint 传播链 TraceId,并将其记录到数据库服务端的 Binlog 中,一旦出现慢 SQL 就可以追溯数据库服务端的具体表现,比如一次请求记录数过多,查询语句没有建索引等等。
基于日志模板实现日志与 TraceId 自动关联示例
基于 SDK 手动埋点需要一行行的修改代码,无疑是非常繁琐的,如果需要在日志中批量添加 TraceId,可以采用日志模板注入的方式。
目前大部分的日志框架都支持 Slf4j 日志门面,它提供了一种 MDC(Mapped Dignostic Contexts)机制,可以在多线程场景下线程安全的实现用户自定义标签的动态注入。
第一步,我们先通过 MDC 的 put 方法将自定义标签添加到诊断上下文中:
@Test
public void testMDC() {
MDC.put("userName", "xiaoming");
MDC.put("traceId", GlobalTracer.get().activeSpan().context().toTraceId());
log.info("Just test the MDC!");
}
第二步,在日志配置文件的 Pattern 描述中添加标签变量 %X{userName} 和 %X{traceId}。
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<pattern>%d{HH:mm:ss} [%thread] %-5level [userName=%X{userName}] [traceId=%X{traceId}] %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
</appender>
这样,我们就完成了 MDC 变量注入的过程,最终日志输出效果如下所示:
15:17:47 [http-nio-80-exec-1] INFO [userName=xiaoming] [traceId=ee14662c52387763] Just test t
组件抽成
RestTemplate的http请求的处理方法
要将MDC(Mapped Diagnostic Context)的上下文信息传递到目标服务器,需要自定义一个Interceptor并添加到RestTemplate中。
- 首先,创建一个类来实现ClientHttpRequestInterceptor接口,该接口提供了对每次HTTP请求前后进行处理的能力。在preHandle()方法中获取MDC的上下文信息,然后设置到HttpHeaders中;在postHandle()方法中清除MDC的上下文信息。
添加HandlerInterceptor拦截器,塞入上下文TRACE_ID
import org.slf4j.MDC;
@Component
public class LoggerAdapterHandler implements HandlerInterceptor {
private final static String TRACE_ID = "TRACEID";
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { {
MDC.put(TRACE_ID, String spanIdNew = UUID.randomUUID().toString().replace("-","").substring(0,16));
return true;
}
}
拦截客户端请求
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RequestCallback;
import org.springframework.web.client.ResponseExtractor;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.net.URI;
import java.util.Enumeration;
@Component
public class MdcInterceptor implements ClientHttpRequestInterceptor {
private static final Logger logger = LoggerFactory.getLogger(MdcInterceptor.class);
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
HttpServletRequest servletRequest = ((ServletRequestAttributes) RequestContextHolder.currentRequestAttributes()).getRequest();
// 从MDC中获取上下文信息
Enumeration<String> mdcKeys = MDC.getCopyOfContextMap().keys();
while (mdcKeys.hasMoreElements()) {
String key = mdcKeys.nextElement();
if (!key.equals("TRACEID")) {
continue;
}
String value = MDC.get(key);
request.getHeaders().add(key, value);
}
return execution.execute(request, body);
}
}
- 然后,配置RestTemplate时注入这个Interceptor:
@Configuration
public class RestConfig {
@Bean
public RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
List<ClientHttpRequestInterceptor> interceptors = new ArrayList<>();
interceptors.add(new MdcInterceptor());
restTemplate.setInterceptors(interceptors);
return restTemplate;
}
}
最后,就可以在其他地方使用RestTemplate发起HTTP请求了,MDC的上下文信息会被自动传递到目标服务器。
tracingId生成规则:A->ThreadPool(多线程情况下tracingId不一致,重写线程池,手动赋值父线程id)->发起http请求->B系统响应或者回调,携带A的tracingId+B的tracingId->B重复A的流程调用C或者整个流程结束
A->TracingA规则->B->TracingA规则+TracingB规则->C->TracingA规则+TracingB规则+TracingC规则
A<-TracingA规则+TracingB规则+TracingC规则<-B<-TracingA规则+TracingB规则+TracingC规则<-C<-TracingA规则+TracingB规则+TracingC规则
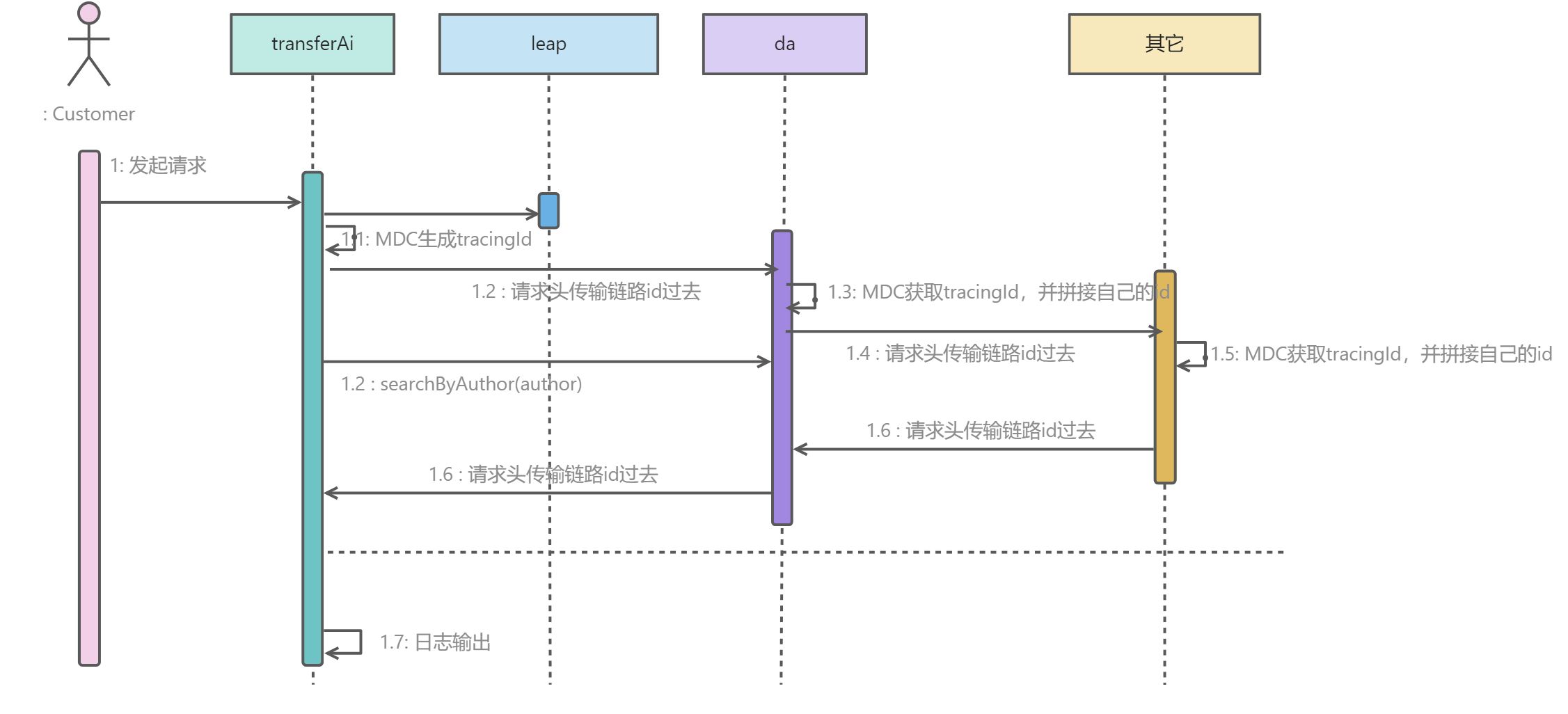
okhhtp请求的处理方式
编写okHttp的拦截器OkHttpLoggerInterceptor。此时需要日志打印的也可以在拦截器中编写请求的url,请求报文以及返回报文日志。
import com.csrcb.constants.MyConstant;
import lombok.extern.slf4j.Slf4j;
import okhttp3.*;
import okio.Buffer;
import okio.BufferedSource;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.MDC;
import org.springframework.http.HttpStatus;
import java.io.IOException;
import java.util.UUID;
/**
* @Classname OkHttpLoggerInterceptor
* @Description okhttp请求的拦截器,将traceId及parentSpanId塞入
*/
@Slf4j
public class OkHttpLoggerInterceptor implements Interceptor {
@Override
public Response intercept(Chain chain) throws IOException {
//目前默认使用的是post请求,且格式是utf8,使用的是application/json
Request request = chain.request();
//copy all headers to newheaders
Headers.Builder headers = request.headers().newBuilder();
//add traceid | spanid | parentspanid to headers
if (StringUtils.isNotBlank(MDC.get(MyConstant.TRACE_ID_MDC_FIELD))){
headers.add(MyConstant.TRACE_ID_HTTP_FIELD, MDC.get(MyConstant.TRACE_ID_MDC_FIELD));//设置X-B3-TraceId
}
if (StringUtils.isNotBlank(MyConstant.SPAN_ID_MDC_FIELD)){
headers.add(MyConstant.PARENT_SPAN_ID_HTTP_FIELD,MDC.get(MyConstant.SPAN_ID_MDC_FIELD));
}
String spanIdNew = UUID.randomUUID().toString().replace("-","").substring(0,16);
headers.add(MyConstant.SPAN_ID_HTTP_FIELD, spanIdNew);//设置X-B3-SpanId供外部使用
//rebuild a new request
request = request.newBuilder().headers(headers.build()).build();
Buffer buffer = new Buffer();
request.body().writeTo(buffer);
String requestBody = buffer.readUtf8();
String requestUrl = request.url().toString();
String[] url = requestUrl.split("/");
log.info("[Request Addr]: " + request.url());
log.info("[Service Name]: " + url[url.length - 1]+ "; [Request Body]: " + requestBody);
Response response = chain.proceed(request);
BufferedSource source = response.body().source();
source.request(Long.MAX_VALUE);
buffer = source.buffer();
String responseBody = buffer.readUtf8();
log.info("[Response Status Code]: " + response.code() + "; [Resonse Status Text]: " + HttpStatus.valueOf(response.code()).name());
log.info("[Service Name]: " + url[url.length - 1]+ "; [Response Body]: " + responseBody);
return response.newBuilder().body(ResponseBody.create(response.body().contentType(), responseBody)).build();
}
}
引入方式
<!--minio-->
<dependency>
<groupId>cn.lifecycle</groupId>
<artifactId>tracing-spring-boot-starter</artifactId>
<version>${minio.version}</version>
</dependency>
MDC 在处理多线程父子线程无法传递数据的问题
重写线程池
public class ThreadPoolExecutorMdcWrapper extends ThreadPoolExecutor {
public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
@Override
public void execute(Runnable runnable) {
super.execute(MDCUtil.wrap(runnable,MDC.getCopyOfContextMap()));
}
@Override
public Future<?> submit(Runnable runnable) {
return super.submit(MDCUtil.wrap(runnable,MDC.getCopyOfContextMap()));
}
@Override
public <T> Future<T> submit(Runnable runnable, T result) {
return super.submit(MDCUtil.wrap(runnable,MDC.getCopyOfContextMap()), result);
}
@Override
public <T> Future<T> submit(Callable<T> callable) {
return super.submit(MDCUtil.wrap(callable,MDC.getCopyOfContextMap()));
}
}
工具类
手动set 上下文
public class MDCUtil {
public static Runnable wrap(final Runnable runnable, final Map<String, String> context) {
return () -> {
if (context == null) {
MDC.clear();
}else {
MDC.setContextMap(context);
}
//如果不是子线程的话先生成traceId
setTraceIdIfAbsent();
try {
runnable.run();
}finally {
MDC.clear();
}
};
}
public static <T> Callable<T> wrap(final Callable<T> callable, final Map<String, String> context) {
return () -> {
if (context == null) {
MDC.clear();
} else {
MDC.setContextMap(context);
}
setTraceIdIfAbsent();
try {
return ((T) callable.call());
}finally {
MDC.clear();
}
};
}
public static void setTraceIdIfAbsent() {
if (MDC.get(Constants.TRACE_ID) == null) {
MDC.put(Constants.TRACE_ID, TraceIdUtil.getTraceId());
}
}
}
延展
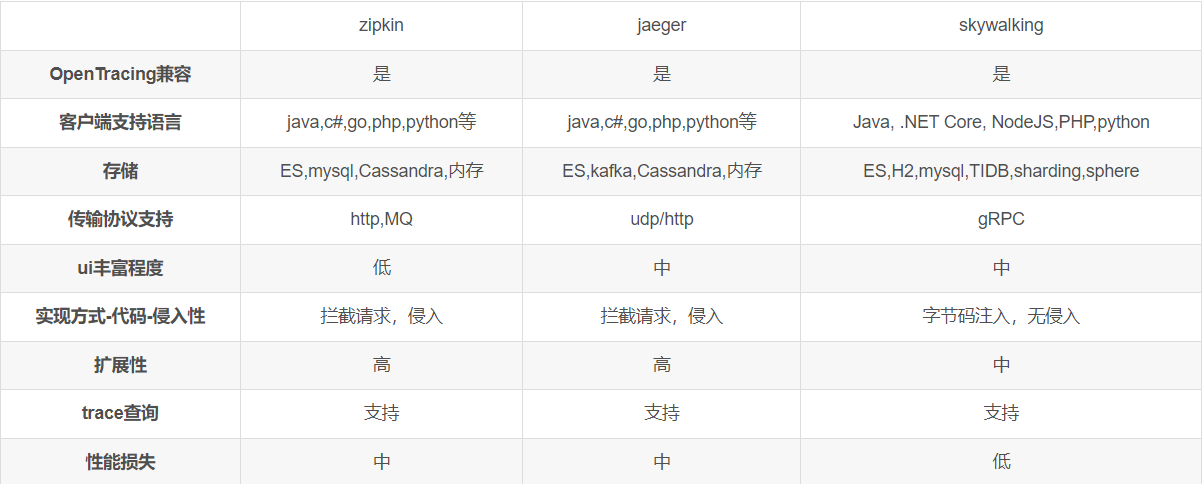
Zipkin(github ,homepage),是一款由java开发的分布式追踪系统。在微服务架构下,它用于帮助收集排查潜在问题的时序数据,同时管理数据收集和数据查询。
Jaeger(github ,homepage),则是受Dapper和OpenZipkin启发,由Uber使用golang开发的分布式跟踪系统。由于我们项目的技术栈为golang,所以重点调研了Jaeger并在此列出。
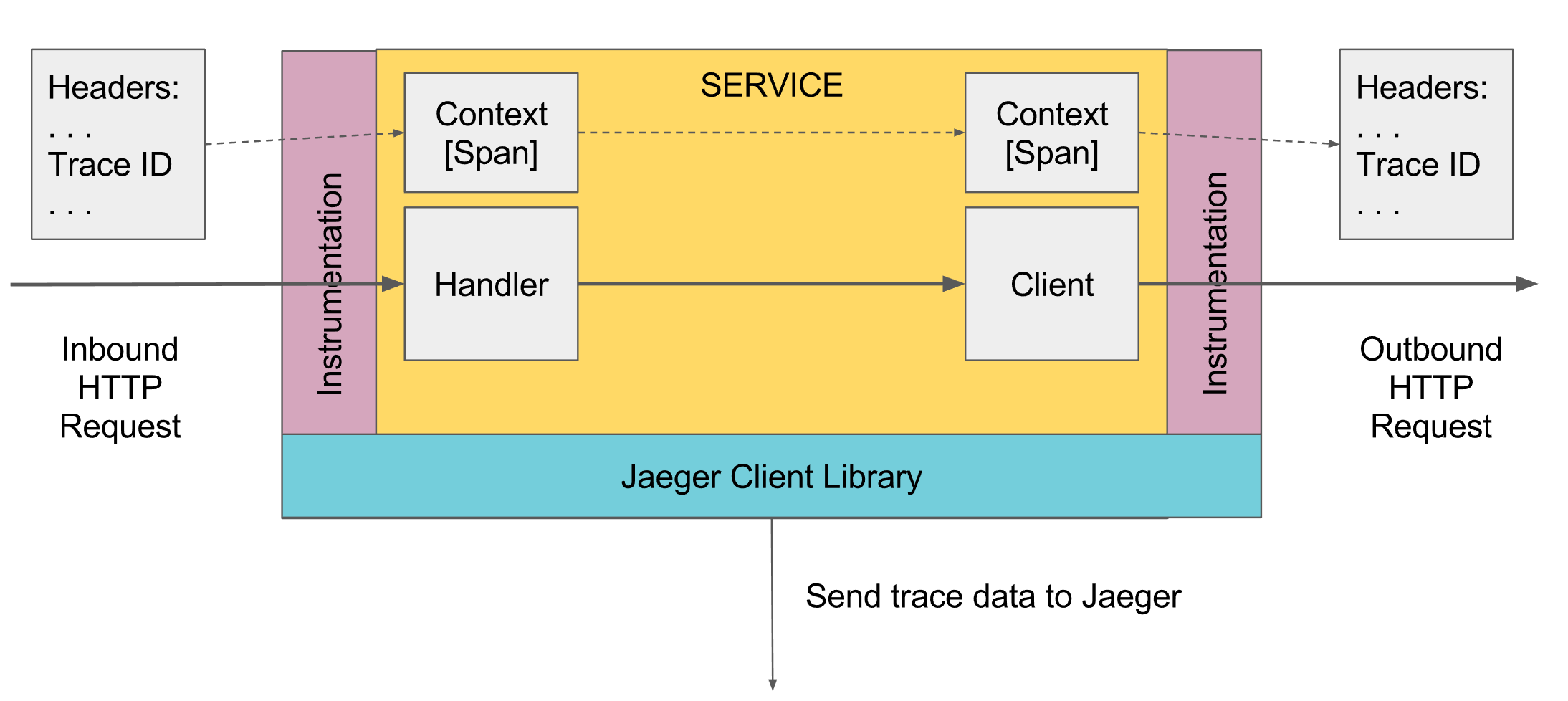
Jaeger的instrumentation过程
开源链路追踪比较