问题描述
数据库节点1查询比节点2查询慢。现场操作应用发现发现同一sql语句在节点2上只要2分钟左右,在节点1,该条sql执行要超过30分钟。
处理过程
根据问题,初步判断是由于错误的执行计划,导致性能问题,但实际上对两个节点做trace跟踪发现执行计划都一致,后续通过awr报告和10046事件跟踪发现由于“gc cr multi block”耗时造成节点一慢,这是oracle RAC大事务处理特性,两边都查有可能触发数据融合,导致查询变慢。
只要把大事务的指定一个节点上执行,特别是跑批量业务,同一sql语句在同一节点上执行,修改scanip成vip,分别指定到两个vip上,修改如下内容
| (DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST =172.16.1.13)(PORT = 1521))(CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME =gwkgware))) |
把“172.16.1.13”分别改成vip地址“172.16.1.11、12”这两个地址,修改并行查询本地读取数据和连接数大小,数据库参数如下:
| sql>alter system set parallel_force_local=true sql> alter system set processes=5000 scope=spfile sid='*' sql> shutdown immediate sql> startup |
具体过程如下:
1)通过分别执行查询sql语句,收集awr、ash报告,查看top事件
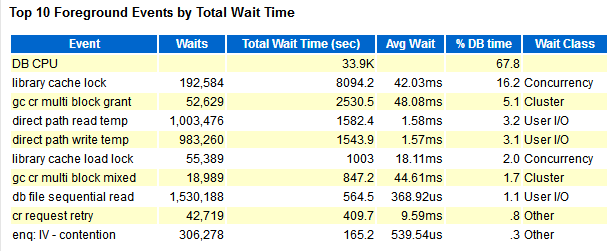
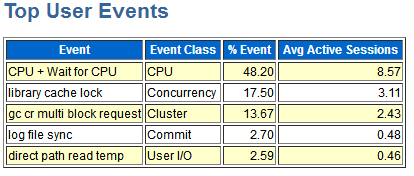

从上面分析看出“gc cr multi block request”,问题消耗主要在gc上。
2)分别对两个节点,查询分析执行计划情况
| SQL> set autot on SQL> select 2 '出场' as opertype, 3 sum(case when substrb(operator, 1, 1) = 'Z' then 1 else 0 end) in_zhzk, 4 count(*) dnum 5 from XPGCO_JZX.tyardoper 6 where data_source in ('XHCT','HR','HT') 7 and operdate > trunc(sysdate, 'dd') 8 and (opertype = 'OUTIF') 9 and conid in (select conid from XPGCO_JZX.tinyard where nvl(intradeflag, '0') = '0' and (opertype = 'OUTIF')) group by data_source; call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.00 0.00 0 0 1 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 2 47.02 3646.48 1042681 1214748 0 2 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 4 47.03 3646.49 1042681 1214748 1 2 Misses in library cache during parse: 1 Optimizer mode: ALL_ROWS Parsing user id: SYS Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ---------- ---------- ---------- --------------------------------------------------- 2 2 2 HASH GROUP BY (cr=1214748 pr=1042681 pw=0 time=1443681669 us starts=1 cost=324210 size=41 card=1) 360 360 360 HASH JOIN SEMI (cr=1214748 pr=1042681 pw=0 time=1360532233 us starts=1 cost=324209 size=41 card=1) 377 377 377 TABLE ACCESS BY INDEX ROWID BATCHED TYARDOPER (cr=293 pr=107 pw=0 time=30674 us starts=1 cost=4 size=30 card=1) 377 377 377 INDEX RANGE SCAN INDEX_TYARDOPER (cr=6 pr=2 pw=0 time=1444 us starts=1 cost=3 size=0 card=1)(object id 223446) 19754672 19754672 19754672 TABLE ACCESS FULL TINYARD (cr=1214455 pr=1042574 pw=0 time=4189352622 us starts=1 cost=324153 size=216784194 card=19707654) |
检查跟踪执行结果,两个节点基本上一致,那么执行计划没有问题。
3)通过10046进行跟踪
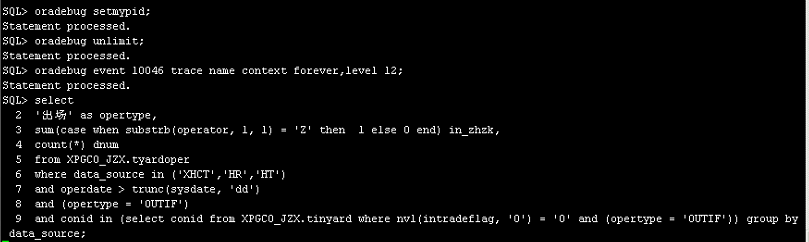
最终跟踪结果发现,节点1
| Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ PGA memory operation 20 0.00 0.00 library cache lock 4 0.00 0.00 library cache pin 3 0.00 0.00 Disk file operations I/O 24 0.00 0.00 SQL*Net message to client 2 0.00 0.00 gc cr grant 2-way 258 0.00 0.09 db file sequential read 1736 0.01 3.39 gc cr block 2-way 26 0.00 0.00 gc cr multi block mixed 3938 3.76 830.37 db file parallel read 618 0.02 1.87 gc cr multi block grant 12868 3.76 2739.71 db file scattered read 10589 0.02 35.05 gc current block 2-way 402 0.00 0.12 latch: gcs resource hash 1 0.00 0.00 gc cr disk read 302 0.00 0.10 SQL*Net message from client 2 231.62 231.62 |
主要慢在“gc cr multi block mixed”、“gc cr multi block grant”上,根据oracle RAC大事务查询的特性对应用节点访问的ip进行调整,分别调整为两个节点的vip。
4)调整后发现应用有报“ORA-12520”错误
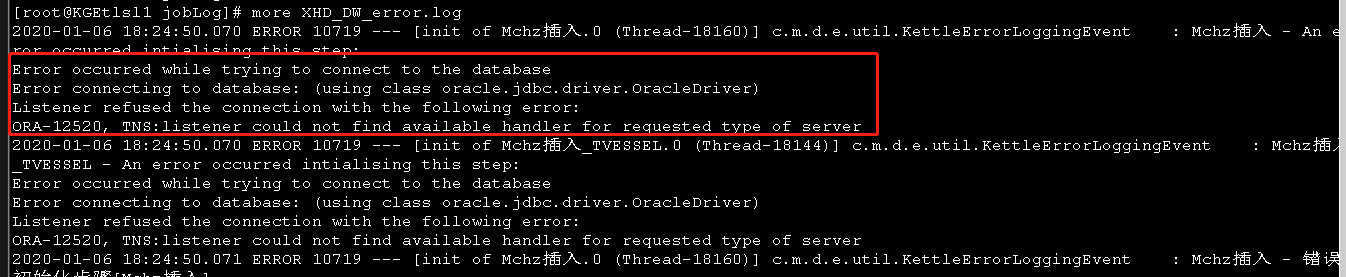
检查后台日志,有“TNS-12520”报错,参考官方资料发现,当process连接数达到设置最大值的80%才会报这个错,但不影响业务。通过select * from v$resource_limit去查询process连接数情况,当前连接数1600多,最大连接数为2000,确实达到80%以上。
只要调整processes值就可以了。原来processes值为2000,调整为5000,重启数据库恢复。
| sql> alter system set processes=5000 scope=spfile sid='*' sql> shutdown immediate sql> startup |
结论
两个节点查询速度不一致原因为查大事务,同一个sql最好在一个节点上查询,这是oracle rac的一个特性,当大事务查询在不同节点上执行,容易触发数据融合,导致其中一个节点查询变慢,特别是数据仓库执行批量业务。
所以此次调整了应用连接地址,从原来的scanip调整为vip访问。
另外调整两个参数如下:
1、parallel_force_local值为true
2、调整processes值到5000



![[Python] 什么是PCA降维技术以及scikit-learn中PCA类使用案例(图文教程,含详细代码)](https://img-blog.csdnimg.cn/direct/5d45067f8b63410a85d61f3c55a0c661.png)