一、无监督学习介绍
在这小节中,我将开始介绍聚类算法,这是我们学习的第一个非监督学习算法,我们将要让计算机学习无标签数据而不是此前的标签数据。那么什么是非监督学习呢?在学习机器学习知识的开始我曾简单地介绍过非监督学习,然而我还是有必要将其与监督学习做一下比较。
在一个典型的监督学习中我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,我们有一系列标签并且我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中我们的数据没有附带任何标签,我们拿到的数据就是这样的:

在这里我们有一系列点却没有标签,因此我们的训练集可以写成只有,我们没有任何标签y,因此图上画的这些点没有标签信息。也就是说,在非监督学习中,我们需要将一系列无标签的训练数据输入到一个算法中,然后我们告诉这个算法为我们找找这个数据的内在结构。图上的数据看起来可以分成两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
这将是我介绍的第一个非监督学习算法,此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式而不只是簇。我将先介绍聚类算法。此后,我将陆续介绍其他算法。那么聚类算法一般用来做什么呢?

在早些时候我曾经列举过一些应用:①市场分割:也许你在数据库中存储了许多客户的信息,而你希望将他们分成不同的客户群,这样你可以对不同类型的客户分别销售产品或者分别提供更适合的服务。②社交网络分析:事实上有许多研究人员正在研究这样一些内容,他们关注一群人的社交网络,比如说:他们经常跟哪些人联系,而这些人又经常给哪些人发邮件,由此找到关系密切的人群。③组织计算机集群或者更好的管理数据中心,因为如果你知道数据中心中哪些计算机经常协作工作,那么你可以重新分配资源、重新布局网络,由此优化数据中心、优化数据通信。④了解星系的形成,从而探索一些天文学上的细节问题。
二、K-均值算法
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。同时K-均值是一个迭代算法,假设我们想要将数据聚类成N个组,其方法为:、
①首先选择K个随机的点,称为聚类中心(cluster centroids)
②对于数据集中的每一个数据,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类
③计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置
④重复步骤②-③直至中心点不再变化
下面是一个聚类示例:
迭代一次

迭代三次

迭代十次


Repeat {
for i = 1 to m
c(i) := index (form 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk := average (mean) of points assigned to cluster k
}
算法分为两个步骤,第一个for循环是赋值步骤,即:对于每一个样例i,计算其应该属于的类;第二个for循环是聚类中心的移动,即:对于每一个类k,重新计算该类的质心。
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组群的情况下也可以。下图所示的数据集包含身高和体重两项特征构成的,利用K-均值算法将数据分为三类,用于帮助确定将要生产的T-恤衫的三种尺寸。

三、优化目标
K-均值最小化问题是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:

其中代表与
最近的聚类中心点,我们的的优化目标是找出使得代价函数最小的
和
:
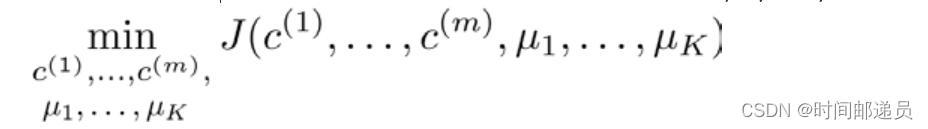
回顾刚才给出的K-均值迭代算法,我们知道:第一个循环是用于减小引起的代价,而第二个循环则是用于减小
引起的代价,迭代的过程一定会是每一次迭代都在减小代价函数,不然便是出现了错误。
四、随机初始化
在运行K-均值算法之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样做:
我们应该选择K<m,即聚类中心点的个数要小于所有训练集实例的数量
随机选择K个训练实例,然后令K个聚类中心分别与这K个训练实例相等
K-均值的一个问题在于它有可能会停留在一个局部最小值处,而这取决于初始化的情况。

为了解决这个问题我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果,这种方法在K较小的时候(2-10)还是可行的,但是如果K较大,这么做也可能不会明显地改善。
五、选择聚类数
其实并没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题人工进行选择的。最好的做法是:选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的聚类数。当我们在讨论选择聚类数目的方法时,有一个方法叫作“肘部法则”。关于“肘部法则”,我们所需要做的是改变K值,也就是聚类类别数目的总数。我们用一个聚类来运行K均值聚类方法,这就意味着所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数J。
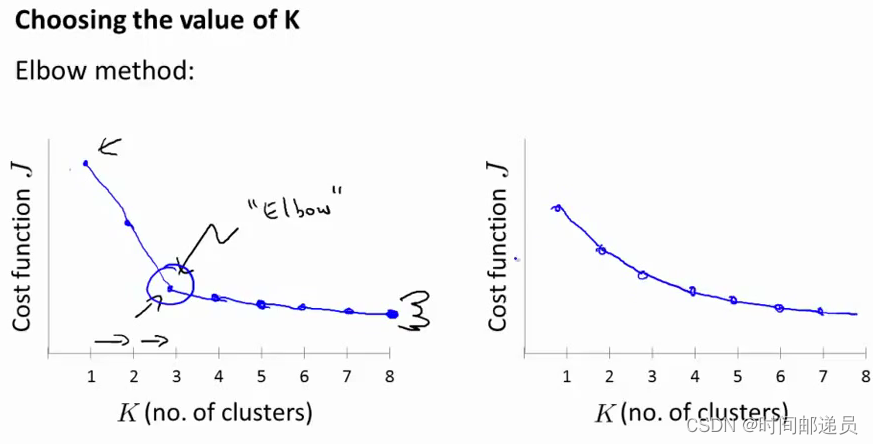
我们可能会得到一条类似于上图左边这样的曲线,像一个人的肘部,这就是“肘部法则”所做的,你会发现这种模式下它的畸变值会迅速下降,从1到2、从2到3之后,你会在3的时候达到一个肘点。在此之后,畸变值就下降的非常慢,看起来就像使用3个聚类来进行聚类是正确的,那么我们就选K=3。但是如果出现了右边这样的情况,你会发现曲线一直在很快地下降,感觉4,5,6,7这几个点都行,那么肘部法则这时候就变得不那么适用了。
因此最好的方法是:选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的聚类数。例如,我们的 T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成3个尺寸:S,M,L,也可以分成5个尺寸XS,S,M,L,XL,这样的选择是建立在回答“聚类后我们制造的T-恤是否能较好地适合我们的客户”这个问题的基础上作出的。



![【C++入门到精通】特殊类的设计 | 单例模式 [ C++入门 ]](https://img-blog.csdnimg.cn/direct/32ed20b44d704746a77da19b16d060e5.jpeg)