2023 年下半年,AI Agent 正式开启「大模型下半场」。
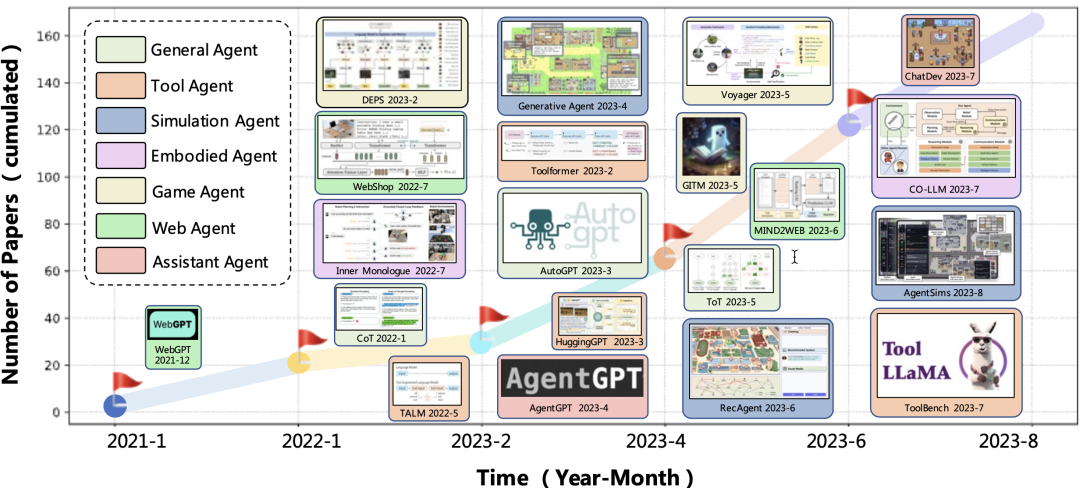
自“人工智能”这门学科创立之初,一种可以“观察世界”-“思考推理”-“做出行动”-“反思学习”的人造代理就是构建通用人工智能的终极目标之一。而基于大模型的 AI Agent 借助大模型强大的推理判断能力,为 AI Agent 的发展开启了一扇新的大门。
以 LangChain 的底层思想 ReACT 为例,大模型 Agent 在与外部环境互动时,经历“思考”-“行动”-“观察”三个步骤,通过将“行动”与“推理”结合,赋予大模型解决实际问题的能力。

但是,半年过去,直接使用类似 GPT-4 等闭源模型通过 Prompt 的方式构建 Agent 的思路尽管成绩斐然,但是不可避免的我们对这类 Agent 的掌控性往往并不高,一些结果不具有可解释性甚至不可复现。因此,一些工作开始在开源模型的基础上使用轨迹数据对模型进行微调,以使得 Agent 具备更强的解决问题的能力。
然而,微调这种思路面对着两大挑战,首先,微调需要数据,数据不可能完全由人工生成,那么不可避免的 Agent 进行规划所需的“思考轨迹”的数据依然依赖于闭源模型生成。其次,使用单一的一个语言模型,是否足够强大以使得其可以从数据中完整的学习出任务所需的一切规划能力也是一个 Agent 设计者与开发者不得不被考虑的问题。

基于此,来自浙江大学的团队 2024 年开年,创新了大模型 Agent 学习框架,提出了 AUTOACT,在不依赖大规模的标注数据和来自闭源模型合成的轨迹数据的基础上,通过分工策略生成能完成任务的子代理组,在与众多 Agent 的对比中表现出了相当不错的性能。当使用 Llama-2-13b 模型时,其表现甚至能够与 GPT-3.5-Turbo 相当!
论文题目:
AUTOACT: Automatic Agent Learning from Scratch via Self-Planning
论文链接:https://arxiv.org/pdf/2401.05268.pdf
AUTOACT 框架
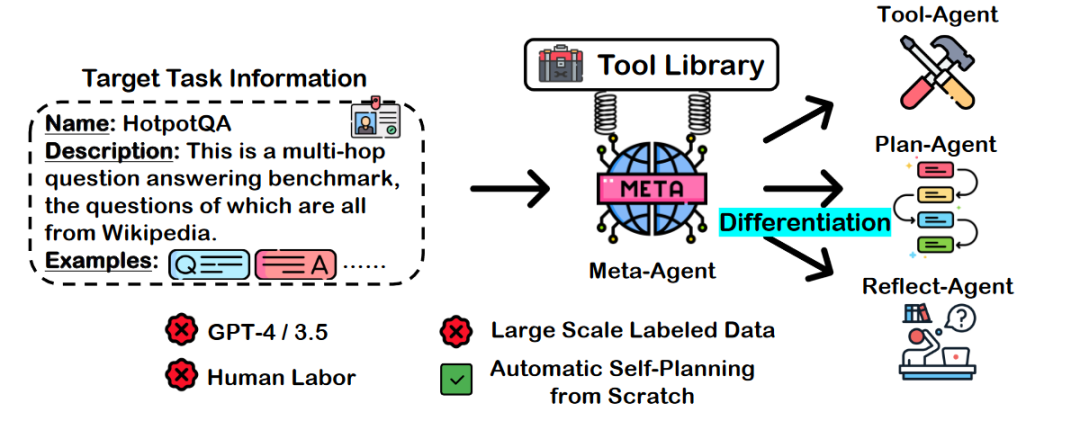
首先,让我们来宏观的看一下 AUTOACT 的框架。AUTOACT 只需要关于目标任务的相关信息以及一个大模型 Agent (论文中称为 Meta-Agent)即可启动,如下图所示,Meta-Agent 首先进行“Self-Instruct”对任务数据进行扩充,并添加到其任务数据库之中,接下来,借助可用的工具库,Meta-Agent 可以自动挑选所用的工具,合成相关的轨迹数据,并通过“Self-Differentiation”进行自我分化,构建“规划”,“工具”,“反思”三个子智能体使用数据集中的数据进行微调学习,最终在三个子智能体的“合作”下,解决相关任务。
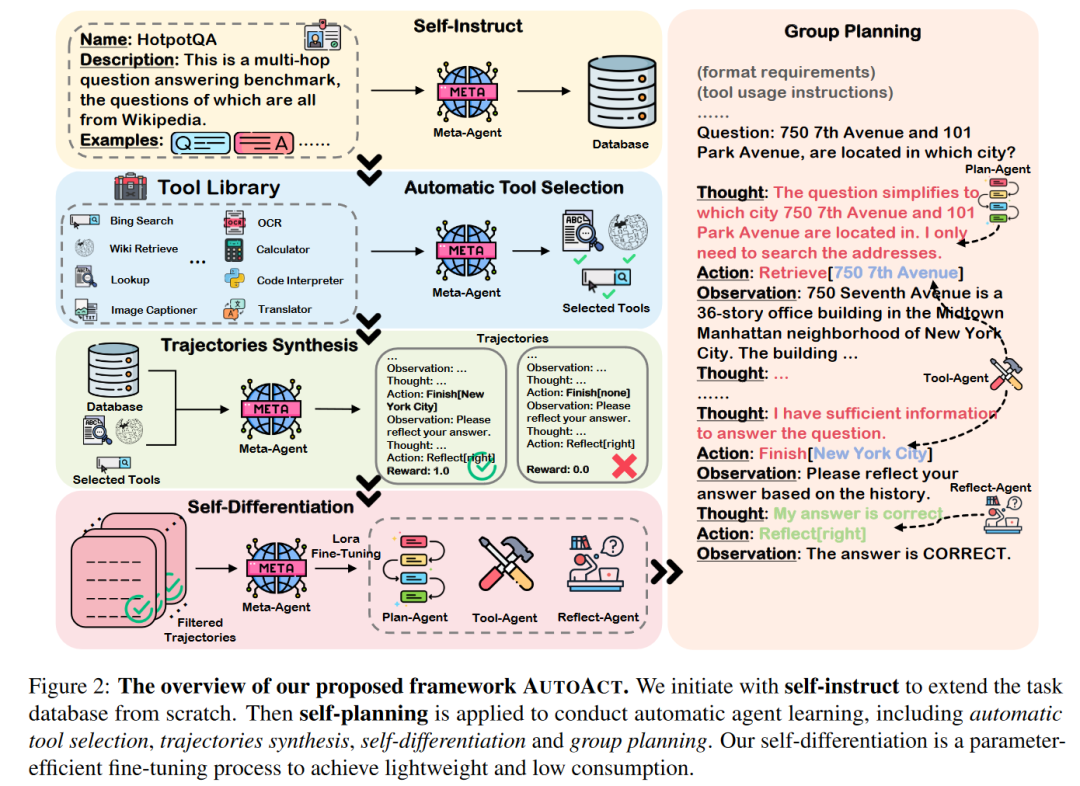
在这个框架之下,Meta-Agent 作为 AUTOACT 的中心,主要负责在分化子智能体前的一切“准备工作”,并且同时,Meta-Agent 也是分化的子智能体的基础模型。整个 Meta-Agent 可以使用任何一个开源模型进行初始化,而在论文中作者主要使用了 Llama-2 模型。
在初始时刻,任务数据库 D 被设置为仅仅包含任务描述中的示例 C,以 C 作为“种子”,在 Self-Instruct 阶段 Meta-Agent 通过 Few-shot 的方式生成新的“问题-答案”对,并添加到数据库 D 中,Few-shot 的示例数据由 D 中随机采样,依次重复知道数据库中数据量满足任务所需即停止。其 Few-shot 的 Prompt 为:

在通过 Self-Instruct 搭建起数据集后,Meta-Agent 接下来完成“工具选择”与“轨迹合成”两步,其中工具选择用于从工具库中挑选完成任务所需的工具,其 Prompt 为:

可以看到,在选择过程中,Meta-Agent 将为接下来分化的三个子 Agent 分别选择其所用的工具。在挑选好工具后,在不依赖闭源模型的情况下,论文使用 Zero-shot 的方式使得 Meta-Agent 基于数据集合成模型的思考轨迹数据,遵循 ReACT 的“思考”-“行动”-“观察”模式生成轨迹数据,从而辅助分化子智能体进行微调:

在合成轨迹数据之后,Meta-Agent 在 AUTOACT 中将进行自我分化,分化为“规划”,“工具”,“反思”三个子智能体,其中规划智能体 完成任务分解并决策在每次循环中调用哪个工具,工具智能体 用于生成调用工具的相关参数,反思智能体 通过考虑所有历史轨迹进行整体反思。在轨迹数据集的基础上,通过如下输入数据对使用 LoRA 对每个子智能体进行微调:
其中, 表明“思考”输出, 表示动作名称, 表示动作相关参数。 与 表示反思过程中的思考与行动。 分别表示任务综合信息,工具集以及历史信息。
由于进行了分化,因此在完成任务中,AUTOACT 需要子智能体之间的“配合”才能完成任务。首先任务信息进入规划智能体进行任务分解,返回所需工具名称 ,随后工具智能体被激活生成工具参数 并传输到特定的工具,返回工具的使用结果作为观测,在规划智能体与工具智能体进行互动给出任务结果后,反思智能体被激活,如果反思结表明认可任务结果,则结束任务,如果不认可则结合反思进行进入下一轮循环。
实验结果
论文实验主要在 HotpotQA 与 ScienceQA 两个问答数据集中进行,整体 AUTOACT 使用 Llama-2 作为 Meta-Agent,并与思维链 CoT,ReAct,Reflexion,Chameleon,FIREACT,BOLAA 以及 GPT-3.5Turbo 进行对比,结果如下:
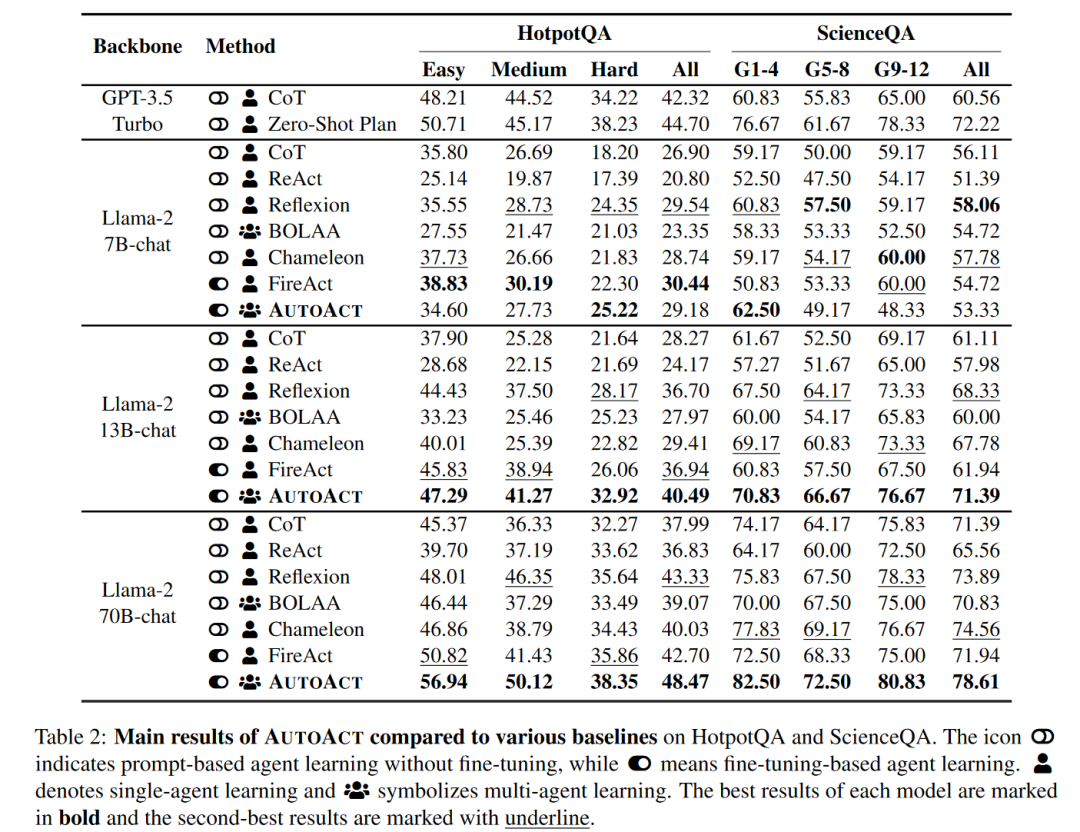
可以看出,AUTOACT 方法在 Llama-2 13B 和 70B 基础下训练出的 Agent 全线优于其他所有直接提示方法、CoT 与 Agent 方法。13B 的模型做到了与 GPT-3.5 Turbo 性能相差不多,而 70B 模型甚至超越了 GPT-3.5-Turbo,在 HotpotQA 实现了 3.77% 的提升,在 ScienceQA 上实现了 6.33% 的提升。
而进一步与基于闭源模型数据的微调模型 FIREACT 进行对比,尽管 FIREACT 使用了 GPT-4,但是在 70B 基础上的 AUTOACT 在 HotpotQA 上提升了 5.77%,在 ScienceQA 上提升了 6.67%。值得注意的是这一结果是建立在 AUTOACT 完全没有使用任何强大的闭源模型进行辅助的基础之上的。
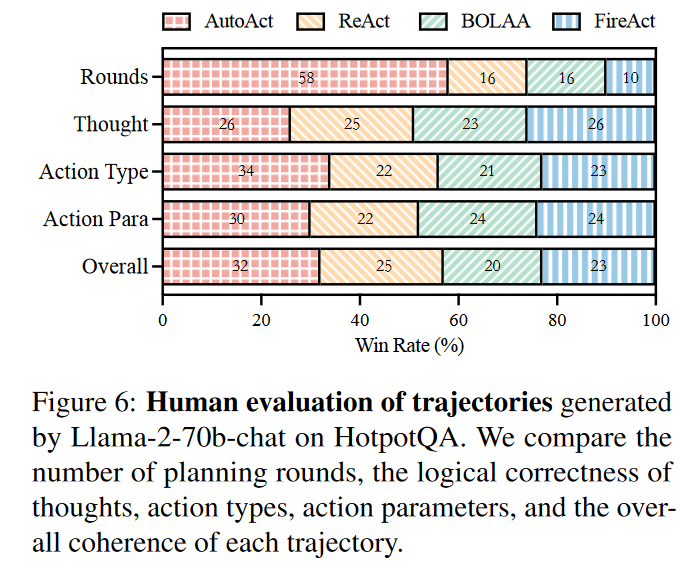
此外,作者还对 HotpotQA 中由 AUTOACT 生成的轨迹数据对比其他 Agnet 方法进行了人工评估,五位 NLP 专家从规划轮数、思维逻辑正确性、动作类型、动作参数与整体连贯性等方面综合评估,结果如下:
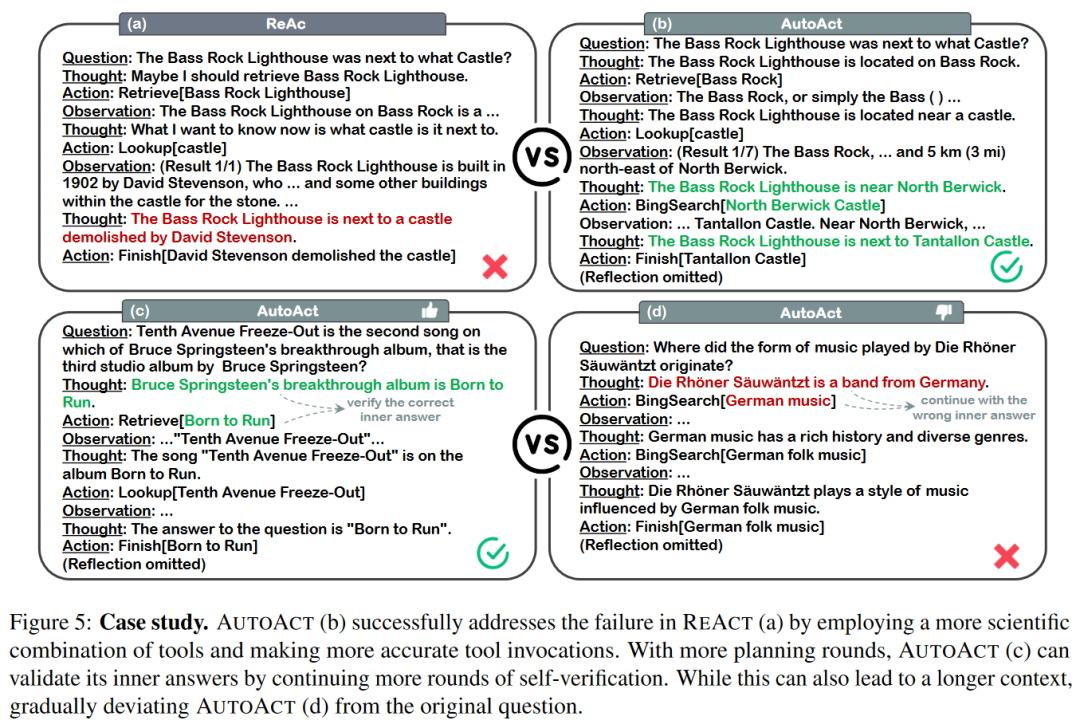
此外,案例研究的实验也说明,AUTOACT 用自分化的模式将规划与行动解耦,可以有效的提升 Agent 能力:
一点总结
图灵奖,也是诺贝尔经济学奖得主,人工智能的先驱人物,也是现代管理学的奠基人之一的 Herbert Simon 提出的有限理性原则:
由于人类目标的模糊性,其知识和信息的不完备性以及其推理判断能力的局限性,人类决策不可能简单地归结为某种目标函数优化的完美数学形式。
但是,除了有限理性以外,Simon 也认为:
精确的社会分工和明确的个人任务可以弥补个人处理和利用信息能力的有限性。
从这一点出发,面对复杂的任务,寻求使用一个单一智能体(哪怕是最强的 GPT-4)去解决任务之中的方方面面似乎都有一些强人所难。而这篇论文正是从这一点出发,将单一智能体的任务分解为三个子智能体分别优化,依赖精心设计的“分工模式”与“合作机制”,使得“三个臭皮匠,顶一个诸葛亮”。
此外,AUTOACT 完全不需要闭源模型辅助进行开源 Agent 微调的方法也将为基于开源模型的自动 Agent 学习打好基础铺平道路。在 AUTOACT 的基础上,也期待未来多智能体模式的基于开源模型的 AI Agent 可以不断百花齐放百家争鸣吧!