接前一篇文章:中移(苏州)软件技术有限公司面试问题与解答(0)—— 面试感悟与问题记录
本文内容参考:
linux内存管理笔记(四十二)----内存规整
特此致谢!
本文对于中移(苏州)软件技术有限公司面试问题中的“Linux内存规整有哪几种情况,即内存规整有几种方式?内存规整是主动发生还是被动发生?”进行解答与解析。
一、为什么需要内存规整?
内存可以说是计算机系统中最为宝贵的资源了,基本属于越多越不嫌多、永远感觉不够用。当系统长时间运行后,难免会遇到内存紧张的时候,这时候就需要内核将那些不经常使用的内存页面进行回收、或者将那些可以迁移的页面进行内存规整,从而腾出连续的物理内存页面供后续分配和使用。
本回我们只围绕内存规整展开讲解。伙伴系统是以页为单位管理内存,内存碎片也是基于页面,即由大量离散且不连续的页面组成,这就是外部碎片。所以内核对于内存碎片化,需要重新规划调整(迁移),让原本不连续的物理页面变得连续,这就是内存规整技术产生的原因。
二、内存规整的基本原理
Linux使用的是虚拟地址,以提供进程地址空间的隔离。它还带来一个好处,就是像vmalloc这种分配,不用太在乎实际使用的物理内存的分配是否连续,因此也就弱化了物理内存才会面临的内存碎片化问题。但是如果使用的时kmalloc,则要求物理内存必须连续,系统中空闲内存的总量(比如空闲时10个page),大于申请的内存大小,但是没有连续的物理内存,我们就可以通过migrate(迁移/移动)空闲的page frame,来聚合形成满足需求的连续的物理内存。
对于内存规整技术,其核心的思想是把内存页面按照可移动、可回收、不可移动等特性进行分类。详细说明如下:
- 可移动的页面:是指用户程序分配的内存,移动这些页面仅仅是需要修改页表映射关系,代价很低。
- 可回收的页面:是指不可以移动但可以释放的内存。
- 不可移动的页面:目前的内核使用的物理页面。
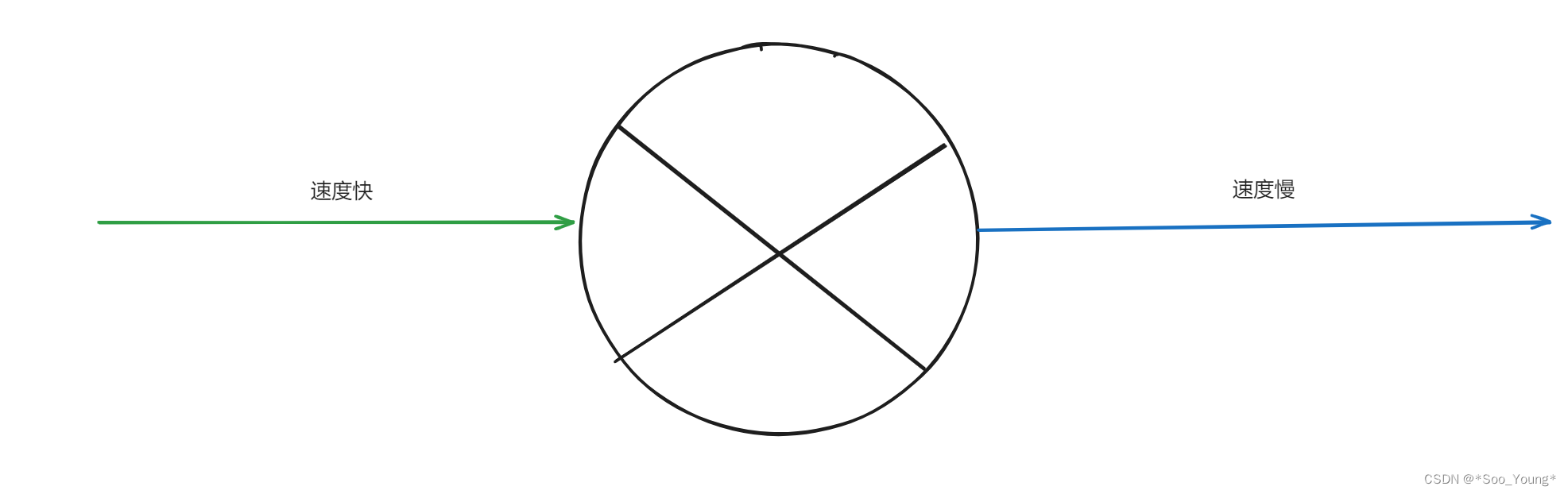
下面来演示一下规整(compaction)算法的工作原理。代码中会运行两个独立的扫描;一个扫描从区域的底部(bottom)开始(如下图所示从左往右进行扫描),一边扫描一边将可以移动(movable)的页框记录到一个列表中:
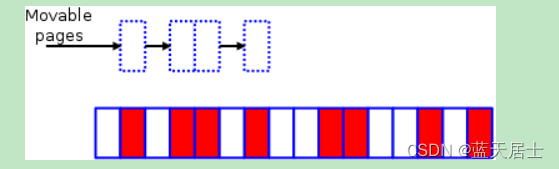
另一个扫描从区域的顶部(top)开始(如下图所示从右往左),创建另一个列表,用于记录可作为页框迁移目标的空闲页框位置:
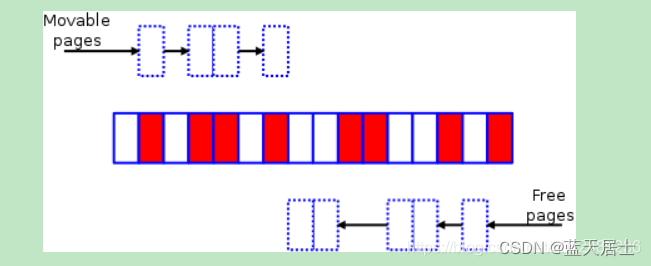
最终,两个扫描会在域中间的某个位置相遇(意味着扫描结束)。
这里顺带提一下,这种方式是一个经典的算法,同时也是一道经典的面试题(虽然不在中移的面试题中,但笔者印象中遇到过两次,一次是将近十年之前的一家小公司的面试,另一次是前不久小米的面试)。
此时,剩下的工作主要是调用页面迁移(page migration)功能(从这里我们可以看到页面迁移的功能已经不仅仅只针对 NUMA 系统)将左边扫描得到的已分配的页框上的内容转移到右边空闲的空间中,产生的结果如下如下所示,规整后的内存看上去是不是很整齐?

所以Linux的物理页面规整机制,类似于磁盘整理,主要是应用了内核的页面迁移机制,是一种将可移动页面进行迁移后腾出连续物理内存的方法。
三、 内存规整触发途径
讲完内存规整的必要性以及基本原理之后,终于来到了本次主题:内存规整有几种方式(情况)?是主动发生还是被动发生?
Linux内核中触发内存规整途径有如下三种途径:
- 手动触发
通过写1到/proc/sys/vm/compact_memory节点,会手动进行内存规整。它会扫面系统中所有的内存节点上的zone,对每个zone都会做一次内存规整。
以下是笔者在自己的Ubuntu虚拟机上手动触发内存规整的log:
ph@ph-virtual-machine:~$ ls /proc/sys/vm/
admin_reserve_kbytes dirtytime_expire_seconds max_map_count mmap_rnd_compat_bits overcommit_memory unprivileged_userfaultfd
compaction_proactiveness dirty_writeback_centisecs memfd_noexec nr_hugepages overcommit_ratio user_reserve_kbytes
compact_memory drop_caches memory_failure_early_kill nr_hugepages_mempolicy page-cluster vfs_cache_pressure
compact_unevictable_allowed extfrag_threshold memory_failure_recovery nr_overcommit_hugepages page_lock_unfairness watermark_boost_factor
dirty_background_bytes hugetlb_optimize_vmemmap min_free_kbytes numa_stat panic_on_oom watermark_scale_factor
dirty_background_ratio hugetlb_shm_group min_slab_ratio numa_zonelist_order percpu_pagelist_high_fraction zone_reclaim_mode
dirty_bytes laptop_mode min_unmapped_ratio oom_dump_tasks stat_interval
dirty_expire_centisecs legacy_va_layout mmap_min_addr oom_kill_allocating_task stat_refresh
dirty_ratio lowmem_reserve_ratio mmap_rnd_bits overcommit_kbytes swappiness
ph@ph-virtual-machine:~$
ph@ph-virtual-machine:~$ ls /proc/sys/vm/compact_memory
/proc/sys/vm/compact_memory
ph@ph-virtual-machine:~$
ph@ph-virtual-machine:~$ echo 1 > /proc/sys/vm/compact_memory
bash: /proc/sys/vm/compact_memory: Permission denied
ph@ph-virtual-machine:~$
ph@ph-virtual-machine:~$ sudo echo 1 > /proc/sys/vm/compact_memory
bash: /proc/sys/vm/compact_memory: Permission denied
ph@ph-virtual-machine:~$ ls -l /proc/sys/vm/compact_memory
--w------- 1 root root 0 1月 30 15:47 /proc/sys/vm/compact_memory
ph@ph-virtual-machine:~$ sudo su
[sudo] password for ph:
root@ph-virtual-machine:/home/ph# echo 1 > /proc/sys/vm/compact_memory
root@ph-virtual-machine:/home/ph#
- kcompactd内核线程
Linux内核会为每个NUMA节点分配一个kswapd内核线程,用于回收不经常使用的页面。同时,和页面回收kswapd内核线程一样,还会为每个内存节点创建一个kcompactd内核线程(名称为"kcompactd0",“kcompactd1"等),用于内存的规整。
NUMA节点描述符struct pglist_data中的struct task_struct *kcompactd成员,用于指向Linux内核为NUMA节点分配的kcompactd进程。而wait_queue_head_t kcompactd_wait成员用于kcompactd进程周期性规整内存时使用到的等待队列。
- 直接内存规整
和页面回收一样,当页面分配器发现在低水位的情况下无法满足页面分配时,会进入慢速路径,在慢速路径中,除了唤醒kswapd内核线程外,还会调用函数__alloc_pages_direct_compact(),尝试整合出一大块空闲内存。
到此就可以比较完美地回答面试的问题了,Linux内存规整有三种情况即方式。其中,kcompactd内核线程以及直接内存规整方式属于被动发生,而手动触发方式属于主动发生(从人的角度看,如果从系统的角度看刚好反过来)。
当然,关于内存规整与内存回收,还有太多细节以及代码需要深入。不过此处重点解答回答面试题,因此在这里不做展开了。关于这方面的详细内容,笔者将会在《Linux内存管理有什么》专栏中予以全面解析。