Slf4j
slf4j 的全称是 Simple Loging Facade For Java,它仅仅是一个为 Java 程序提供日志输出的统一接口,并不是一个具体的日志实现方案,就比如 JDBC 一样,只是一种规则而已。所以单独的 slf4j 是不能工作的,必须搭配其他具体的日志实现方案,比如 apache 的 org.apache.log4j.Logger,jdk 自带的 java.util.logging.Logger 等。
简单语法
SLF4J 不及 Log4J 使用普遍,因为许多开发者熟悉 Log4J 而不知道 SLF4J,或不关注 SLF4J 而坚持使用 Log4J。我么先看下 Log4J 示例:
Logger.debug("Hello " + name);
由于字符串拼接的问题,使用以上语句会先拼接字符串,再根据当前级别是否低于 debug 决定是否输出本条日志,即使不输出日志,字符串拼接操作也会执行,所以许多公司强制使用下面的语句,这样只有当前处于 DEBUG 级别时才会执行字符串拼接:
if (logger.isDebugEnabled()) {
LOGGER.debug(“Hello ” + name);
}
它避免了字符串拼接问题,但有点太繁琐了是不是?相对地,SLF4J提供下面这样简单的语法:
LOGGER.debug("Hello {}", name);
它的形式类似第一条示例,而又没有字符串拼接问题,也不像第二条那样繁琐。
日志等级 Level
Slf4j 有四个级别的 log level 可供选择,级别从上到下由低到高,优先级高的将被打印出来。
-
Debug:简单来说,对程序调试有利的信息都可以debug输出
-
info:对用户有用的信息
-
warn:可能会导致错误的信息
-
error:顾名思义,发生错误的地方
使用
因为是强制规约,所以直接使用 LoggerFactory 创建
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Test {
private static final Logger logger = LoggerFactory.getLogger(Test.class);
// ……
}
配置方式
Spring Boot 对 slf4j 支持的很好,内部已经集成了 slf4j,一般我们在使用的时候,会对slf4j 做一下配置。application.yml 文件是 Spring Boot 中唯一一个需要配置的文件,一开始创建工程的时候是application.properties 文件,个人比较细化用yml文件,因为 yml 文件的层次感特别好,看起来更直观,但是 yml 文件对格式要求比较高,比如英文冒号后面必须要有个空格,否则项目估计无法启动,而且也不报错。用 properties 还是 yml 视个人习惯而定,都可以。
我们看一下 application.yml 文件中对日志的配置:
logging:
config: classpath:logback.xml
level:
com.bowen.dao: trace
logging.config是用来指定项目启动的时候,读取哪个配置文件,这里指定的是日志配置文件是classpath:logback.xml文件,关于日志的相关配置信息,都放在logback.xml文件中了。logging.level 是用来指定具体的 mapper 中日志的输出级别,上面的配置表示com.bowen.dao 包下的所有 mapper 日志输出级别为 trace,会将操作数据库的 sql 打印出来,开发时设置成 trace 方便定位问题,在生产环境上,将这个日志级别再设置成 error 级别即可。
常用的日志级别按照从高到低依次为:ERROR、WARN、INFO、DEBUG。
Log4j
Log4j 是 Apache 的一个开源项目,通过使用 Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI 组件,甚至是套接口服务器、NT 的事件记录器、UNIX Syslog 守护进程等;我们也可以控制每一条日志的输出格式;通过定义每条日志信息的级别,我们能够更加细致地控制日志的生成过程。
组成架构
Log4j 由三个重要的组成构成:日志记录器(Loggers),输出端(Appenders)和日志格式化器(Layout)。
Logger: 控制要启用或禁用哪些日志记录语句,并对日志信息进行级别限制
Appenders: 指定了日志将打印到控制台还是文件中
Layout: 控制日志信息的显示格式
Log4j 中将要输出的 Log 信息定义了 5 种级别,依次为 DEBUG、INFO、WARN、ERROR 和 FATAL,当输出时,只有级别高过配置中规定的级别的信息才能真正的输出,这样就很方便的来配置不同情况下要输出的内容,而不需要更改代码。
日志等级 Level
Log4j 日志等级主要有以下几种:
-
off:关闭日志,最高等级,任何日志都无法输出
-
fatal:灾难性错误,在能够输出日志的所有等级中最高
-
error:错误,一般用于异常信息
-
warn:警告,一般用于不规范的引用等信息
-
info:普通信息
-
debug:调试信息,一般用于程序执行过程
-
trace:堆栈信息,一般不使用
-
all:打开所有日志,最低等级,所有日志都可使用
在 Logger 核心类中, 除了 off/all 以外, 其他每个日志等级都对应一组重载的方法,用于记录不同等级的日志。当且仅当方法对应的日志等级大于等于设置的日志等级时,日志才会被记录。
使用
使用 Log4j 只需要导入一个 jar 包
<dependency>
<groupId>org.log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.9</version>
</dependency>
配置方式
在 Resources Root目录下创建一个 log4j.properties 配置文件,一定要注意:文件的位置和文件名一个都不能错,然后在 properties 文件中添加配置信息
log4j.rootLogger=debug,cons
log4j.appender.cons=org.apache.log4j.ConsoleAppender
log4j.appender.cons.target=System.out
log4j.appender.cons.layout=org.apache.log4j.PatternLayout
log4j.appender.cons.layout.ConversionPattern=%m%n
propertis 文件是最常用的配置方式。实际开发过程中,基本都是使用properties 文件。pripertis 配置文件的配置方式为:
# 配置日志等级, 指定生效的Appender名字, AppenderA是定义的Appender的名字
log4j.rootLogger=日志等级,AppenderA,AppenderB,...
# ---------------- 定义一个appender------------------------
# 定义一个appender, appender名字可以是任意的,
# 如果要使该appender生效, 须加入到上一行rootLogger中, 后面为对应的Appender类
log4j.appender.appender名字=org.apache.log4j.ConsoleAppender
log4j.appender.appender名字.target=System.out
# 定义Appender的布局方式
log4j.appender.appender名字.layout=org.apache.log4j.SimpleLayout Logback
简单地说,Logback 是一个 Java 领域的日志框架。它被认为是 Log4J 的继承人。logback 是 log4j 的升级,所以 logback 自然比log4j有很多优秀的地方。
模块组成
Logback 主要由三个模块 logback-core,logback-classic, logback-access 组成。
logback-core 是其它模块的基础设施,其它模块基于它构建,显然,logback-core 提供了一些关键的通用机制。
logback-classic 的地位和作用等同于 Log4J,它也被认为是 Log4J 的一个改进版,并且它实现了简单日志门面 SLF4J;
logback-access 主要作为一个与 Servlet 容器交互的模块,比如说 tomcat 或者 jetty,提供一些与HTTP 访问相关的功能。
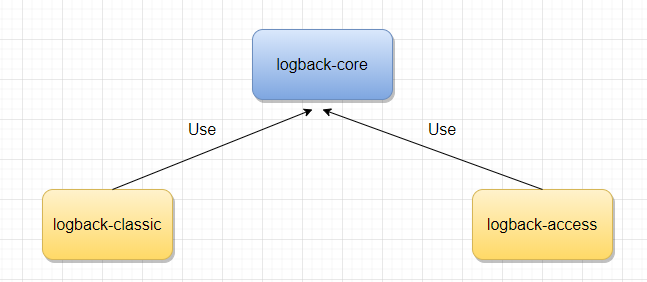
三个模块
Logback 组件
Logback主要组件如下:
-
Logger:日志的记录器;把他关联到应用对应的context上;主要用于存放日志对象;可以自定义日志类型级别
-
Appender:用于指定日志输出的目的地;目的地可以是控制台,文件,数据库等
-
Layout:负责把事件转换成字符串;格式化的日志信息的输出;在logback中Layout对象被封装在encoder中
Logback 优点
Logback主要优点如下:
-
同样的代码路径,Logback 执行更快
-
更充分的测试
-
原生实现了 SLF4J API(Log4J 还需要有一个中间转换层)
-
内容更丰富的文档
-
支持 XML 或者 Groovy 方式配置
-
配置文件自动热加载
-
从 IO 错误中优雅恢复
-
自动删除日志归档
-
自动压缩日志成为归档文件
-
支持 Prudent 模式,使多个 JVM 进程能记录同一个日志文件
-
支持配置文件中加入条件判断来适应不同的环境
-
更强大的过滤器
-
支持 SiftingAppender(可筛选 Appender)
-
异常栈信息带有包信息
标签属性
Logback主要标签属性如下:
-
configuration:配置的根节点
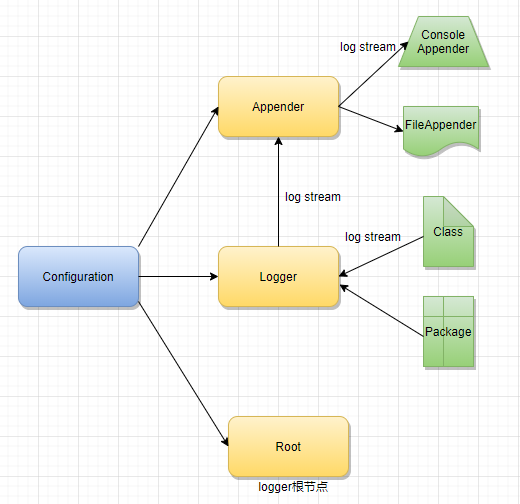
配置结构
-
scan:为ture时,若配置文件属性改变会被扫描并重新加载,默认为true
-
scanPeriod:监测配置文件是否有修改的时间间隔,若没给出时间单位,默认单位为毫秒;默认时间为1分钟;当scan="true"时生效
-
debug:为true时,将打出logback的内部日志信息,实时查看logback运行状态;默认值为false
-
contextName:上下文名称,默认为“default”,使用此标签可设置为其它名称,用于区分不同应用程序的记录;一旦设置不能修改
-
appender:configuration 的子节点,负责写日志的组件,有name和class两个必要属性
-
name:addender的名称
-
class:appender的全限定名,就是对应的某个具体的Appender类名,比如ConsoleAppender、FileAppender
-
append:为true时,日志被追加到文件结尾,如果是flase,清空现存的文件,默认值为true
配置方式
logback 框架会默认加载 classpath 下命名为 logback-spring 或 logback 的配置文件:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<property resource="logback.properties"/>
<appender name="CONSOLE-LOG" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd' 'HH:mm:ss.sss}] [%C] [%t] [%L] [%-5p] %m%n</pattern>
</layout>
</appender>
<!--获取比info级别高(包括info级别)但除error级别的日志-->
<appender name="INFO-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>DENY</onMatch>
<onMismatch>ACCEPT</onMismatch>
</filter>
<encoder>
<pattern>[%d{yyyy-MM-dd' 'HH:mm:ss.sss}] [%C] [%t] [%L] [%-5p] %m%n</pattern>
</encoder>
<!--滚动策略-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--路径-->
<fileNamePattern>${LOG_INFO_HOME}//%d.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
</appender>
<appender name="ERROR-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<encoder>
<pattern>[%d{yyyy-MM-dd' 'HH:mm:ss.sss}] [%C] [%t] [%L] [%-5p] %m%n</pattern>
</encoder>
<!--滚动策略-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--路径-->
<fileNamePattern>${LOG_ERROR_HOME}//%d.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="CONSOLE-LOG" />
<appender-ref ref="INFO-LOG" />
<appender-ref ref="ERROR-LOG" />
</root>
</configuration> ELK
ELK 是软件集合 Elasticsearch、Logstash、Kibana 的简称,由这三个软件及其相关的组件可以打造大规模日志实时处理系统。新增了一个 FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具。
-
Elasticsearch:是一个基于 Lucene 的、支持全文索引的分布式存储和索引引擎,主要负责将
日志索引并存储起来,方便业务方检索查询。 -
Logstash:是一个日志收集、过滤、转发的中间件,主要负责将各条业务线的各类日志统一收
集、过滤后,转发给 Elasticsearch 进行下一步处理。 -
Kibana:是一个可视化工具,主要负责查询 Elasticsearch 的数据并以可视化的方式展现给业
务方,比如各类饼图、直方图、区域图等。 -
Filebeat:隶属于 Beats,是一个轻量级的日志收集处理工具。目前 Beats 包含四种工具:
Packetbeat(搜集网络流量数据)、Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)、Filebeat(搜集文件数据)、Winlogbeat(搜集 Windows 事件日志数据)
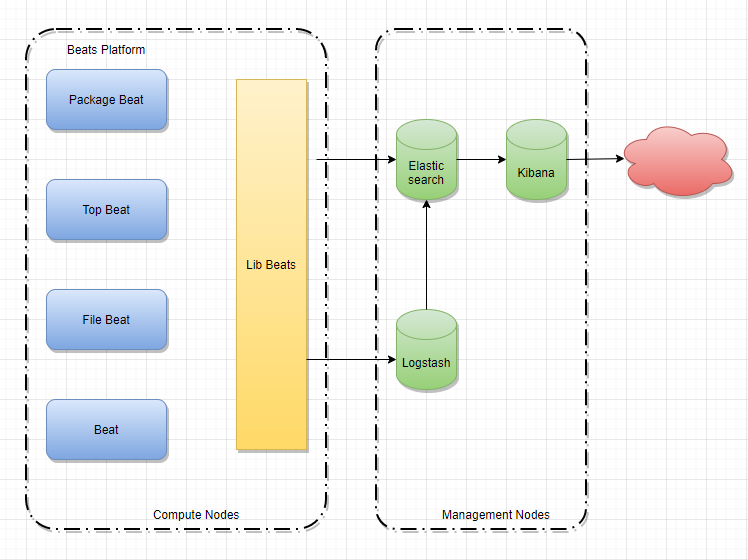
架构图
主要特点
一个完整的集中式日志系统,需要包含以下几个主要特点:
-
收集:能够采集多种来源的日志数据
-
传输:能够稳定的把日志数据传输到中央系统
-
存储:如何存储日志数据
-
分析:可以支持 UI 分析
-
警告:能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
应用场景
在海量日志系统的运维中,以下几个方面是必不可少的:
-
分布式日志数据集中式查询和管理;
-
系统监控,包含系统硬件和应用各个组件的监控;
-
故障排查;
-
安全信息和事件管理;
-
报表功能;
ELK 运行于分布式系统之上,通过搜集、过滤、传输、储存,对海量系统和组件日志进行集中管理和准实时搜索、分析,使用搜索、监控、事件消息和报表等简单易用的功能,帮助运维人员进行线上业务的准实时监控、业务异常时及时定位原因、排除故障、程序研发时跟踪分析Bug、业务趋势分析、安全与合规审计,深度挖掘日志的大数据价值。同时 Elasticsearch 提供多种 API(REST JAVA PYTHON等API)供用户扩展开发,以满足其不同需求。
配置方式
filebeat 的配置,打开filebeat.yml,进行配置,如下:
#输入源,可以写多个
filebeat.input:
- type: log
enabled: true
#输入源文件地址
path:
- /data/logs/tomcat/*.log
#多行正则匹配,匹配规则 例:2020-09-29,不是这样的就与上一条信息合并
multiline:
pattern: '\s*\['
negate: true
match: after
#起个名字
tags: ["tomcat"]
#输出目标,可以把logstash改成es
output.logstash:
hosts: [172.29.12.35:5044]
logstash 的配置,建一个以.conf为后缀的文件,或者打开 config 文件夹下的 .conf 文件,这里的配置文件是可以同时启动多个的,而且还有一个功能强大的filter功能,可以过滤原始数据,如下:
#输入源(必须)
input {
#控制台键入
stdin {}
#文件读取
file {
#类似赋予的名字
type => "info"
#文件路径,可以用*代表所有
path => ['/usr/local/logstash-7.9.1/config/data-my.log']
#第一次从头开始读,下一次继续上一次的位置继续读
start_position => "beginning"
}
file {
type => "error"
path => ['/usr/local/logstash-7.9.1/config/data-my2.log']
start_position => "beginning"
codec=>multiline{
pattern => "\s*\["
negate => true
what => "previous"
}
}
#与filebates配合使用
beats{
port => 5044
}
}
#输出目标(必须)
output {
#判断type是否相同
if [type] == "error"{
#如果是,就写入此es中
elasticsearch{
hosts => "172.29.12.35:9200"
#kibana通过index的名字进行查询,这里的YYYY是动态获取日期
index => "log-error-%{+YYYY.MM.dd}"
}
}
if [type] == "info"{
elasticsearch{
hosts => "172.29.12.35:9200"
#kibana通过index的名字进行查询
index => "log-info-%{+YYYY.MM.dd}"
}
}
#这里判断的是filebates中赋予的tags是否是tomcat
if "tomcat" in [tags]{
elasticsearch{
hosts => "172.29.12.35:9200"
#kibana通过index的名字进行查询
index => "tomcat"
}
}
#控制台也会打印信息
stdout {
codec => rubydebug {}
}
}






![[ docker相关知识 ] 删除 docker 拉取的镜像 -- 释放内存](https://img-blog.csdnimg.cn/605981e863dc4372b3e955af6a084f46.png)


![[oeasy]python0037_终端_terminal_电传打字机_tty_shell_控制台_console_发展历史](https://img-blog.csdnimg.cn/img_convert/130715e54bca66186515c3e2c34a831f.jpeg)