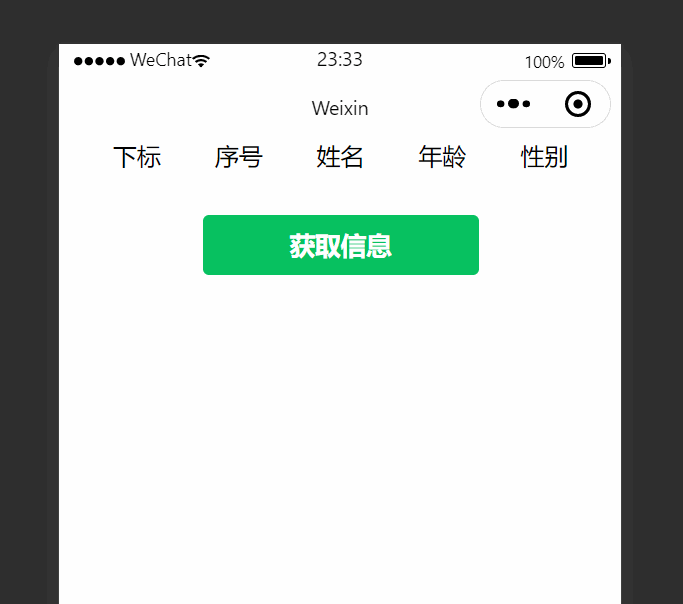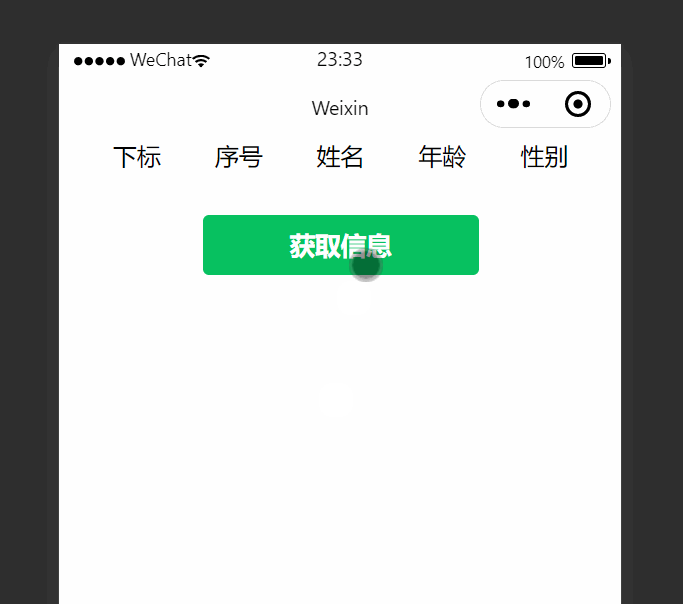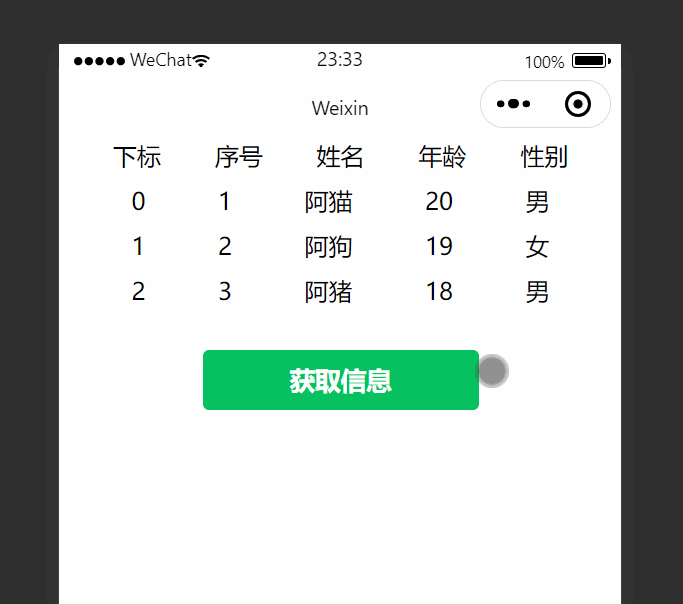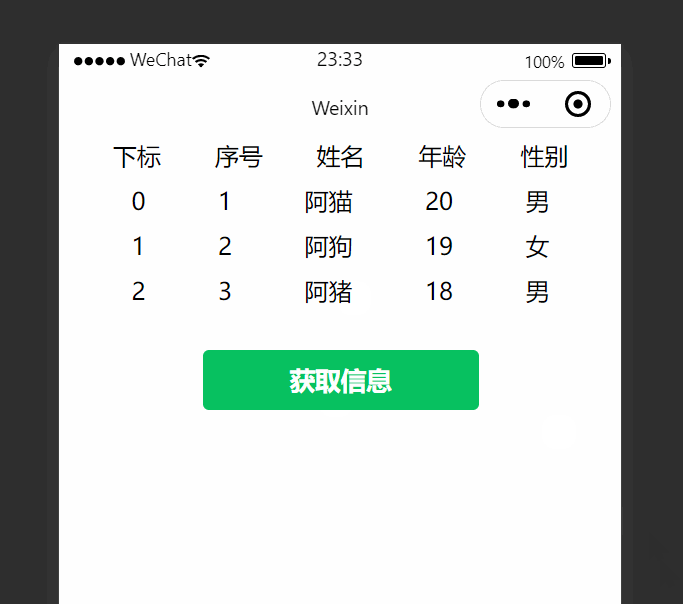
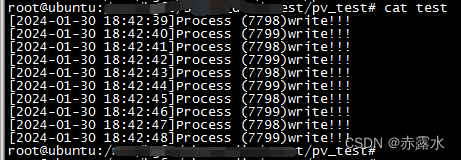
网址:https://movie.douban.com/
import requests
from lxml import etree
import re
url = 'https://movie.douban.com'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36'
}
session = requests.session()
response = session.get(url,headers = headers)
# response.encoding='utf-8'
# response.encoding = response.apparent_encoding
index_url = 'https://movie.douban.com'
res = session.get(index_url,headers=headers)
# print(res.text)
# 输出:页面源代码
tree = etree.HTML(res.text)
# print(tree)
# 输出:<Element html at 0x186fa6a3100>
img_all = tree.xpath('//img')
# print(img_all)
for i in img_all:
img = etree.tostring(i, encoding='UTF-8').decode('UTF-8')
# 得到所有的img标签
# print(img)
# <img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2900931370.jpg" alt="小行星猎人" rel="nofollow" class=""/>
img_url = tree.xpath('//img/@src')
# img_name = tree.xpath('//img/@alt')
# print(img_url,img_name)
# 输出:许多个列表
for i in img_url:
# print(i)
last_str = i.split('/')[-1]
# print(last_str)
# 输出:多个p2900931370.jpg p2901057189.jpg
every_name = last_str.split('.')[0]
# print(every_name)
# 输出:多个p2900931370 p2901057189
res_url = session.get(i,headers=headers)
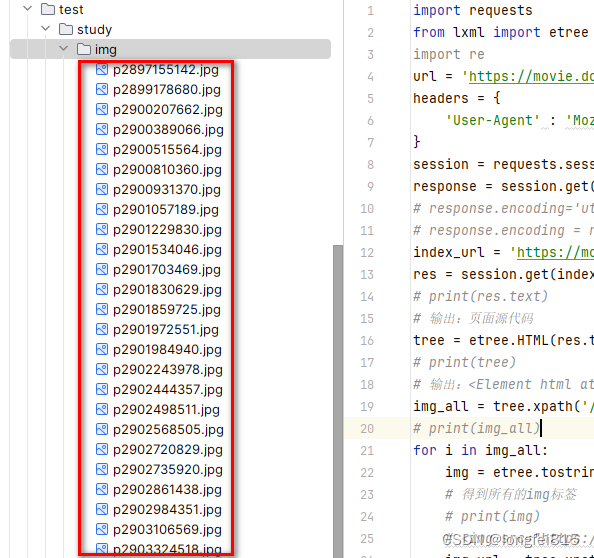
with open(f'./img/{every_name}.jpg','wb') as f:
f.write(res_url.content)运行结果:





![[Mac软件]Amadeus Pro 2.8.13 (2662) Beta多轨音频编辑器激活版](https://img-blog.csdnimg.cn/img_convert/099f5a4bbcf428030966f1f6751f1400.png)