一篇数据浓缩在医疗数据集应用中的论文。
其实就是在医疗数据集上使用了data condensation的方法,这里使用了DM的方式,并且新增了浓缩时候使用不同的网络。
1. 方法
数据浓缩DC的目的是:
E
x
∼
P
D
[
L
(
φ
θ
O
(
x
)
,
y
)
]
≃
E
x
∼
P
D
[
L
(
φ
θ
c
(
x
)
,
y
)
]
\mathbb{E}_{\mathbf{x} \sim P_{\mathcal{D}}}\left[\mathrm{L}\left(\varphi_{\boldsymbol{\theta}^{\mathcal{O}}}(\mathbf{x}), y\right)\right] \simeq \mathbb{E}_{\mathbf{x} \sim P_{\mathcal{D}}}\left[\mathrm{L}\left(\varphi_{\boldsymbol{\theta}^{\mathcal{c}}}(\mathbf{x}), y\right)\right]
Ex∼PD[L(φθO(x),y)]≃Ex∼PD[L(φθc(x),y)]
对于数据x,在原始数据
O
\mathcal{O}
O和生成数据
c
\mathcal{c}
c上训练得到的模型要有接近的模型效果。
作者用DM来实现数据浓缩,并且选择随机的模型,随机的参数(作者说在DM中,只选择了一个模型的而不同参数训练,这里使用不同模型不同参数更能保护隐私)
min
C
E
ϕ
μ
k
k
∼
Φ
,
μ
k
∼
P
μ
k
∥
1
∣
O
∣
∑
i
=
1
∣
O
∣
ϕ
μ
k
k
(
x
i
)
−
1
∣
C
∣
∑
j
=
1
∣
C
∣
ϕ
μ
k
k
(
c
j
)
∥
2
\min _{\mathcal{C}} \mathbb{E}_{\phi_{\boldsymbol{\mu}_k}^k \sim \Phi, \boldsymbol{\mu}_k \sim P_{\boldsymbol{\mu}_k}}\left\|\frac{1}{|\mathcal{O}|} \sum_{i=1}^{|\mathcal{O}|} \phi_{\boldsymbol{\mu}_k}^k\left(\mathbf{x}_i\right)-\frac{1}{|\mathcal{C}|} \sum_{j=1}^{|\mathcal{C}|} \phi_{\boldsymbol{\mu}_k}^k\left(\mathbf{c}_j\right)\right\|^2
CminEϕμkk∼Φ,μk∼Pμk
∣O∣1i=1∑∣O∣ϕμkk(xi)−∣C∣1j=1∑∣C∣ϕμkk(cj)
2
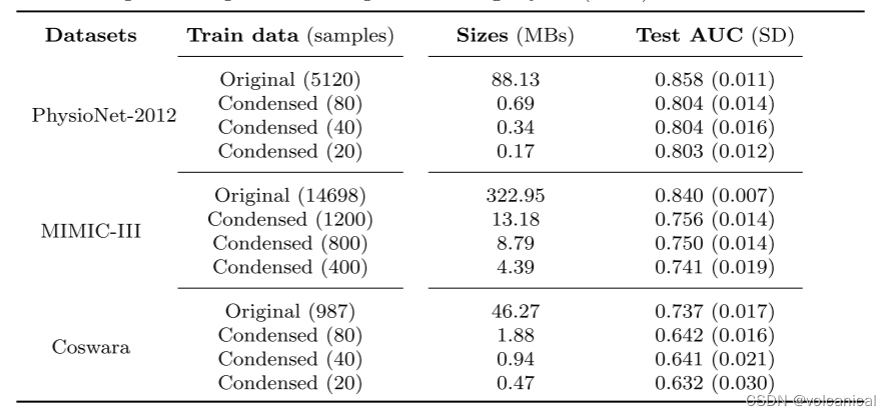
2. 结果: