Redis是一款高性能的Key-Value存储系统,它可以用作缓存、消息队列、计数器、排行榜等多种应用场景。在实际应用中,如何设计和使用Redis是非常关键的。本文将介绍Redis的设计原则和最佳实践,帮助您更好地利用Redis提高应用性能和可靠性。
### 1. Redis的设计原则
Redis的设计原则主要包括以下几个方面:
#### 1.1 简单和高效
Redis追求简单和高效的设计理念,尽量减少不必要的复杂性和性能开销。例如,Redis的数据结构只包括字符串、列表、哈希表、集合和有序集合等基本数据类型,而不像其他NoSQL数据库那样支持更为复杂的数据类型。
#### 1.2 内存优先
Redis的核心数据结构都是存储在内存中的,因此其读写速度非常快。但是,内存是有限资源,因此Redis也提供了多种内存优化策略,如LRU淘汰、过期时间等,以保证内存的合理利用和最大化性能。
#### 1.3 高可靠性
Redis支持数据持久化和主从复制等功能,确保数据的可靠性和高可用性。同时,Redis也提供了多种故障恢复机制,如自动故障转移和复制切换等,以应对各种故障情况。
Redis还提供了许多高可用性和数据持久化的功能,除了主从复制之外,还有以下几种方式来提高 Redis 的可靠性:
1.3.1. 数据持久化:Redis 提供了 RDB(快照)和 AOF(日志)两种持久化方式。RDB 是将内存中的数据周期性地保存到磁盘上的快照文件,而 AOF 则是将每个写操作追加到日志文件中。可以根据需要选择合适的持久化方式,或者同时使用两种方式以增加数据的安全性。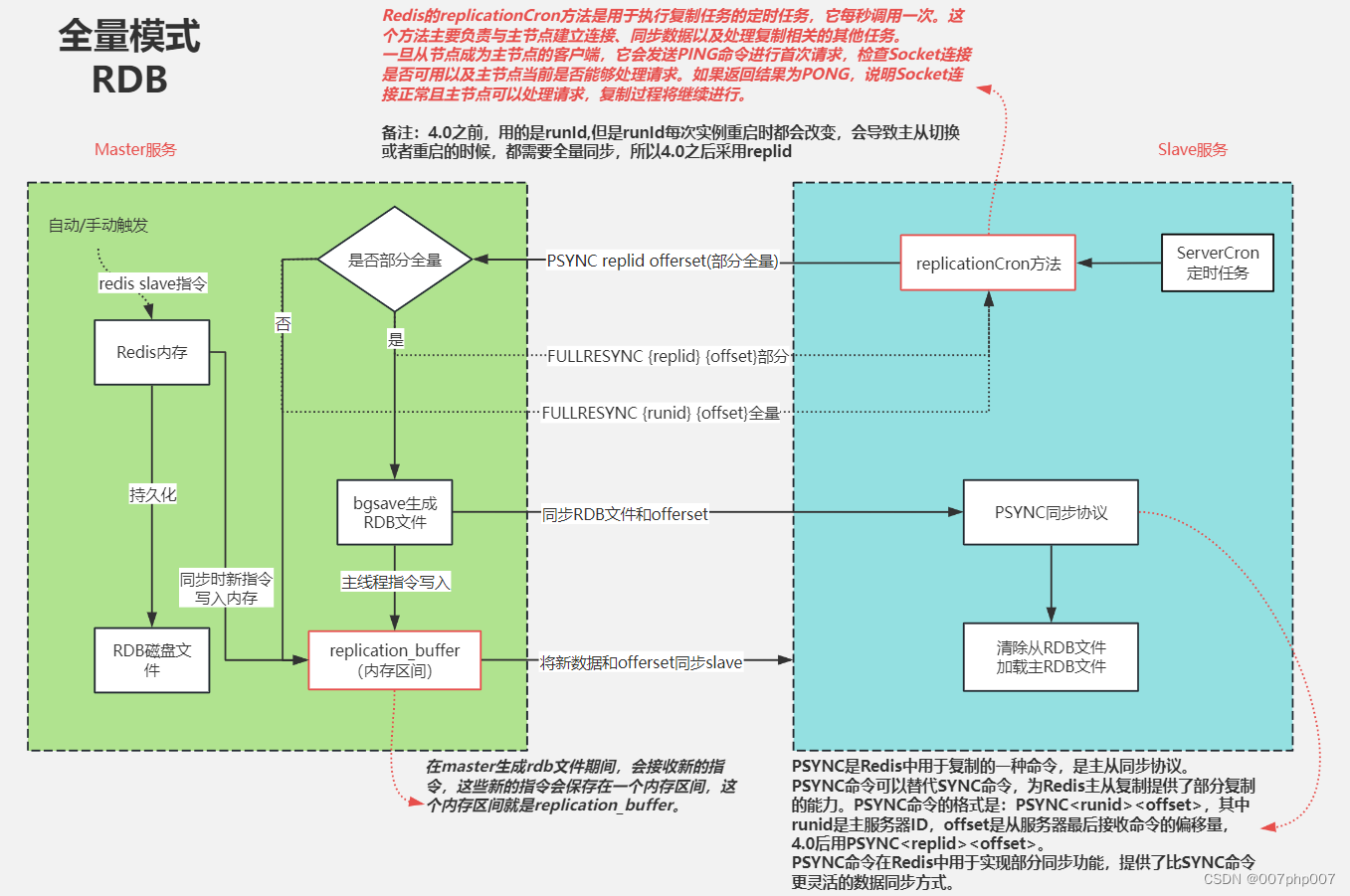
1.3.2. Sentinel 哨兵模式:Sentinel 是 Redis 官方提供的一个用于监控和自动故障转移的工具。在 Sentinel 模式下,可以配置多个 Redis 实例,其中一个作为主节点,其他实例作为从节点。当主节点出现故障时,Sentinel 会自动将一个从节点升级为新的主节点,确保系统的高可用性。
1.3.3. Cluster 集群模式:Redis Cluster 是 Redis 官方提供的分布式解决方案,可以通过横向扩展来增加系统的容量和并发处理能力。Redis Cluster 将数据分片存储在多个节点上,每个节点负责处理一部分数据。当其中一个节点出现故障时,Redis Cluster 会自动进行故障转移,以保证数据的可用性。
### 2. Redis的最佳实践
在使用Redis时,需要根据具体的场景和需求,采用相应的最佳实践。以下是一些常见的Redis最佳实践: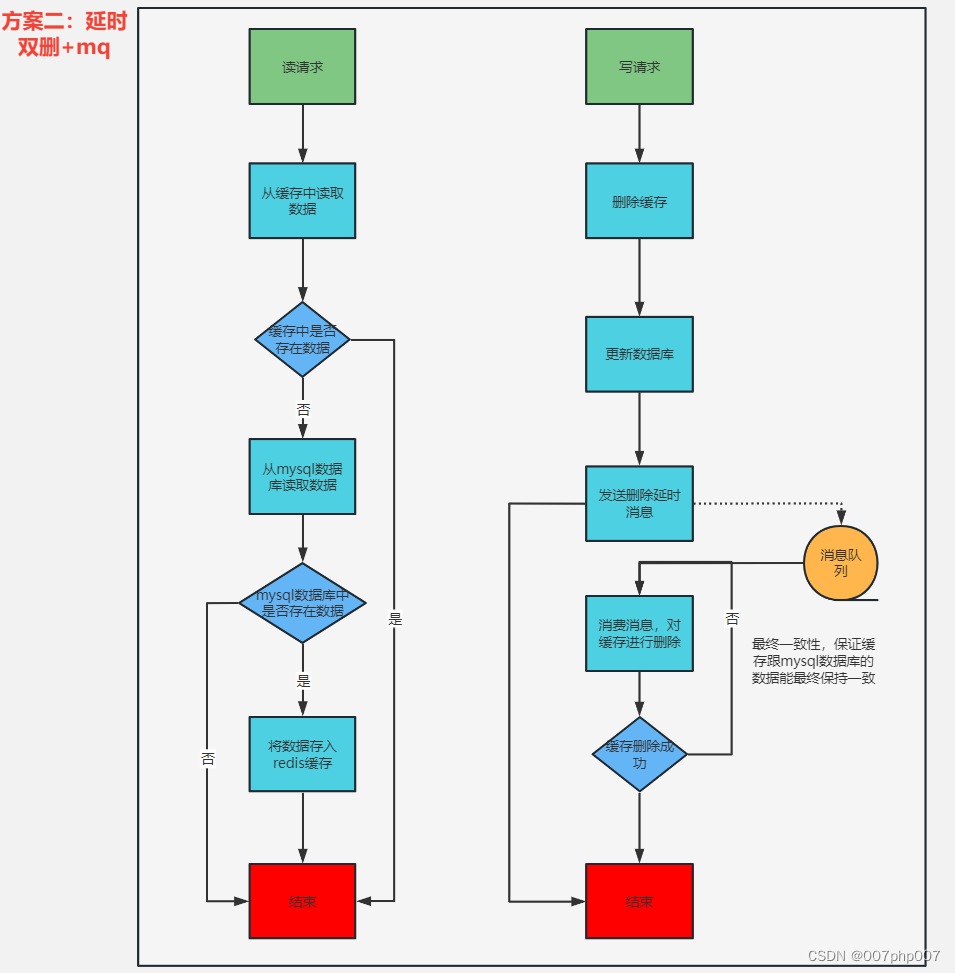
#### 2.1 缓存优化
Redis最为广泛的应用场景就是缓存。在使用Redis作为缓存时,需要注意以下几个方面:
- 合理设置缓存过期时间:如果设置过长,可能会导致缓存脏数据的问题;如果设置过短,又会影响缓存的命中率和性能。
- 避免缓存雪崩:即大量缓存同时失效,导致所有请求都访问后端数据库。可以采用随机过期时间、锁定缓存等方法来避免这种情况。
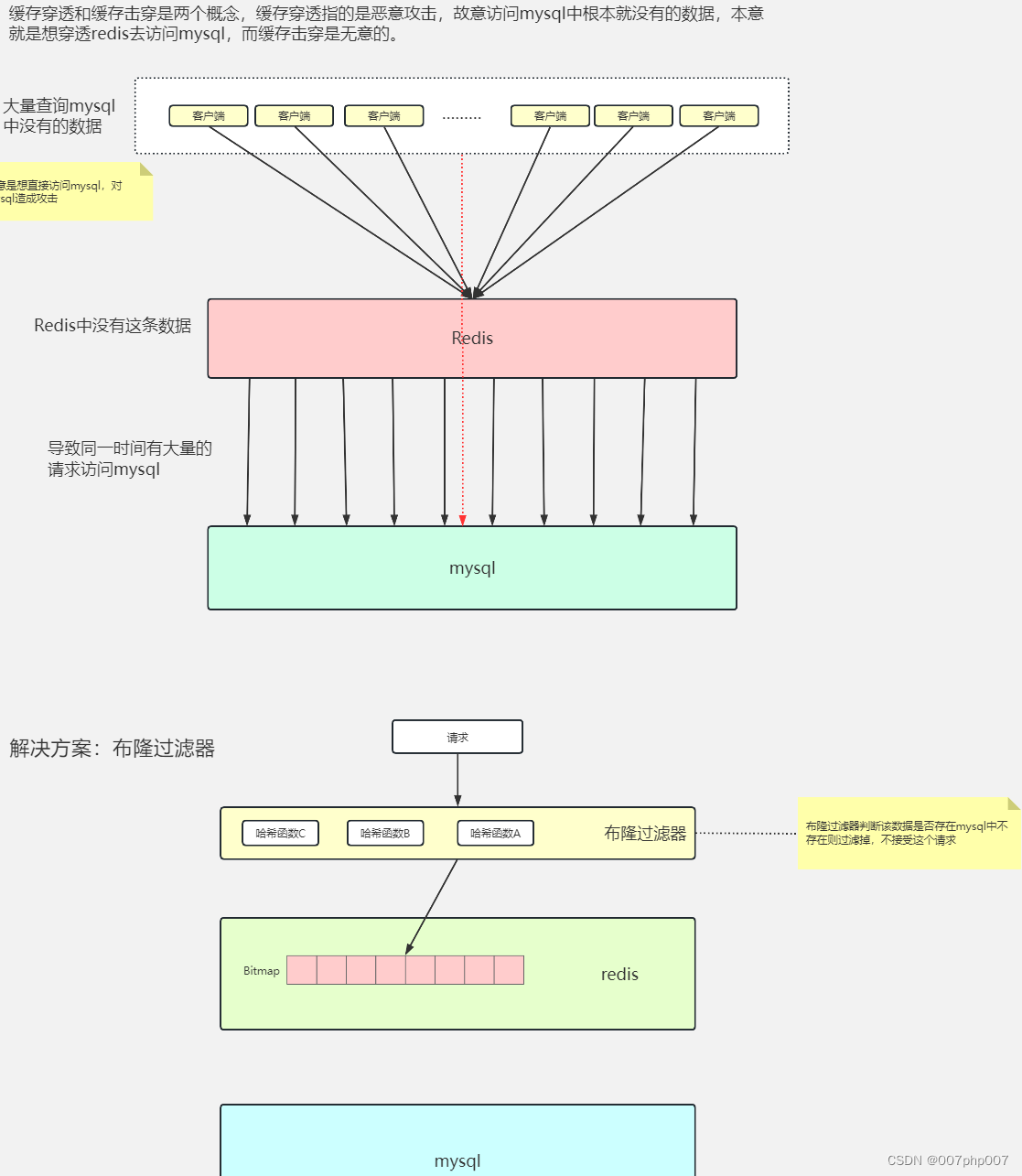
- 避免缓存穿透:即请求不存在于缓存和数据库中,导致每次请求都访问后端数据库。可以采用布隆过滤器等方法来解决这种问题。
缓存击穿以及解决方案,如下

缓存穿透以及解决方案,如下

缓存雪崩以及解决方案,如下

#### 2.2 消息队列
Redis也可以作为消息队列使用,通过PUSH和POP操作实现异步处理。在使用Redis作为消息队列时,需要注意以下几个方面:
- 避免消息丢失:可以采用持久化存储、ACK确认机制等方法来避免消息丢失的情况。
- 避免消息重复处理:可以采用幂等性设计、消息去重等方法来避免消息重复处理的情况。
- 合理设置队列长度:如果队列长度过长,可能会导致消息堆积和内存占用过高的问题;如果队列长度过短,又会影响消息处理的效率。
#### 2.3 计数器和排行榜
Redis还可以用作计数器和排行榜等功能。在使用Redis实现这些功能时,需要注意以下几个方面:
- 避免计数器溢出:可以采用64位整型数据类型或分布式计数器等方法来避免计数器溢出的情况。
- 合理选择排行榜算法:不同的排行榜算法有不同的优缺点,需要根据具体场景选择合适的算法。
### 3. 总结
Redis是一款非常优秀的Key-Value存储系统,具有简单、高效、高可靠性等优点。在应用Redis时,需要根据具体场景和需求选择相应的最佳实践,以发挥Redis的最大价值。同时,需要注意Redis的数据持久化、主从复制等功能,以保证数据的可靠性和高可用性。




![[Python-闫式DP]](https://img-blog.csdnimg.cn/direct/7bc77266e4d74a67a636753e2f7117d7.png)



![[机器学习]简单线性回归——最小二乘法](https://img-blog.csdnimg.cn/direct/00356d6433744736bcf023505acb0eb4.png)