背景
从保护原创说起
作为一个原创技术文章分享博主,日常除了Codeing就是总结Codeing中的技术经验。
之前并没有对文章原创性的保护意识,直到在某个非入驻的平台看到了我的文章,才意识到,辛苦码字、为灵感反复试验创作出来的文章,被别人轻轻松松的用爬虫就爬走了。

除了原创保护的困扰,还在工作中遇到过类似的爬虫困扰。比如之前做的一个商品的榜单,也是遭到了大量爬虫的恶意爬取,未经授权使用我们的数据,且占用我们的带宽。
反爬虫的Plan A 和 Plan B
Plan A:自制反爬虫策略
之前借鉴过别人的反爬虫策略,比如SVG映射、数字映射、IP限制等。
奋码疾敲了很久,将主流的反爬虫策略实现了一遍,结果,还是有爬虫能跳过这些机制。
费事费力费心神,结果收效审问。
Plan B :Web应用防火墙
既然我们的电脑有防火墙,帮助产生一道保护屏障,那么Web应用是不是也可以通过防火墙隔离爬虫的爬取呢?
我找了一下,发现华为云还真的提供了此类防护——WAF。
于是我果断选择了Plan B,也不由感慨一句:
华为云了解越多,技术之路走的越宽。
WAF
初步了解
WAF是Web应用防火墙的缩写,是华为云提供的对网站业务流量进行多维度检测和防护。
Web应用防火墙(Web Application Firewall, WAF),通过对HTTP(S)请求进行检测,识别并阻断SQL注入、跨站脚本攻击、网页木马上传、命令/代码注入、文件包含、敏感文件访问、第三方应用漏洞攻击、CC攻击、恶意爬虫扫描、跨站请求伪造等攻击,保护Web服务安全稳定。
深入了解
仔细研究了一下WAF的产品优势和使用场景,发现除了我目前比较需要的防爬虫的功能,其实WAF提供的大部分功能,作为一个前端开发者,都或多或少用的上。
比如防网页篡改,在刚入行的时候,就学习过如何预防xss攻击和CSRF攻击。
再比如秒杀防护,对于电商类网站,十分友好。我们现在做活动,每次都会进行压测。
此外,WAF还提供了内容安全检测功能,可以帮助减少人为的疏忽。
这样一来,使用WAF,相当于用了一份的成本精力,同时获得了多份的防护。
想要进一步了解WAF,可查看官方介绍。
反爬虫防护策略配置实战
前置条件
域名接入WAF
防护策略配置前,需要将域名接入WAF。具体的接入步骤,可以按照《添加防护域名(云模式)》提供的流程,写的很详细。

JS脚本反爬虫条件列表
在添加排除请求规则时,需要添加条件列表。

以下为添加条件列表的参数说明,可以结合参数说明,根据实际需求设计条件列表。
| 参数 | 参数说明 | 示例 |
| 规则名称 | 自定义规则名称。 | waf |
| 规则描述 | 可选参数,设置该规则的备注信息。 | - |
| 生效时间 | 立即生效。 | 立即生效 |
| 条件列表 | 条件设置参数说明如下:
创建引用表的详细操作请参见创建引用表。 | “路径”包含“/admin/” |
| 优先级 | 设置该条件规则检测的顺序值。如果您设置了多条规则,则多条规则间有先后匹配顺序,即访问请求将根据您设定的优先级依次进行匹配,优先级较小的规则优先匹配。 | 5 |
我目前需要的条件列表如下:
| 规则名称 | 生效时间 | 条件列表 | 优先级 |
| fpc | 立即生效 | 路径:/activity | 5 |
策略配置步骤
这里我参照了文档《通过配置反爬虫防护策略阻止爬虫攻击》进行配置。
主要分为三个步骤:
1、开启Robot检测
2、开启网站反爬虫
3、配置CC攻击防护
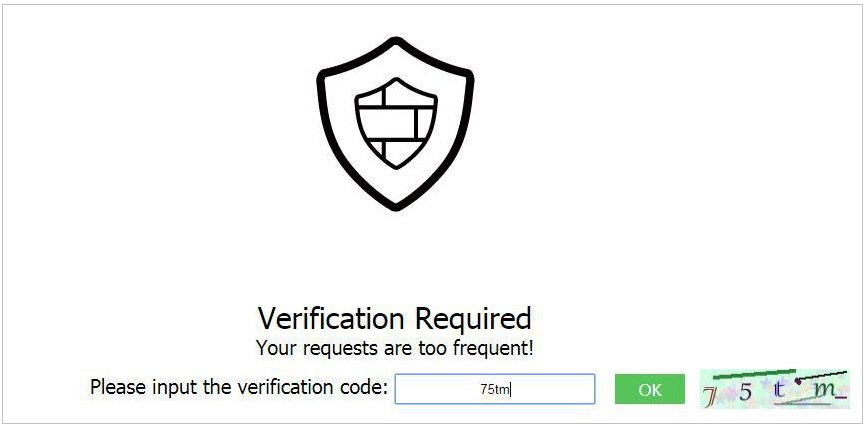
配置完成之后,可以自测一下。
当访问超过限制后需要输入验证码才能继续访问。
总结
WAF我目前只体验了反爬虫防护策略配置,配置流程很简单。主要是前置的域名接入WAF稍微有点复杂,不过接入成功,就可以开启后续的多重体验了。
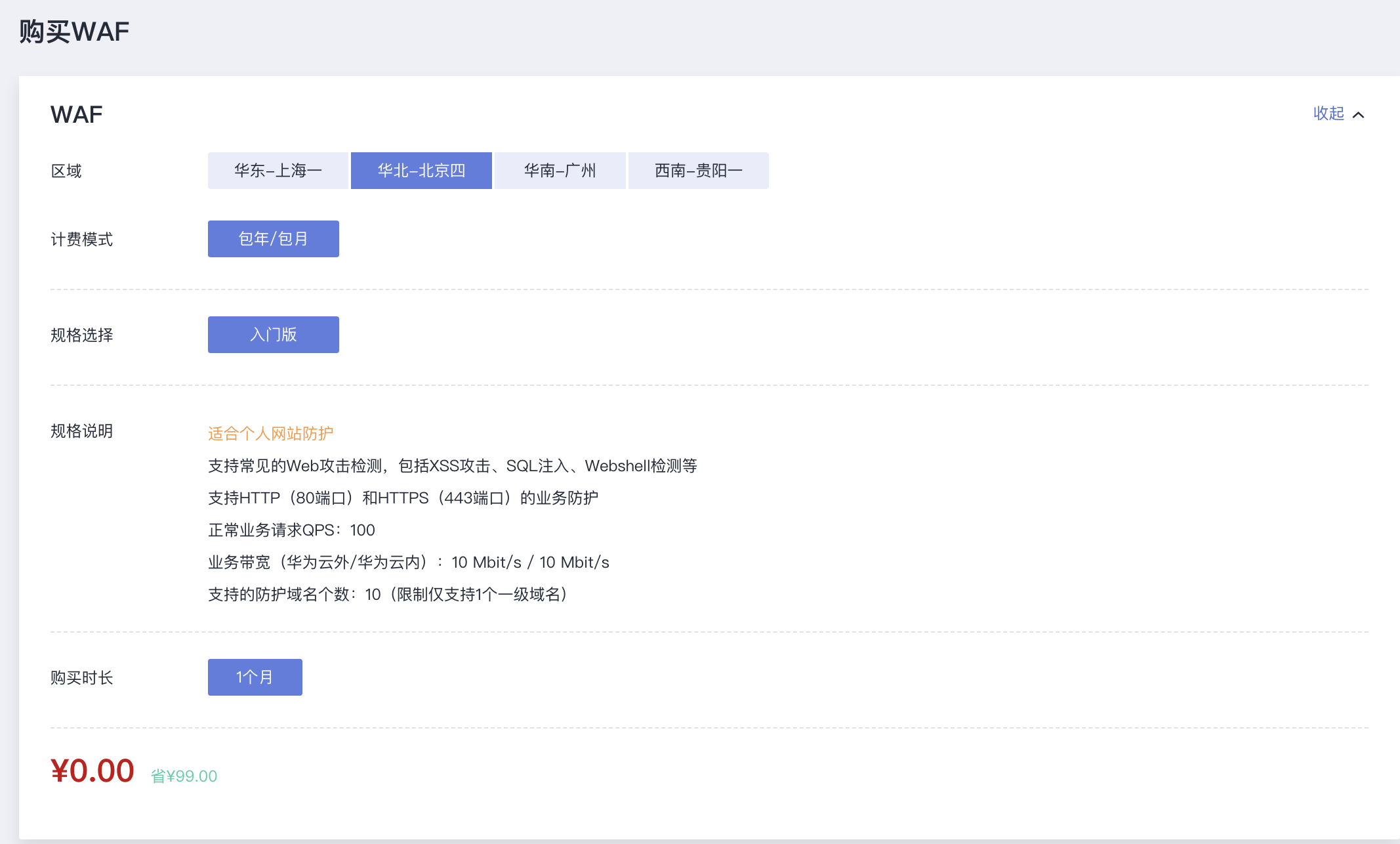
此外,WAF入门版支持免费体验一个月,对于还处于探索阶段的开发者,用于前期技术调研,十分的友好。

作者简介:
非职业「传道授业解惑」的开发者叶一一。
「趣学前端」、「CSS畅想」系列作者,华夏美食、国漫、古风重度爱好者,刑侦、无限流小说初级玩家。如果看完文章有所收获,欢迎点赞👍 | 收藏⭐️ | 留言📝。