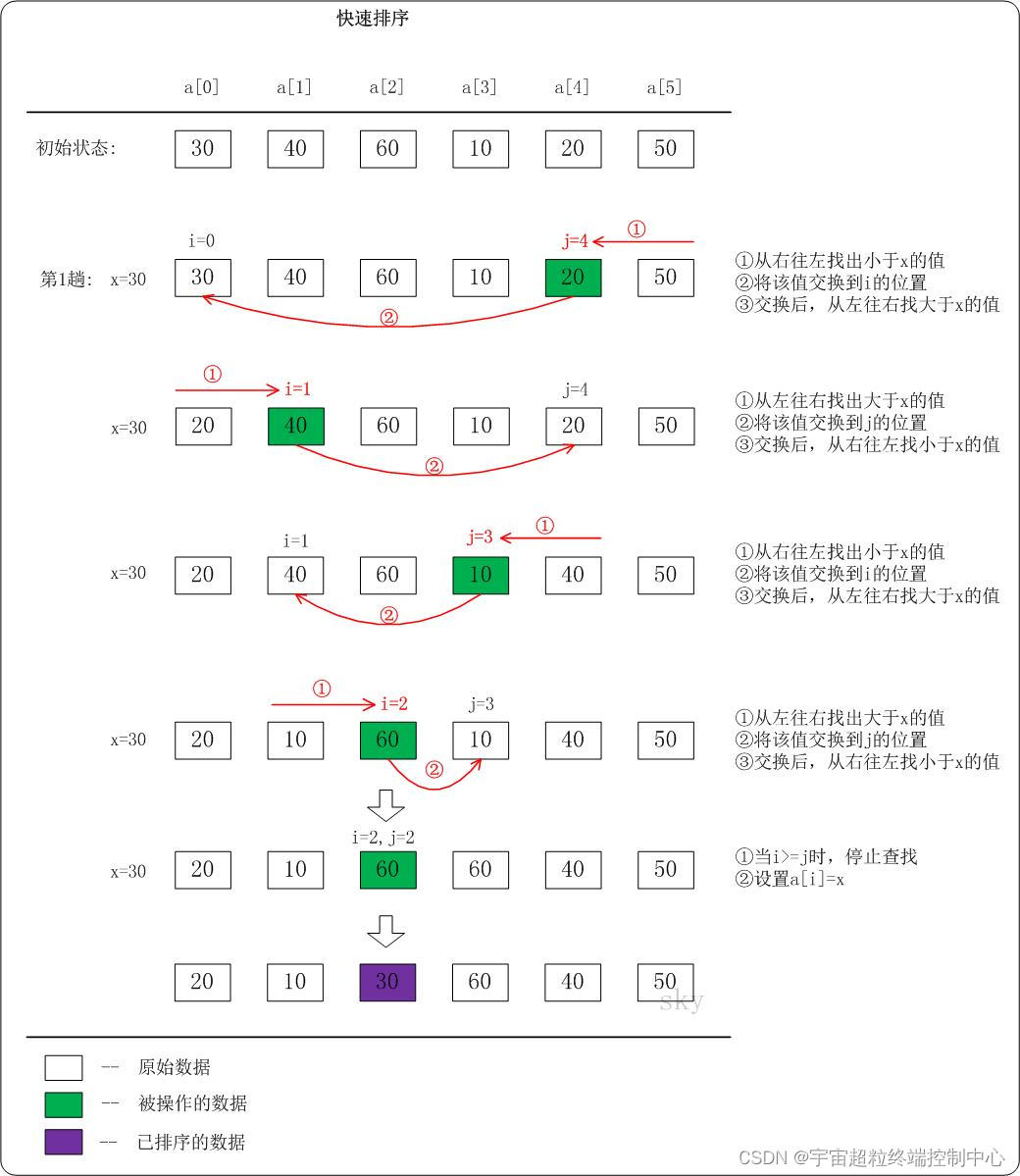
本文首发于公众号:机器感知
Single-Head ViT;Faster Whisper;Transformer KF;Pick-and-Draw
SHViT: Single-Head Vision Transformer with Memory Efficient Macro Design
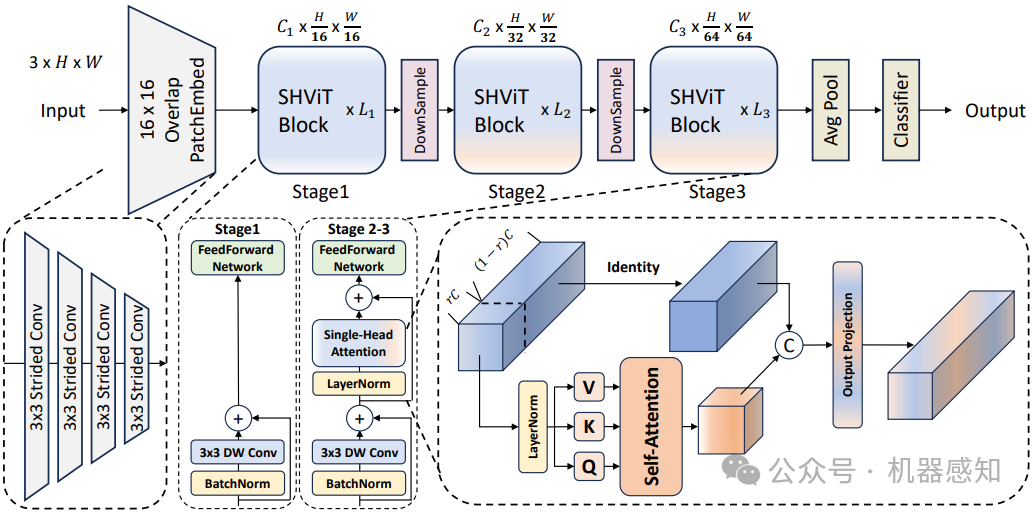
Recently, efficient Vision Transformers have shown great performance with low latency on resource-constrained devices. Conventionally, they use 4x4 patch embeddings and a 4-stage structure at the macro level, while utilizing sophisticated attention with multi-head configuration at the micro level. This paper aims to address computational redundancy at all design levels in a memory-efficient manner. We discover that using larger-stride patchify stem not only reduces memory access costs but also achieves competitive performance by leveraging token representations with reduced spatial redundancy from the early stages. Furthermore, our preliminary analyses suggest that attention layers in the early stages can be substituted with convolutions, and several attention heads in the latter stages are computationally redundant. To handle this, we introduce a single-head attention module that inherently prevents head redundancy and simultaneously boosts accuracy by parallelly combining global and local information. Building upon our solutions, we introduce SHViT, a Single-Head Vision Transformer that obtains the state-of-the-art speed-accuracy tradeoff. For example, on ImageNet-1k, our SHViT-S4 is 3.3x, 8.1x, and 2.4x faster than MobileViTv2 x1.0 on GPU, CPU, and iPhone12 mobile device, respectively, while being 1.3% more accurate. For object detection and instance segmentation on MS COCO using Mask-RCNN head, our model achieves performance comparable to FastViT-SA12 while exhibiting 3.8x and 2.0x lower backbone latency on GPU and mobile device, respectively.
OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
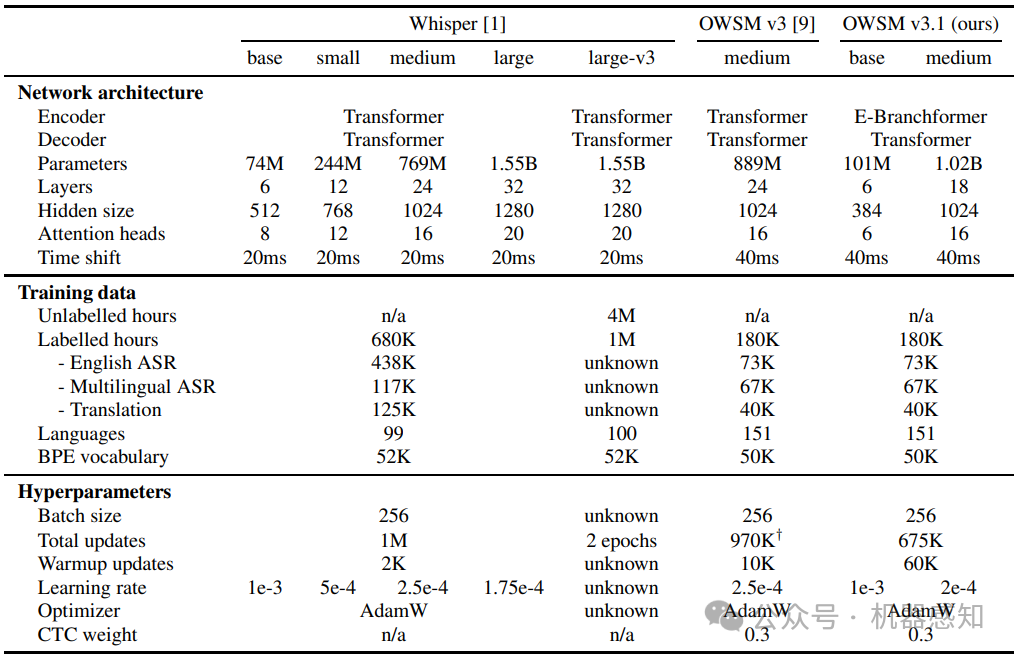
Recent studies have advocated for fully open foundation models to promote transparency and open science. As an initial step, the Open Whisper-style Speech Model (OWSM) reproduced OpenAI's Whisper using publicly available data and open-source toolkits. With the aim of reproducing Whisper, the previous OWSM v1 through v3 models were still based on Transformer, which might lead to inferior performance compared to other state-of-the-art speech encoders. In this work, we aim to improve the performance and efficiency of OWSM without extra training data. We present E-Branchformer based OWSM v3.1 models at two scales, i.e., 100M and 1B. The 1B model is the largest E-Branchformer based speech model that has been made publicly available. It outperforms the previous OWSM v3 in a vast majority of evaluation benchmarks, while demonstrating up to 25% faster inference speed.
OptiState: State Estimation of Legged Robots using Gated Networks with Transformer-based Vision and Kalman Filtering

State estimation for legged robots is challenging due to their highly dynamic motion and limitations imposed by sensor accuracy. By integrating Kalman filtering, optimization, and learning-based modalities, we propose a hybrid solution that combines proprioception and exteroceptive information for estimating the state of the robot's trunk. Leveraging joint encoder and IMU measurements, our Kalman filter is enhanced through a single-rigid body model that incorporates ground reaction force control outputs from convex Model Predictive Control optimization. The estimation is further refined through Gated Recurrent Units, which also considers semantic insights and robot height from a Vision Transformer autoencoder applied on depth images. This framework not only furnishes accurate robot state estimates, including uncertainty evaluations, but can minimize the nonlinear errors that arise from sensor measurements and model simplifications through learning. The proposed methodology is evaluated in hardware using a quadruped robot on various terrains, yielding a 65% improvement on the Root Mean Squared Error compared to our VIO SLAM baseline. Code example: https://github.com/AlexS28/OptiState
Pick-and-Draw: Training-free Semantic Guidance for Text-to-Image Personalization

Diffusion-based text-to-image personalization have achieved great success in generating subjects specified by users among various contexts. Even though, existing finetuning-based methods still suffer from model overfitting, which greatly harms the generative diversity, especially when given subject images are few. To this end, we propose Pick-and-Draw, a training-free semantic guidance approach to boost identity consistency and generative diversity for personalization methods. Our approach consists of two components: appearance picking guidance and layout drawing guidance. As for the former, we construct an appearance palette with visual features from the reference image, where we pick local patterns for generating the specified subject with consistent identity. As for layout drawing, we outline the subject's contour by referring to a generative template from the vanilla diffusion model, and inherit the strong image prior to synthesize diverse contexts according to different text conditions. The proposed approach can be applied to any personalized diffusion models and requires as few as a single reference image.
BoostDream: Efficient Refining for High-Quality Text-to-3D Generation from Multi-View Diffusion

Witnessing the evolution of text-to-image diffusion models, significant strides have been made in text-to-3D generation. Currently, two primary paradigms dominate the field of text-to-3D: the feed-forward generation solutions, capable of swiftly producing 3D assets but often yielding coarse results, and the Score Distillation Sampling (SDS) based solutions, known for generating high-fidelity 3D assets albeit at a slower pace. The synergistic integration of these methods holds substantial promise for advancing 3D generation techniques. In this paper, we present BoostDream, a highly efficient plug-and-play 3D refining method designed to transform coarse 3D assets into high-quality. The BoostDream framework comprises three distinct processes: (1) We introduce 3D model distillation that fits differentiable representations from the 3D assets obtained through feed-forward generation. (2) A novel multi-view SDS loss is designed, which utilizes a multi-view aware 2D diffusion model to refine the 3D assets. (3) We propose to use prompt and multi-view consistent normal maps as guidance in refinement.Our extensive experiment is conducted on different differentiable 3D representations, revealing that BoostDream excels in generating high-quality 3D assets rapidly, overcoming the Janus problem compared to conventional SDS-based methods.