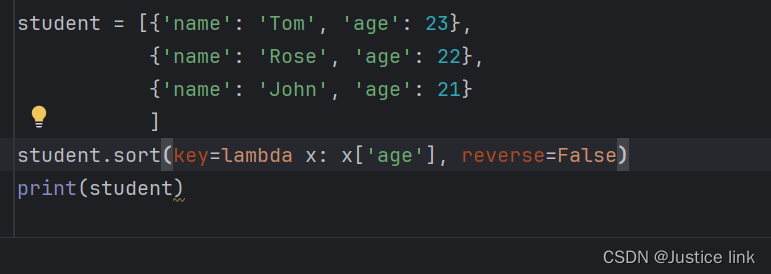
往期的Llama2-7b-chat中我们试用了官方的demo,但是那个demo只能在代码中传入固定的对话,我稍微修改了一下,使其能在命令行中不间断对话(不具备记忆功能)
代码
import os
import torch
os.environ['PL_TORCH_DISTRIBUTED_BACKEND'] = 'gloo'
os.environ['NCCL_DEBUG'] = 'INFO'
torch.distributed.init_process_group(backend="gloo")
from typing import List, Optional
import fire
from llama import Llama, Dialog
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 8,
max_gen_len: Optional[int] = None,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
# 增加一个while语句,不间断在命令行中输入、输出
while True:
user_input = input()
dialogs: List[Dialog] = [
[{"role": "user", "content": f"{user_input}"}]]
results = generator.chat_completion(
dialogs, # type: ignore
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
logprobs=True,
)
for dialog, result in zip(dialogs, results):
for msg in dialog:
print(f"{msg['role'].capitalize()}: {msg['content']}\n")
print(
f"> {result['generation']['role'].capitalize()}: {result['generation']['content']}"
)
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)
运行方式
torchrun --nproc_per_node 1 main_chat.py --ckpt_dir llama-2-7b-chat --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 1运行结果

结尾
建议使用英文,中文容易报错,后续试试把记忆功能加上去。