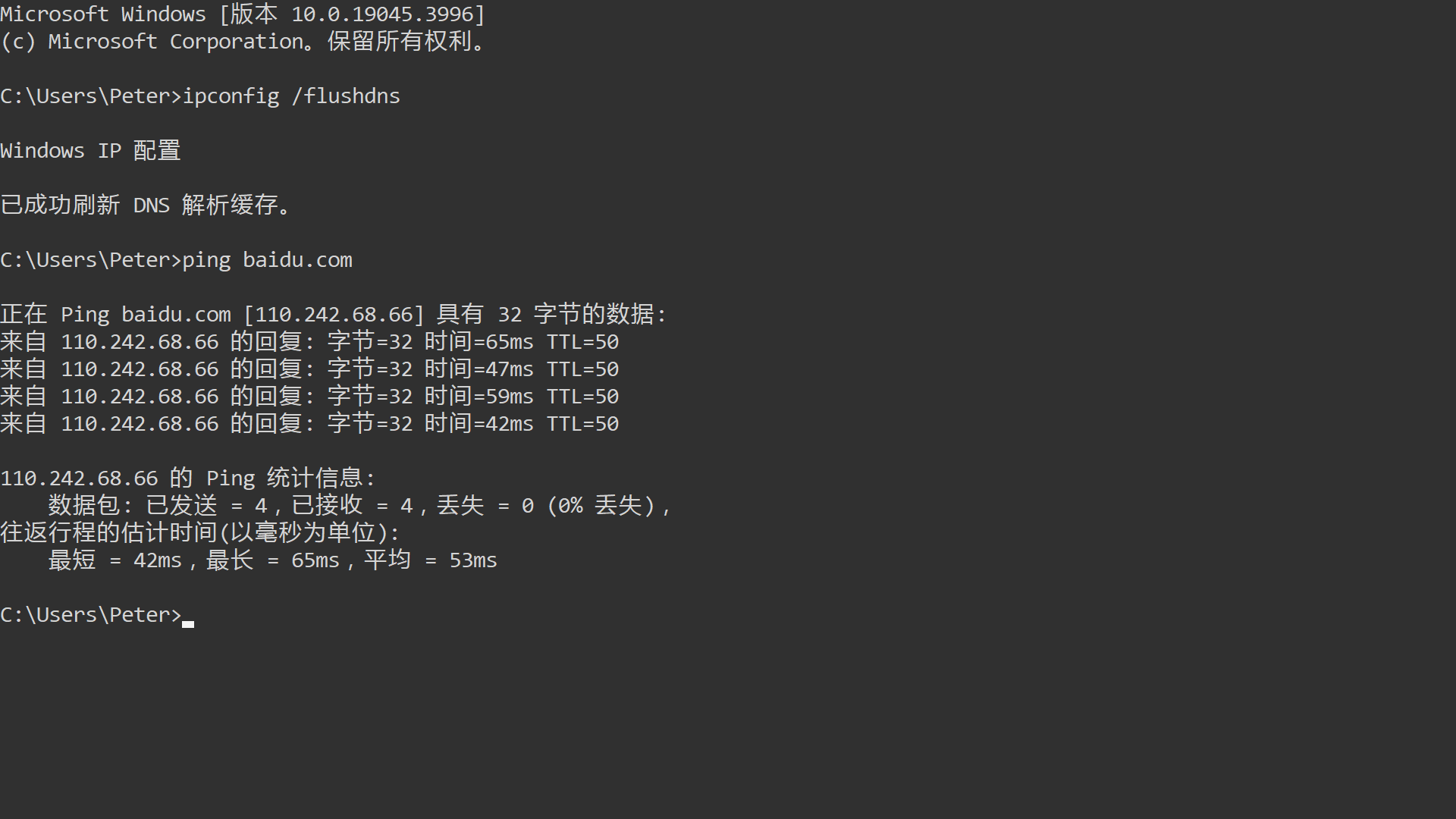
 1、node_cpu_seconds_total:监控项数据、指标项
1、node_cpu_seconds_total:监控项数据、指标项


2、node_cpu_seconds_total{cpu="0"}:时间序列
| node_cpu_seconds_total | 监控项数据(指标项) |
| {cpu="0"} | 标签 |
| node_cpu_seconds_total{cpu="0"}: node使用CPU的描述的统计,符合标签CPU=0的时间序列的查询结果 | |
3、标签
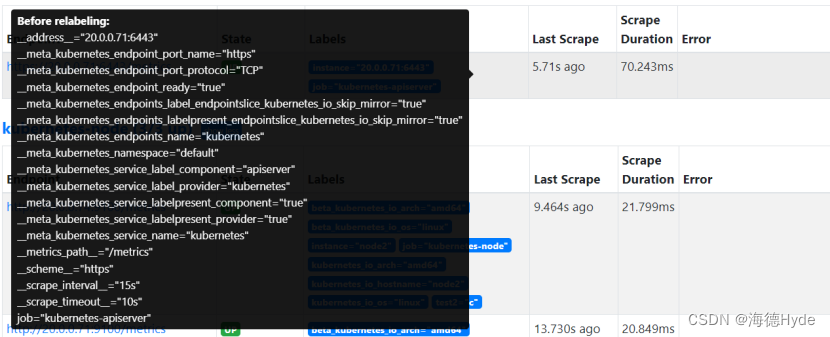
(1)__address__:双下划线标签,是Prometheus系统的默认标签,不显示在target页面当中,只有把光标移动到label的字段上,才能显示默认标签
4、过滤
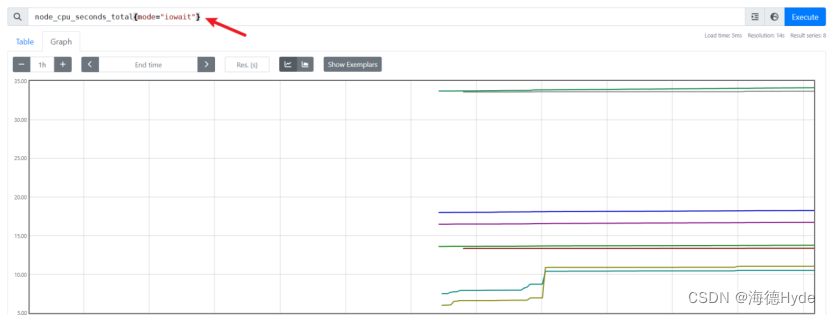
(1)node_cpu_seconds_total{mode="iowait"}
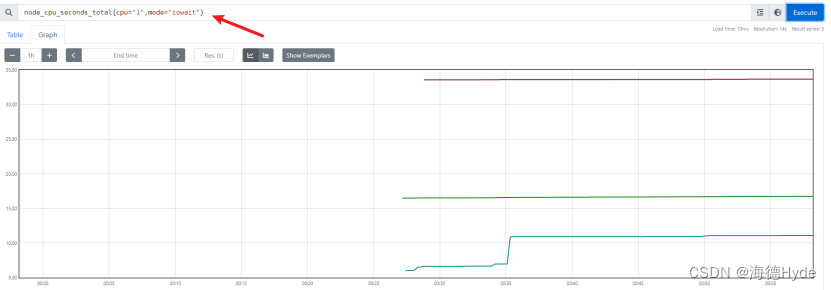
(2)node_cpu_seconds_total{cpu="1",mode="iowait"}
5、匹配标签值(操作符)
| = | 完全相等 |
| != | 不等于,相当于取反 |
| =~ | 正则表达式匹配 |
| !~ | 正则表达式取反 |
| 数学运算符 | |
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / | 除法 |
| % | 取余 |
| ^ | 幂运算 |
| 通配符 | |
| . | 任意单个字符 |
| .* | 多个任意字符 |
| .+ | 一个或者多个任意字符 |
(1)node_cpu_seconds_total{cpu!="1",mode=~"iowait"}


6、数据类型
| 瞬时向量 | 一组时序,每个时序只有一个采样值 | |
 | ||
| 区间向量 | 一组时序,每个时序包含一段时间内的多个采样值 | |
| rate(container_cpu_load_average_10s{instance="node1"}[5m]): 展示container_cpu_load_average_10s指标的过去每5分钟的采样值,对应的标签是node1 | ||
| 时长的单位类型 | ||
| s | seconds秒 | |
| m | minutes分 | |
| h | hour时 | |
| d | day日 | |
| w | weeks周 | |
| y | years年 | |
| 标量数据 | 浮点数 | |
| 字符串 | 一个字符串 | |
| counter | 总数,在promQL语句中没有直接作用,由rate、topk、increase、irate函数生成样本数据的变化情况 | |
| topk(3,node_cpu_seconds_total):展示前三位数据
| ||
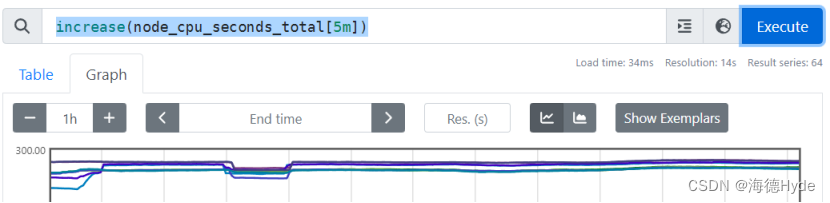
| increase:结合区间向量一起使用,表示时间序列在一定范围内的增量 increase(node_cpu_seconds_total[5m]):展示数据在5分钟内的增量
| ||
| irate:高灵敏度的函数,计算指标的瞬时速率,基于样本范围内的最后两个样本数据进行计算(相比),更适用于短时间内的变化速率分析,结合区间向量一起使用 irate(node_cpu_seconds_total[5m]):5分钟内的瞬时变化速率
| ||
| 大部分以total结尾的都是counter类型 | ||
| gauge | 用于存储值、可增可减的指标样本数据,求和、求平均数、取最小值和最大值,也会结合函数delta和predict_linear一起使用 | |
| delta:用于计算范围向量中的每个时间序列元素的第一个值和最后一个值之间的差,展示不同时间上样本值的差值 delta(container_memory_cache{instance="node1"}[5m])
| ||
| predict_linear:可以预测时间序列在V点、在T秒之后的变化趋势,是对样本数据的变化数据做出预测 predict_linear(node_filesystem_files{instance="master"}[2h],4*3600): node_filesystem_files:计算node节点上的文件数,选择的标签是master,过去两小时,4*3600未来4个小时。统计过去两个小时样本数据的变化,根据过去两个小时的数据变化预测未来4个小时的数据变化
| ||
| histogram | 对一定时间范围内的数据进行采样,通常是请求持续的时长和响应大小的类型这一类,计入一个可配的桶(bucket),通过区间对样本进行筛选,也可以统计求和 | |
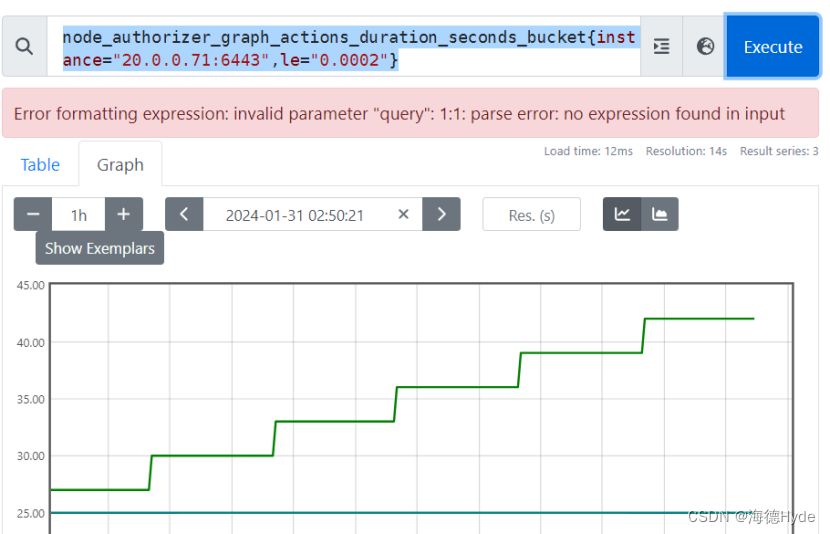
| node_authorizer_graph_actions_duration_seconds_bucket{instance="20.0.0.71:6443",le="0.0002"}:观测桶的上边界,样本的统计区间,表示所有的样本值小于等于上边界值的所有样本数量
| ||
| node_authorizer_graph_actions_duration_seconds_bucket{instance="20.0.0.71:6443",le="+Inf"}:最大区间,包含的所有样本数量 | ||
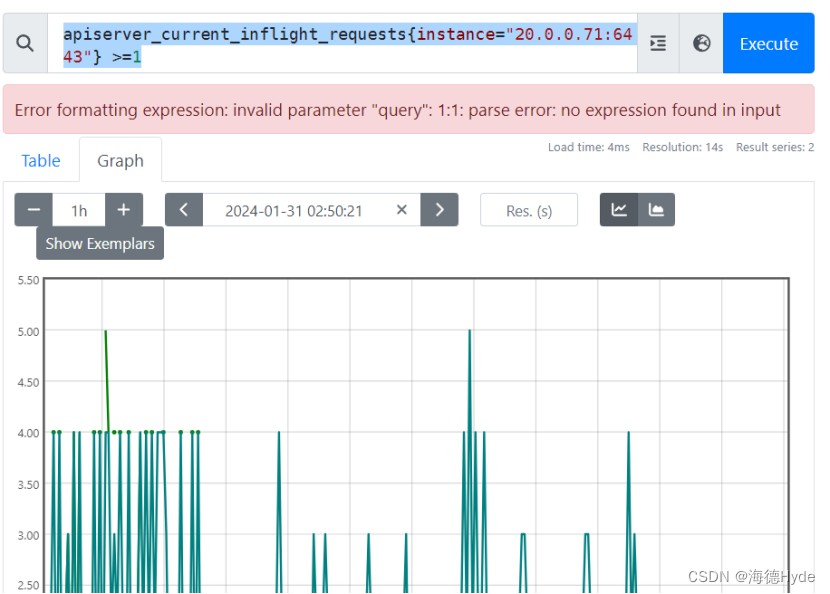
| apiserver_current_inflight_requests{instance="20.0.0.71:6443"} >=1:快速的了解监控样本的分布情况
| ||
| summary | 分位数计算、类似于histogram,在客户端于一段时间内(默认是10分钟)的每个采样点进行统计,计算并且存储了分位数的值,服务端可以直接抓取响应的值 | |
| quantile="0.5",0——1的范围内,围绕中位数0.5进行比较 | ||


7、聚合操作符
| sum | 求和 |
| sum(container_cpu_usage_seconds_total) | |
| min | 最小值 |
| min(container_cpu_usage_seconds_total) | |
| max | 最大值 |
| max(container_cpu_usage_seconds_total) | |
| avg | 平均值 |
| avg(container_cpu_usage_seconds_total) | |
| stddev | 标准差 |
| stdvar | 方差 |
| count | 元素个数 |
| count(container_cpu_usage_seconds_total) | |
| count_values | 等于某个值的元素个数 |
| topk | 最大的元素的个数 |
| topk(3,container_cpu_usage_seconds_total) | |
| bottomk | 最小的元素的个数 |
| bottomk(3,container_cpu_usage_seconds_total):取前三个最小的元素个数 | |
| topk和bottomk,需要带入数值,数值表示的是取前几位还是后几位 | |
| quantile | 分位数 |
| quantile(0.65,container_cpu_usage_seconds_total) | |
8、promQL语句的业务中使用
(1)计算某个节点的所有容器的使用内存的时间序列:单位GB
sum(container_memory_usage_bytes{instance="node1"})/1024/1024/1024

(2)某个节点最近1分钟内所有容器使用CPU的情况
sum(rate(container_cpu_usage_seconds_total{instance="node1"}[1m]))
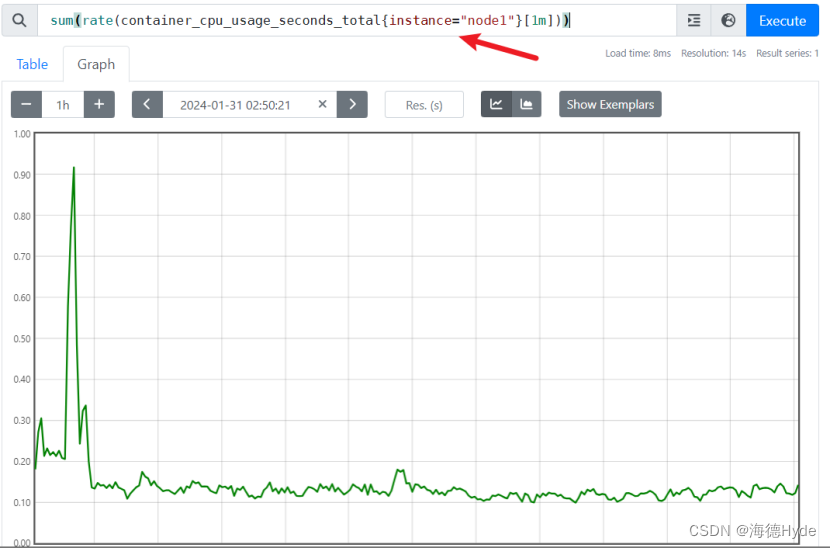
(3)最近一分钟所有容器的使用率:
sum by (id )(rate(container_cpu_usage_seconds_total{id!="/"}[1m]))

(4)查询k8s集群中最近1分钟每个pod的CPU使用率:
sum by (name)(rate(container_cpu_usage_seconds_total{image!="",name!=""}[1m]))
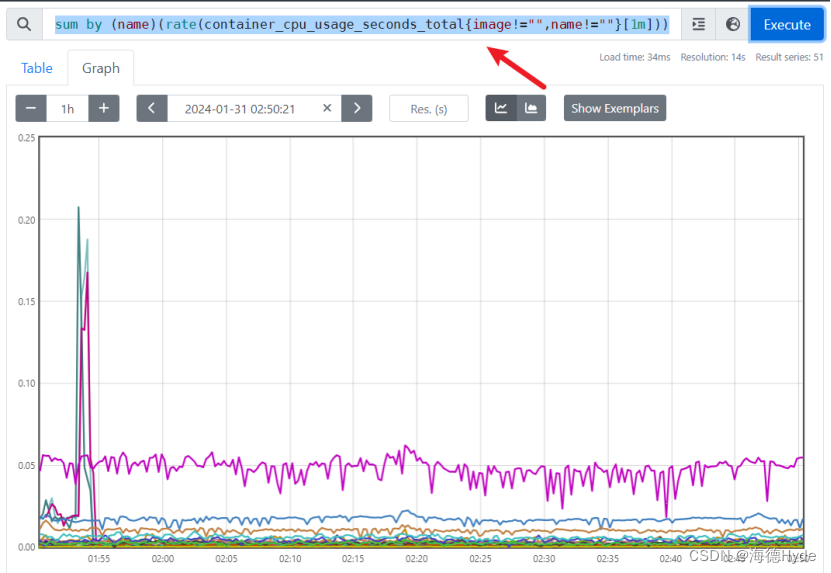
| 计算 master01 节点所有容器总计内存: sum(container_memory_usage_bytes{instance=~"master01"})/1024/1024/1024 |
| 计算 master01 节点最近 1m 所有容器 cpu 使用率: sum (rate (container_cpu_usage_seconds_total{instance=~"master01"}[1m])) / sum (machine_cpu_cores{ instance =~"master01"}) * 100 |
| 计算最近 1m 所有容器 cpu 使用率 sum by (id)(rate (container_cpu_usage_seconds_total{id!="/"}[1m])) |
| 查询 K8S 集群中最近 1m 每个 Pod 的 CPU 使用率 sum by (name)(rate (container_cpu_usage_seconds_total{image!="", name!=""}[1m])) |
| 每台主机 CPU 在最近 5 分钟内的平均使用率 (1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) * 100 |
| 查询 1 分钟的 load average 的时间序列是否超过主机 CPU 数量 2 倍 node_load1 > on (instance) 2 * count (node_cpu_seconds_total{mode="idle"}) by (instance) |
| 计算主机内存使用率可用内存空间:空闲内存、buffer、cache 指标之和 node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes |
| 已用内存空间:总内存空间减去可用空间 node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) |
| 使用率:已用空间除以总空间 (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 |
| 计算所有 node 节点所有容器总计内存: sum by (instance) (container_memory_usage_bytes{instance=~"node*"})/1024/1024/1024 |
| 计算 node01 节点最近 1m 所有容器 cpu 使用率: sum (rate(container_cpu_usage_seconds_total{instance="node01"}[1m])) / sum (machine_cpu_cores{instance="node01"}) * 100 #container_cpu_usage_seconds_total 代表容器占用CPU的时间总和 |
| 计算最近 5m 每个容器 cpu 使用情况变化率 sum (rate(container_cpu_usage_seconds_total[5m])) by (container_name) |
| 查询 K8S 集群中最近 1m 每个 Pod 的 CPU 使用情况变化率 sum (rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m])) by (pod_name) #由于查询到的数据都是容器相关的,所以最好按照 Pod 分组聚 |