按照我们的理解:FileOutputStream的flush()方法的作用就是将缓冲区中的数据立即写入到文件中,即使缓冲区没有填满。这样可以确保数据的及时写入,而不需要等待缓冲区填满或者调用 close() 方法关闭流时才写入。真的是这样吗???
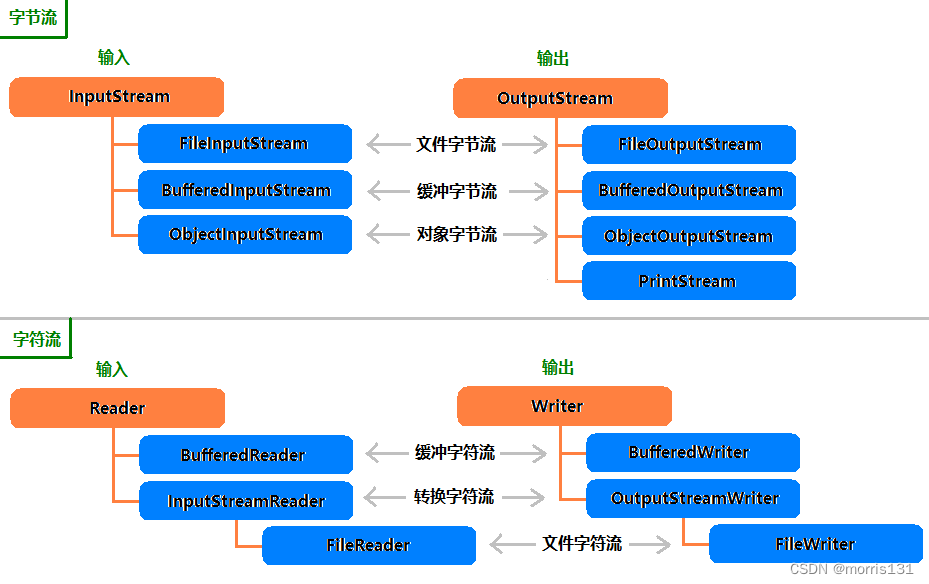
FileOutputStream的flush()丢数据演示
package com.morris.io;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* FileOutputStream丢失数据测试
*
* 直接使用虚拟机的强制关机,就会丢失数据
*/
public class FileOutputStreamMissDataTest {
public static void main(String[] args) throws IOException {
FileOutputStream outputStream = new FileOutputStream("FileOutputStreamMissDataTest.txt");
outputStream.write("abc1234567890".getBytes());
outputStream.flush();
System.in.read();
outputStream.close();
}
}
在执行完上面的代码后,直接使用虚拟机的强制关机,相当于拔掉电源,这样我们可以看到文件FileOutputStreamMissDataTest.txt创建了,但是文件大小为0。
FileOutputStream.flush()方法的实现
在为FileOutputStream写入数据后调用了flush(),试图将缓冲区中的字节全部写入文件。但查看flush()源码发现,FileOutputStream并没有实现这个方法,因而调用的实际是其父类OutputStream.flush(),但也只是一个空方法:
public void flush() throws IOException {
}
也就是说FileOutputStream.flush()方法没有任何作用,只有BufferedOutputStream这类实现了缓存区的读写流的flush()才有作用。
BufferedOutputStream.flush()方法的实现
BufferedOutputStream实现了flush()方法:
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
从BufferedOutputStream的源码可以看到,它只是在应用层建了一个数组作为buffer,当数组满了之后才会数据传递给操作系统进行写入,但不保证操作系统马上将这些字节实际写入到磁盘,只是减少了系统调用的次数,提高了写入的效率,并不能保证不丢失数据。
丢数据的原因分析
实际上我们使用OutputStream.write()方法只是将数据写入操作系统中的Page Cache中,至于操作系统何时将数据写入到磁盘中,取决于操作系统下面参数的配置:
$ sudo sysctl -a | grep "dirty"
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500
vm.dirtytime_expire_seconds = 43200
具体参数说明:
-
vm.dirty_background_bytes:设置了系统内存中可以保持脏数据的最大字节数。当系统内存中的脏数据超过这个值时,Linux会开始触发后台刷新(异步刷新)将脏数据写入磁盘。
-
vm.dirty_background_ratio:设置了系统内存中可以保持脏数据的最大比例,默认为10%。
-
vm.dirty_bytes:设置了系统内存中允许累积的脏数据的最大字节数。当脏数据超过这个值时,Linux会触发前台刷新(同步刷新),直到将脏数据写入磁盘为止。
-
vm.dirty_ratio:设置了系统内存中允许累积的脏数据的最大比例,默认为20%。
-
vm.dirty_expire_centisecs:该参数指定了脏数据在内存中能够存活的时间,单位为百分之一秒。当脏数据在内存中超过这个时间后,系统会将其异步写入磁盘中,默认值为3000(30秒)。
-
vm.dirty_writeback_centisecs:表示系统在多长时间内进行一次脏数据的后台写回操作。它的单位是百分之一秒(centiseconds),默认值为500,即系统每5秒钟进行一次后台写回操作。
-
vm.dirtytime_expire_seconds:代表内存中脏数据的允许存储时间,单位为秒。当脏数据在内存中存储的时间超过这个时间,系统会将其写入磁盘,以释放内存。
在上面的例子中,我们直接强制关机,相当于拔电源,这样操作系统来不及将Page Cache中的数据写入磁盘,这样就会导致丢失数据。
当然,除了上面操作系统被动的将Page Cache写入磁盘外,还提供了下面的系统调用主动把Page Cache中内容写入磁盘中:
-
sync:将所有未写的系统缓冲区数据写入磁盘,不需要带任何参数。
-
syncfs:syncfs需要一个文件描述符,只将文件描述符指向的文件相关的文件系统的缓冲区数据写入磁盘。
-
fsync:将文件描述符fd引用的文件修改过的元数据和数据写入磁盘。
-
fdatasync:fdatasync函数类似于fsync,但它只影响文件的数据部分。而除数据外,fsync还会同步更新文件的属性。
FileOutputStream手动强制同步Page Cache到磁盘
FileDescriptor.sync()强制所有系统缓冲区与基础设备同步。该方法在此FileDescriptor的所有修改数据和属性都写入相关设备后返回。特别是,如果此FileDescriptor引用物理存储介质,比如文件系统中的文件,则一直要等到将与此FileDesecriptor有关的缓冲区的所有内存中修改副本写入物理介质中,sync方法才会返回。
package com.morris.io;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* FileOutputStream强制同步Page Cache到磁盘
*
*/
public class FileOutputStreamSyncDataTest {
public static void main(String[] args) throws IOException {
FileOutputStream outputStream = new FileOutputStream("FileOutputStreamSyncDataTest.txt");
outputStream.write("abc1234567890".getBytes());
outputStream.flush();
outputStream.getFD().sync();
outputStream.close();
}
}
产生的系统调用如下:
openat(AT_FDCWD, "FileOutputStreamSyncDataTest.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 4
fstat(4, {st_mode=S_IFREG|0777, st_size=0, ...}) = 0
write(4, "abc1234567890", 13) = 13
fsync(4) = 0
close(4)
可以看到底层也是通过fsync系统调用来完成强制同步Page Cache到磁盘。
FileChannel手动强制同步Page Cache到磁盘
我们的代码中为了提高读写效率,经常会使用FileChannel来操作文件,那么FileChannel中有没有提供手动强制同步Page Cache到磁盘的方法呢?
FileChannel.force()方法将通道里尚未写入磁盘的数据强制写到磁盘上。出于性能方面的考虑,操作系统会将数据缓存在内存中,所以无法保证写入到FileChannel里的数据一定会即时写到磁盘上。要保证这一点,需要调用force()方法。
package com.morris.io;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
/**
* FileChannel强制同步Page Cache到磁盘
*/
public class FileChannelSyncDataTest {
public static void main(String[] args) throws IOException {
FileChannel fileChannel = new FileOutputStream("FileChannelSyncDataTest.txt").getChannel();
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put("abc1234567890".getBytes(StandardCharsets.UTF_8));
buffer.flip();
// 将数据从缓冲区写入到输出文件
fileChannel.write(buffer);
fileChannel.force(true);
buffer.clear(); // 清空缓冲区
fileChannel.close();
}
}
产生的系统调用如下:
openat(AT_FDCWD, "FileChannelSyncDataTest.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 4
fstat(4, {st_mode=S_IFREG|0777, st_size=0, ...}) = 0
write(4, "abc1234567890", 13) = 13
fsync(4)
close(4)
可以看到底层还是通过fsync系统调用来完成强制同步Page Cache到磁盘。
总结
Page Cache是Linux内核中用于提高文件读写性能的缓存机制,但是它也可能会导致数据丢失。Page Cache在计算机故障时可能会丢失数据,这是因为它的设计目标是在内存中缓存文件数据,而不是持久化存储数据。
当计算机发生故障时,如断电或系统崩溃,Page Cache中的数据可能会丢失,因为这些数据还没有被写入到磁盘上。此外,Page Cache的刷盘策略也会导致数据丢失。当Page Cache中的数据太多或太脏时,内核会将一些数据写入磁盘,但如果此时系统崩溃,尚未写入磁盘的数据可能会丢失。
为了减少数据丢失的风险,可以采取一些措施。首先,定期备份重要数据是一个好习惯,这样可以确保在Page Cache中的数据丢失后,可以从备份中恢复数据。其次,可以适当调整Page Cache的大小和刷盘策略,以减少数据丢失的风险。最后,可以使用持久化存储技术,如SSD或RAID,来提高数据的可靠性和持久性。
总之,虽然Page Cache可以提高文件读写性能,但它也可能会导致数据丢失。为了确保数据的可靠性和持久性,应该采取适当的措施来减少数据丢失的风险。