TCP协议
TCP全称为"传输控制协议(Transmission Control Protocol)".协议如其名,要对数据的传输进行一个详细的控制.
TCP协议段格式

源/目的端口号:表示数据从哪个进程来,到哪个进程去.
32位序号/32位确认序号:后面详细讲.
4位TCP报头长度:表示该TCP头部有多少个32位bit(有多少个四字节);这个字段是一个16比特的字段,取值范围为0-15(即最大长度为60字节).TCP头部最小长度为20字节.
保留(6位):设定报头时,提前准备的保留位(虽不用,但先占位置),后面再使用,就可以避免tcp扩展引起的不兼容问题.
6位标志位(TCP的核心部分,后面也会讲到) :
URG:紧急指针是否有效;
ACK:确认号是否有效;
PSH:提示接收端应用程序立刻从TCP缓冲区把数据读走;
RST:对方要求重新建立连接;我们把携带RST标识的称为复位报文段;
SYN:请求建立连接;我们把携带SYN标识的称为同步报文段;
FIN:通知对方,本端要关闭了,我们称携带FIN标识的为结束报文段;
16位窗口大小:后面再说
16位校验和:类似于UDP校验和,但是把报头和数据载荷放在一起计算校验和.
16位紧急指针:标识哪部分数据是紧急数据.
选项:TCP报头中的前20个字节是固定长度的.后面包含"选项这部分"(可有可无,有一个也可有多个)
确认应答
注意:这个是确保可靠性的最核心的机制了.

TCP将每个字节的数据都进行了编号,即为序列号(防止出现先发后至的问题).

每一个ACK都带有确认序列号,意思是告诉发送者,我们已经收到了哪些数据;下一次从哪里开始发.
应答报文的确认序号是按照发送过去的最后一个字节的序号+1设定.
超时重传
是确认应答的补充.
整个网络中,可能存在某个路由器/交换机.某个时刻突然负载量很高,短时间可能有大量的数据要经过这个设备转发.要知道,一台设备的处理量是有限的,很可能瞬间的高负载超出了设备量的极限,此时多出来的部分就无了(丢包了).
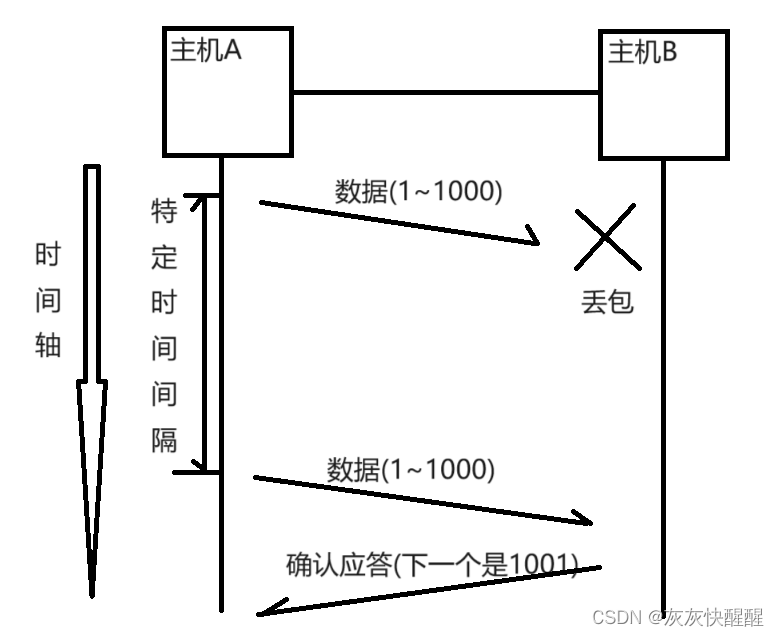
主机A在发送数据给B时,可能因为网络拥堵等原因,数据无法到达主机B;
如果主机A在一个特定的时间间隔内没有收到B的确认应答,就会进行重发;
这种情况是接收方本来就未收到数据,此时重传理所应当,没有任何问题.
但是,主机A未收到B发来的确认应答,也可能是ACK丢失了.

因此主机B会收到很多重复数据.那么TCP协议需要能够识别出哪些包是重复的包,并且把重复的包丢弃掉,这里就引入了缓冲区的概念.
TCPsocket在内核中存在接收缓冲区(一块内存空间).发送方的数据,是要先放在缓冲区中的.然后应用程序调用read/scanner.next才能读到的数据,这里的读操作是读接收缓冲区.
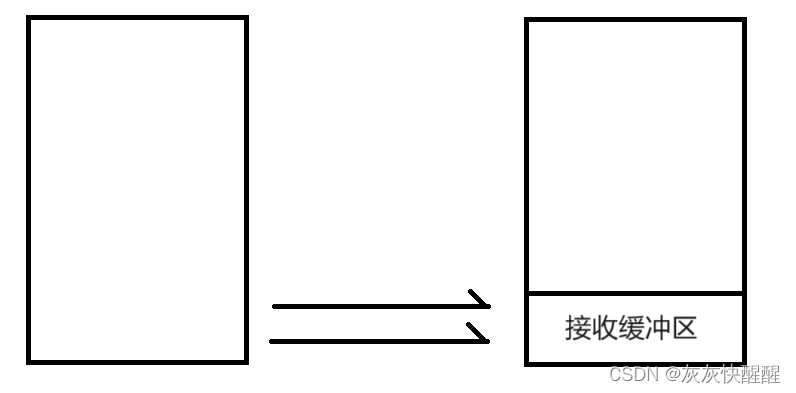
当数据到达缓冲区的时候,接收方会首先判定一下看当前缓冲区中是否有这个数据了(或者这个数据曾经在缓冲区里面存在过).就直接把新来的数据丢弃了,就能确保程序调用read/scanner.next()的时候 不会出现重复数据了.
接收方是如何判定这个数据是否是"重复数据".核心的判断依据就是根据数据的序号.
1.数据还在缓冲区中,没有被read走.此时,就拿着新收到数据的序号,和缓冲区中的所有数据序号对比一下,看看有没有一样的,有一样的就是重复了,就可以把新收到的数据丢弃.
2.数据在缓冲区中,已经被应用给read走了,此时新来的数据序号无法得到.注意:应用程序在读取数据的时候,是按照序号的先后顺序连续读取的.一定是先读小的序号,后读大的序号的数据的.(可以想象为带有优先级的阻塞序列).
此时socket api就可以记录上一次读到最后一个字节的序号是多少.比如上一次读到的序号是3000,新收到的数据序号为1001,1001一定之前读过,可以将其判断为"重复的包"直接丢掉.
这样就可以利用序列号很容易做到去重的效果,
那么,超时的时间如何确定?
最理想的状态下,找到一个最小的时间,保证"确认应答一定能在这个时间内返回".
但是这个时间的长短,随着网络环境的不同,是有差异的.
如果超时的时间设置太长,会影响整体重传的效率.
如果超时的时间设置的太短,有可能会发送重复的包.
TCP为了保证无论在任何环境下都能较高性能的通信,因此会动态计算这个最大的超时时间,
1.Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍.
2.如果重发一次之后,仍然得不到应答,等待2 * 500ms进行重传.
3.如果仍然得不到应答,等待4*500ms进行重传,以此类推,以指数形式递增.
4.累计达到一定重传次数,TCP认为网络或者对端主机出现异常,强制关闭连接.