目录
- 写在开头
- 1. 什么是特征工程?
-
- 1.1 特征工程的定义和基本概念
- 1.2 特征工程在传统机器学习中的应用
- 1.3 时间序列领域中特征工程的独特挑战和需求
- 3. 时间序列数据的特征工程技术
-
- 2.1 数据清洗和预处理
-
- 2.1.1 缺失值处理
- 2.1.2 异常值检测与处理
- 2.2 时间特征的提取
-
- 2.2.1 时间戳解析
- 2.2.2 季节性和周期性特征提取
- 2.3 数据转换和平滑
-
- 2.3.1 对数变换
- 2.3.2 移动平均和指数平滑
- 2.4 Lag 特征的构建
-
- 2.4.1 Lagged 特征的概念
- 2.4.2 基于 Lag 的特征工程技术
- 2.5 基于窗口的特征
-
- 2.5.1 滚动统计量
- 2.5.2 滑动窗口特征
- 2.6 完整代码
- 3. 高级特征工程技术
-
- 3.1 时间序列分解
-
- 3.1.1 趋势、季节性和残差的分解技术
- 3.2 波形特征提取
-
- 3.2.1 傅里叶变换
- 3.2.2 小波变换
- 3.3 特征选择和降维
-
- 3.3.1 相关性分析
- 3.3.2 主成分分析(PCA)在时间序列中的应用
- 写在最后
写在开头
时间序列分析在各个领域都发挥着关键作用,从金融到医疗再到天气预测。为了更深入了解时间序列数据,特征工程成为了不可或缺的环节。本文将探讨时间序列分析中特征工程的重要性、技术方法以及实际案例,助您更好地应对时间序列数据的挑战。
1. 什么是特征工程?
特征工程是数据科学中至关重要的一环,它涉及对原始数据进行处理和转换,以提取出对机器学习模型建模和预测有价值的特征。在时间序列领域,特征工程的任务更为复杂,因为需要考虑数据的时序性和动态性。
1.1 特征工程的定义和基本概念
特征工程是将原始数据转换为更能反映问题本质的特征的过程。在时间序列分析中,这包括从时间戳数据中提取有用信息的步骤,如日期、星期几、季节等。通过将时间序列数据转换为可解释的特征,我们能够使模型更好地理解数据中的模式和趋势。
1.2 特征工程在传统机器学习中的应用
传统机器学习中的特征工程通常包括数据缩放、标准化和选择最相关的特征。在时间序列领域,这些基本操作仍然适用,但由于时间的引入,我们需要更深入地考虑数据的动态性。这可能涉及到滞后特征的创建,以便模型能够考虑先前时间点的信息。
1.3 时间序列领域中特征工程的独特挑战和需求
时间序列数据具有独特的性质,如趋势、季节性和周期性。因此,在特征工程中需要考虑更多的因素。例如,在处理季节性数据时,需要识别并提取季节性特征,以更好地理解数据的周期性变化。同时,处理趋势时可能需要进行平滑操作,以减少噪声的影响。
另一个挑战是处理滞后效应。在时间序列中,过去的观测值对当前和未来的预测具有重要影响。因此,特征工程需要包括滞后特征的创建,以使模型能够捕捉到这种延迟的影响。
3. 时间序列数据的特征工程技术
时间序列数据的特征工程技术在数据预处理和特征提取方面扮演着至关重要的角色。
** 构建模拟数据:**
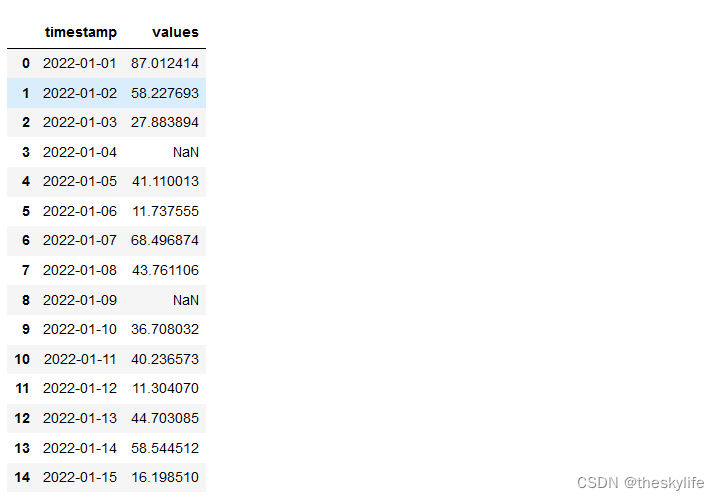
为了方便下面的演示,在此处构建模拟数据进行展示:
import pandas as pd
import numpy as np
# 构建时间序列数据
np.random.seed(25)
date_rng = pd.date_range(start='2022-01-01', end='2022-01-15', freq='D')
df = pd.DataFrame(date_rng, columns=['timestamp'])
df['values'] =np.random.rand(15)* 100
# 添加缺失值
df.loc[df.sample(frac=0.1).index, 'values'] = np.nan
df
运行上述代码后,得出具体的数据截图如下:
2.1 数据清洗和预处理
2.1.1 缺失值处理
缺失值处理是时间序列数据特征工程中的重要一环。我们经常会遇到时间序列数据中某些时间点的观测值缺失,需要采取合适的方法来处理这些缺失值。
一种常见的方法是使用插值法,根据已知的观测值在时间上进行插值来填充缺失值。比如,我们可以使用线性插值:
import pandas as pd
# 假设df是包含时间序列数据的DataFrame,其中'values'是要插值的列
df['values'] = df['values'].interpolate(method='linear')
另一种常见的方法是使用填充法,根据前后时间点的观测值来填充缺失值。这在一些场景中比较适用:
df['values'] = df['values'].fillna(method='ffill') # 使用前一个时间点的值填充
# 或者
df['values'] = df['values'].fillna(method='bfill') # 使用后一个时间点的值填充
还有一种常见的方法是删除缺失值,但在时间序列中,直接删除可能导致丢失有用的时间信息。因此,我们通常会选择更为智能的填充方法。
2.1.2 异常值检测与处理
异常值在时间序列数据中可能会对模型产生负面影响,因此需要进行检测和处理。一种常见的方法是基于统计学的方法,例如使用标准差:
# 计算平均值和标准差
mean_val = df['values'].mean()
std_val = df['values'].std()
# 定义异常值的阈值,通常是平均值加减几倍的标准差
threshold = 2.0
# 标记异常值
df['is_outlier'] = abs(df['values'] - mean_val) > threshold * std_val
# 处理异常值,可以选择替换为平均值或使用插值法
df.loc[df['is_outlier'], 'values'] = mean_val
除了基于统计的方法,还可以使用机器学习算法进行异常值检测,例如使用孤立森林(Isolation Forest):
from sklearn.ensemble import IsolationForest
# 创建孤立森林模型
model = IsolationForest(contamination=0.05) # 指定异常值比例
# 训练模型并进行异常值预测
df['is_outlier'] = model.fit_predict(df[['values']])
# 处理异常值,同样可以选择替换为平均值或使用插值法
df.loc[df['is_outlier'] == -1, 'values'] = mean_val
这些方法可以根据实际情况选择,以确保在处理缺失值和异常值时保持数据的准确性和可靠性。
2.2 时间特征的提取
2.2.1 时间戳解析
时间戳解析是将时间戳数据转换为可用于建模的特征的过程。常见的时间戳数据格式包括年月日时分秒,我们可以将其解析成不同的时间单位。
假设我们有一个包含时间戳的DataFrame:
import pandas as pd
# 假设df包含时间戳列'timestamp'
df['timestamp'] = pd.to_datetime(df['timestamp'])
# 提取年、月、日等时间特征
df['year'] = df['timestamp'].dt.year
df['month'] = df['timestamp'].dt.month
df['day'] = df['timestamp']