论文阅读|小目标分割算法ASF-YOLO
- 摘要(Abstract)
- 1 引言(Introduction)
- 2 相关工作(Related work)
- 2.1 细胞实例分割(Cell instance segmentation)
- 2.2 改进的YOLO用于实例分割(Improved YOLO for instance segmentation)
- 3 提出的ASF-YOLO(The proposed ASF-YOLO model)
- 3.1 总体框架(Overall architecture)
- 3.2 尺度序列特征融合模块(Scale sequence feature fusion module)
- 3.3 三重特征编码模块(Triple feature encoding module)
- 3.4 通道和位置注意力机制(Channel and position attention mechanism)
- 3.5 锚框优化(Anchor box optimization)
- 4 实验(Experiments)
- 4.1 数据集(Datasets)
- 4.2 实现细节(Implementation details)
- 4.3 定量结果(Quantitative results)
- 4.4 定性结果(Qualitative results)
- 4.5 消融研究(Ablation study)
- 4.5.1 提出方法的影响(Effect of the proposed methods)
- 4.5.2 注意力机制的影响(Effect of attention mechanisms)
- 4.5.3 骨干网络中卷积模块的影响(Effect of convolution module in the backbone)
- 5 总结
论文题目:ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation
论文链接: https://arxiv.org/abs/2312.06458
代码链接:https://github.com/mkang315/ASF-YOLO
摘要(Abstract)
作者提出了一种新颖的基于 “You Only Look Once”(YOLO)的注意力尺度序列融合框架(ASF-YOLO),该框架结合了空间和尺度特征,可实现准确、快速的细胞实例分割。在 YOLO 分割框架的基础上,采用尺度序列特征融合(SSFF)模块来增强网络的多尺度信息提取能力,并采用三重特征编码器(TPE)模块来融合不同尺度的特征图,以增加细节信息。进一步引入了通道和位置注意力机制(CPAM),将 SSFF 和 TPE 模块整合在一起,重点关注信息通道和与空间位置相关的小目标,以提高检测和分割性能。在两个细胞数据集上进行的实验验证表明,所提出的 ASF-YOLO 模型具有出色的分割精度和速度。它在 2018 Data Science Bowl 数据集上实现了 0.91 的边界框 mAP、0.887 的掩膜 mAP 和 47.3 FPS 的推理速度,优于最先进的方法。源代码见 https://github.com/mkang315/ASF-YOLO。
关键词:医学图像分析、小目标分割、You Only Look Once(YOLO)、序列特征融合、注意力机制
1 引言(Introduction)
随着样品制备技术和显微成像技术的快速发展,细胞图像的定量处理和分析在医学和细胞生物学等领域发挥着重要作用。基于卷积神经网络(Convolutional Neural Networks,CNN),可以通过神经网络训练学习不同细胞图像的特征信息,具有很强的泛化性能。两阶段 R-CNN 系列 [1, 2, 3] 及其单阶段变体 [4, 5] 是用于实例分割任务的基于 CNN 的经典框架。在最近的研究中,"You Only Look Once(YOLO)"系列 [6, 7, 8, 9] 已成为实时实例分割中最快、最准确的模型之一。与两阶段分割模型相比,YOLO 实例分割模型由于采用了单阶段设计思想和特征提取功能,因此具有更好的准确性和速度。然而,细胞实例分割的难点在于对象小、密集、重叠,以及细胞边界模糊,从而导致细胞分割的准确性较差。细胞实例分割需要对细胞图像中不同类型的物体进行精确细致的分割。如图 1 所示,由于细胞形态、制备方法和成像技术的不同,不同类型的细胞图像在颜色、形态、纹理和其他特征信息方面存在很大差异。

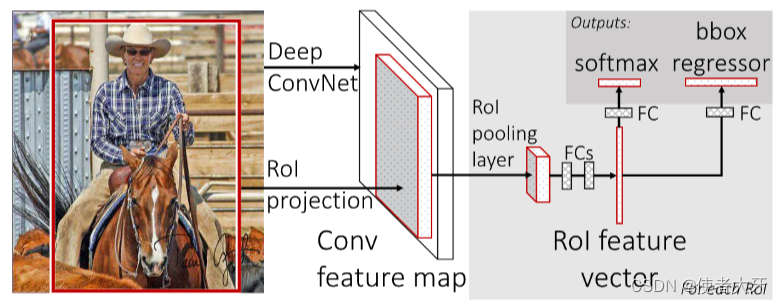
典型的 YOLO 框架结构由三个主要部分组成:骨干backbone、颈部neck和头部head。YOLO 的骨干网络是一个卷积神经网络,用于提取不同粒度的图像特征。具有 53 个卷积层的 Cross Stage Partial [10] Darknet(CSPDarknet53)[11] 是在 YOLOv4 [12] 的基础上修改的,被作为 YOLOv5 [8] 的骨干网络,包含 C3(CSP bottleneck 包括 3 个卷积层)和 ConvBNSiLU 模块。 YOLOv8[9]的骨干网络与 YOLOv5 唯一的不同之处,C3 模块被 C2f(CSP bottleneck 包括 2 个直连的卷积层)模块替代。如图 2 所示,YOLOv5 和 YOLOv8 主干网中的 1-5 级特征提取分支 P1、P2、P3、P4、P5 分别对应于与每个特征图相关的 YOLO 网络输出。YOLOv5 v7 和 YOLOv8 是首个基于 YOLO 的主流架构,除检测和分类外,还能处理分割任务。在 YOLOv5 的特征提取阶段,采用了由多个 C3 模块堆叠而成的 CSPDarkNet53 主干网络,然后将主干网络的三个有效特征分支 P3、P4 和 P5 作为特征金字塔网(FPN)结构的输入,在颈部建立多尺度融合结构。在特征层的解码过程中,与主干网络有效特征分支相对应的三个不同大小的头被用于物体的边界框预测。在对 P3 特征进行上采样后,逐像素解码作为目标的分割掩码预测,以完成目标的实例分割。在分割头中,三个尺度的特征输出三个不同的锚框,掩码原型模块负责输出原型掩码,经过处理后得到检测框和分割掩码,用于实例分割任务。

本文提出了一种细胞图像的单阶段实例分割模型ASF-YOLO,该模型将注意力尺度序列融合(Attentional Scale Sequence Fusion)融入了 You Only Look Once(YOLO)框架中。在特征提取阶段,首先使用 CSPDarknet53 骨干网络从细胞图像中提取多维特征信息。在颈部部分提出了用于细胞实例分割的新型网络设计。这项工作的贡献总结如下:
1)针对不同类型细胞的多尺度问题以及小细胞的目标检测和分割问题,设计了尺度序列特征融合(Scale Sequence Feature Fusion,SSFF)模块和三重特征编码器(Triple Feature Encoder,TFE)模块,在路径聚合网络(Path Aggregation Network,PANet)[13]结构中融合从主干网提取的多尺度特征图。
2)然后,设计了一个通道和位置注意力机制(Channel and Position Attention Mechanism,CPAM)来合并 SSFF 和 TFC 模块的特征信息,从而进一步提高实例分割的准确性。
3)在训练阶段,利用 EIoU [14]最小化边界框与锚点框的宽度和高度之差,以优化边界框位置损失,在后处理阶段,使用软非最大值抑制(Soft NonMaximum Suppression,Soft-NMS)[15] 来改善密集重叠细胞问题。
4)将提出的 ASF-YOLO 模型应用于高难度的密集重叠和各种细胞类型的实例分割任务。据作者描述,这是第一项利用基于 YOLO 模型进行细胞实例分割的工作。对两个基准细胞数据集的评估表明,与其他最先进的方法相比,该方法的检测精度和速度都更胜一筹。
2 相关工作(Related work)
2.1 细胞实例分割(Cell instance segmentation)
细胞实例分割可进一步帮助完成图像中的细胞计数任务,而细胞图像的语义分割则无法完成。深度学习方法提高了自动细胞核分割的准确性[16]。Johnson 等人[17]、Jung 等人[18]、Fujita 等人[19]和 Bancher 等人[20]提出了基于 Mask R-CNN [2]同时检测和分割细胞的改进方法。Yi 等人[21] 和 Cheng 等人[22] 利用单次多框检测器(Single-Shot multi-box Detector, SSD)[23] 方法检测和分割神经细胞实例。Mahbod 等人[24] 采用基于 U-Net [25] 模型的语义分割算法进行细胞核分割。带有注意力机制的 SSD 和 U-Net 混合模型[19]或 U-Net 和 Mask R-CNN 模型[26]在细胞实例分割数据集上取得了一定的提升。BlendMask [27] 是一种细胞核实例分割框架,带有扩张卷积聚合模块和上下文信息聚合模块。Mask R-CNN 是一种两阶段物体分割框架,速度较慢。SSD、U-Net 和 BlendMask 是统一的端到端(即单阶段)框架,但在分割密集细胞和小细胞时性能较差。
2.2 改进的YOLO用于实例分割(Improved YOLO for instance segmentation)
最近,针对实例分割任务对 YOLO 的改进主要集中在注意力机制、改进的骨干或网络以及损失函数上。挤压和激发(Squeeze-and-Excitation,SENet)[28] 块被集成到改进的 YOLACT[6] 中,用于识别显微图像中的瘤胃原生动物[29]。YOLOMask[30]、PR-YOLO[31]和YOLO-SF[32] 利用卷积块注意模块(CBAM)[34]增强了YOLOv5[8]和YOLOv7-Tiny[33]。改进后的主干网络中加入了有效的特征提取模块,使 YOLO 特征提取过程更加高效[35, 36]。YOLO-CORE [37]通过使用设计的多阶约束(由极距损失和扇形损失组成)进行显式直接轮廓回归,有效增强了实例的掩码。此外,另一种 YOLOMask [38] 和 YUSEG [39] 相结合的混合模型,将优化的 YOLOv4 [12] 和带有语义分割 U-Net 网络的原始 YOLOv5s ,以确保实例分割的准确性。
3 提出的ASF-YOLO(The proposed ASF-YOLO model)
3.1 总体框架(Overall architecture)

图 3 显示了提出的 ASF-YOLO 框架,该框架结合了空间和多尺度特征,用于细胞图像实例分割。作者开发了一种新颖的特征融合网络架构,由可以为小物体分割提供互补信息的两个主要组件网络组成:(1) SSFF 模块结合了来自多尺度图像的全局或高级语义信息;(2) TFE 模块可捕捉小目标物体的局部细节。局部和全局特征信息的融合可以生成更精确的分割图。作者对从骨干网络中提取的 P3、P4 和 P5 的输出特性进行了融合。首先,SSFF 模块旨在有效融合 P3、P4 和 P5 的特征图,以捕捉不同空间尺度、不同大小和形状的不同细胞类型。在 SSFF 中,P3、P4 和 P5 特征图被归一化为相同的大小,经过上采样,然后叠加在一起,作为三维卷积的输入,以结合多尺度特征。其次,作者开发了 TFE 模块,通过在空间维度上拼接大、中、小三种不同尺寸的特征来捕捉小目标的细节信息,从而增强对密集细胞小目标的检测。然后通过 PANet 结构将 TFE 模块的细节信息整合到每个特征分支中,再与 SSFF 模块的多尺度信息结合到 P3 分支中。还在 P3 分支中引入了通道和位置注意力机制(Channel and Position Attention Mechanism,CPAM),以充分利用高级多尺度特征和细节特征。CPAM 中的通道和位置注意力机制可分别捕获信息通道和细化与细胞等小物体相关的空间定位,从而提高其检测和分割精度。
3.2 尺度序列特征融合模块(Scale sequence feature fusion module)
针对细胞图像的多尺度问题,现有文献采用特征金字塔结构进行特征融合,其中只采用了和或并集来融合金字塔特征。然而,各种特征金字塔网络结构无法有效利用所有金字塔特征图之间的相关性。作者提出了一种新的尺度序列特征融合方法,它能更好地结合深度特征图的高维信息和浅层特征图的详细信息。尺度空间是沿着图像的尺度轴构建的,它不仅表示一个尺度,还表示一个物体可能具有的各种尺度的范围[40]。比例意味着图像的细节。模糊的图像可能会丢失细节,但图像的结构特征可以保留。作为 SSFF 输入的缩放图像可以通过以下方法获得
F
σ
(
w
,
h
)
=
G
σ
(
w
,
h
)
×
f
(
w
,
h
)
G
σ
(
w
,
h
)
=
1
2
π
σ
2
e
−
(
w
2
+
h
2
)
/
2
σ
2
\begin{aligned}F_\sigma(w,h)&=G_\sigma(w,h)\times f(w,h)\\G_\sigma(w,h)&=\frac1{2\pi\sigma^2}e^{-(w^2+h^2)/2\sigma^2}&\end{aligned}
Fσ(w,h)Gσ(w,h)=Gσ(w,h)×f(w,h)=2πσ21e−(w2+h2)/2σ2
其中,
f
(
w
,
h
)
f (w, h)
f(w,h) 表示宽度为
w
w
w、高度为
h
h
h 的二维输入图像。
F
σ
(
w
,
h
)
F_\sigma(w,h)
Fσ(w,h)通过使用二维高斯滤波器
G
σ
(
w
,
h
)
G_σ(w, h)
Gσ(w,h)的一系列卷积平滑生成,
σ
σ
σ 是用于卷积的二维高斯滤波器标准偏差的缩放参数。
这些生成的图像具有相同的分辨率,但尺度不同。因此,可以将不同大小的特征图视为尺度空间,将不同分辨率的有效特征图调整为相同分辨率进行拼接。受对多个视频帧进行二维和三维卷积操作[41]的启发,作者将不同尺度的特征图进行水平堆叠,并使用三维卷积提取其尺度序列特征。高分辨率特征图 P3 层包含了对小型目标的检测和分割至关重要的大部分信息,因此 SSFF 模块是基于 P3 层设计的。如图 3 所示,拟议的 SSFF 模块由以下部分组成:
- 使用 1×1 卷积层将 P4 和 P5 特征层的通道数改为 256。
- 使用近邻插值法 [42] 将其大小调整为 P3 层的大小。
- 使用取消挤压法(unsqueeze method)增加每个特征层的维度,将其从三维张量[高度、宽度、通道]变为四维张量[深度、高度、宽度、通道]。
- 然后沿深度维度将 4D 特征图串联起来,形成一个 3D 特征图,用于后续卷积。
- 最后,使用三维卷积、三维批量归一化和 SiLU[43]激活函数完成尺度序列特征提取。
3.3 三重特征编码模块(Triple feature encoding module)
为了识别密集重叠的小物体,可以通过放大图像来参考和比较不同尺度下的形状或外观变化。由于骨干网络的不同特征层具有不同的尺寸,传统的 FPN 融合机制只是对小尺寸的特征图进行上采样,然后将其分割或添加到上一层的特征中,忽略了大尺寸特征层丰富的细节信息。因此,作者提出了 TFE 模块,它可以分割大、中、小尺寸的特征,添加大尺寸的特征图,并进行特征放大,以完善详细的特征信息。

图 4 展示了 TFE 模块的结构。在进行特征编码之前,首先要调整特征通道的数量,使其与主要尺度特征保持一致。卷积模块处理大尺寸特征图(Large)后,将其通道数调整为 1C,然后采用最大池化 + 平均池化的混合结构进行降采样,这有助于保留高分辨率特征和细胞图像的有效性和多样性。对于小尺寸的特征图(Small),同样使用卷积模块来调整通道数,然后使用最近邻插值法进行上采样。这有助于保持低分辨率图像局部特征的丰富性,防止小目标特征信息的丢失。最后,将尺寸相同的大、中、小三个特征图进行一次卷积,然后在通道维度上进行拼接,具体方法如下。
F
T
F
E
=
C
o
n
c
a
t
(
F
l
,
F
m
,
F
s
)
F_{TFE}=Concat(F_{l},F_{m},F_{\mathrm{s}})
FTFE=Concat(Fl,Fm,Fs)
其中,
F
T
F
E
F_{TFE}
FTFE 表示 TFE 模块输出的特征图。
F
l
F_l
Fl、
F
m
F_m
Fm 和
F
s
F_s
Fs 分别表示大、中、小尺寸的特征图。
F
T
F
E
F_{TFE}
FTFE 由
F
l
F_l
Fl、
F
m
F_m
Fm 和
F
s
F_s
Fs 连接而成。
F
T
F
E
F_{TFE}
FTFE的分辨率与
F
m
F_m
Fm 相同,通道数是
F
m
F_m
Fm 的三倍。
3.4 通道和位置注意力机制(Channel and position attention mechanism)

为了提取不同通道中包含的代表性特征信息,作者提出了 CPAM模块,以整合细节特征信息和多尺度特征信息。CPAM 的结构如图 5 所示。它由一个接收 TFE 输入的通道注意力网络(Input 1)和一个接收通道注意力网络与 SSFF 输出叠加输入的位置注意力网络(Input 2)组成。
通道注意力网络的输入 1 是 PANet 之后的特征图,其中包含 TFE 的细节特征。SENet [28] 通道注意力模块首先对每个通道单独采用全局平均池化处理和使用带有一个非线性 Sigmoid 函数的两个全连接层来生成通道权重。两个全连接层旨在捕捉非线性的跨通道交互,这就需要降低维度来控制模型的复杂性,但降维会给通道注意力预测带来副作用,而且捕捉所有通道之间的依赖关系既低效又没有必要。作者引入了一种无需降维的注意力机制,以有效捕捉跨通道交互。在不降维的情况下,对通道进行全局平均池化后,通过考虑每个通道及其 k 个近邻来捕捉局部跨通道交互,即使用大小为 k 的一维卷积来实现,其中内核大小 k 代表了局部跨通道交互的覆盖率,即有多少个邻居参与了一个通道的注意力预测。为了获得最佳的覆盖率,可以在不同的网络结构和不同数量的卷积模块中手动调整 k,但这样做很繁琐。由于卷积核大小 k 与信道维度 C 成正比,可以看出 k 与 C 之间存在映射关系。通道维度的指数一般为 2,映射关系如下。
C
=
ψ
(
k
)
=
2
(
γ
×
k
−
b
)
C=\psi(k)=2^{(\gamma\times k-b)}
C=ψ(k)=2(γ×k−b)
为了在通道数较多的层中实现更多的跨通道交互,可以通过一个函数来调整一维卷积的卷积核大小。可以计算出卷积核大小 k:
k
=
Ψ
(
C
)
=
∣
l
o
g
2
(
C
)
)
+
b
γ
∣
o
d
d
k=\Psi(C)=|\frac{log_2(C))+b}\gamma|_{odd}
k=Ψ(C)=∣γlog2(C))+b∣odd
其中
∣
∗
∣
o
d
d
| * |_{odd}
∣∗∣odd表示最近邻居的奇数。
γ
γ
γ的值设为 2,b 设为 1。根据上述非线性映射关系,高值通道的交换时间较长,而低值通道的交换时间较短。因此,通道注意力机制可以对多个通道特征进行更深入的挖掘。
将通道注意力机制的输出与 SSFF(Input 2)的特征相结合,作为位置注意力网络的输入,可提供互补信息,提取每个细胞的关键位置信息。与通道注意力机制不同,位置注意机制首先将输入的特征图按宽度和高度分成两部分,然后分别进行轴( p w p_w pw 和 p h p_h ph )特征编码处理,最后合并生成输出。
更确切地说,输入的特征图在水平轴(
p
w
p_w
pw )和垂直轴(
p
h
p_h
ph)上进行合并,以保留特征图的空间结构信息,其计算公式如下:
p
ω
=
1
H
∑
0
≤
j
≤
H
E
(
w
,
j
)
p
h
=
1
W
∑
0
≤
i
≤
W
E
(
i
,
h
)
\begin{aligned}p_{\omega}&=\frac1H\sum_{0\leq j\leq H}E(w,j)\\p_{h}&=\frac1W\sum_{0\leq i\leq W}E(i,h)\end{aligned}
pωph=H10≤j≤H∑E(w,j)=W10≤i≤W∑E(i,h)
其中,
w
w
w 和
h
h
h 分别是输入特征图的宽度和高度。
E
(
w
,
j
)
E(w,j)
E(w,j)和
E
(
i
,
h
)
E(i,h)
E(i,h)是输入特征图中位置
(
i
,
j
)
(i,j)
(i,j)的值。
当生成位置注意力坐标时,会对水平轴和垂直轴进行连接和卷积操作:
P
(
a
w
,
a
h
)
=
C
o
n
v
[
C
o
n
c
a
t
(
p
w
,
p
h
)
]
P(a_w,a_h)=Conv[Concat(p_w,p_h)]
P(aw,ah)=Conv[Concat(pw,ph)]
其中,
P
(
a
w
,
a
h
)
P (a_w, a_h)
P(aw,ah) 表示位置注意力坐标的输出,
C
o
n
v
Conv
Conv 表示 1 × 1 卷积,
C
o
n
c
a
t
Concat
Concat 表示连接。
在对注意力特征进行分割时,会生成一对位置相关特征图,如下:
s
w
=
S
p
l
i
t
(
a
w
)
s
h
=
S
p
l
i
t
(
a
h
)
\begin{aligned}s_w&=Split(a_w)\\s_h&=Split(a_h)\end{aligned}
swsh=Split(aw)=Split(ah)
其中,
s
w
s_w
sw 和
s
h
s_h
sh 分别为分割输出的宽度和高度。
CPAM 的最终输出定义如下:
F
C
P
A
M
=
E
×
s
w
×
s
h
F_{CPAM}=E\times\mathfrak\ s_w\times\mathfrak\ s_h
FCPAM=E× sw× sh
其中,E 代表通道和位置注意力的权重。
3.5 锚框优化(Anchor box optimization)
通过优化损失函数和非最大抑制(Non-Maximum Suppression, NMS),改进了三个检测头的锚框,从而准确地完成了不同大小细胞图像的实例分割任务。
并交比(Intersection over Union, IoU)通常被用作锚框损失函数,通过计算标注边界框和预测框之间的重叠程度来确定收敛性。然而,经典的 IoU 损失无法反映目标框与锚框之间的距离和重叠程度。为了解决这些问题,有人提出了 GIoU [44]、DIoU 和 CIoU [45]。CIoU 在 DIoU Loss 的基础上引入了一个影响因子,YOLOv5 和 YOLOv8 采用了该因子。在考虑重叠区域和中心点距离对损失函数影响的同时,它还考虑了标注框和预测框的宽高(即纵横)比对损失函数的影响。不过,它只反映了长宽比的差异,而不是标注框的宽度和高度与预测框之间的真实关系。EIoU[14]最小化了目标框和锚框之间的宽度和高度差,可以改善小物体的定位效果。EIoU 损失可分为 3 部分:IoU 损失函数
L
I
o
U
L_{IoU}
LIoU、距离损失函数
L
d
i
s
L{dis}
Ldis 和方位损失函数
L
a
s
p
L_{asp}
Lasp,其计算公式如下。
L
E
I
o
U
=
L
I
o
U
+
L
d
i
s
+
L
a
s
p
=
1
−
I
o
U
+
ρ
2
(
b
,
b
g
t
)
ω
c
2
+
h
c
2
+
ρ
2
(
w
,
ω
g
t
)
ω
c
2
+
ρ
2
(
h
,
h
g
t
)
h
c
2
L_{EIoU}=L_{IoU}+L_{dis}+L_{asp}=1-IoU+\frac{\rho^{2}(b,b_{gt})}{\omega_{c}^{2}+h_{c}^{2}}+\frac{\rho^{2}(w,\omega_{gt})}{\omega_{c}^{2}}+\frac{\rho^{2}(h,h_{gt})}{h_{c}^{2}}
LEIoU=LIoU+Ldis+Lasp=1−IoU+ωc2+hc2ρ2(b,bgt)+ωc2ρ2(w,ωgt)+hc2ρ2(h,hgt)
其中,
ρ
(
⋅
)
=
∥
b
−
b
g
t
∥
2
\rho(\cdot)=\|b-b_{gt}\|_2
ρ(⋅)=∥b−bgt∥2 表示欧氏距离,
b
b
b 和
b
g
t
b_{gt}
bgt 分别表示
B
B
B 和
B
g
t
B_{gt}
Bgt 的中心点;
b
g
t
b_{gt}
bgt、
w
g
t
w_{gt}
wgt 和
h
g
t
h_{gt}
hgt分别为真实值的中心点 b、宽度和高度;
w
c
w_c
wc 和
h
c
h_c
hc表示覆盖两个框的最小包围框的宽度和高度。与 CIoU 相比,EIoU 不仅能加快预测框的收敛速度,还能提高回归精度。因此,作者选择 EIoU 来替代头部的 CIoU。
为了消除重复的锚框,检测模型会同时输出多个检测边界,尤其是当真实物体周围有许多高置信度的检测边界时。经典 NMS 算法 [46] 的原理是获取局部最大值。如果当前边界框与得分最高的检测框之间的差值大于阈值,则直接将边界框的得分设为零。为了克服经典 NMS 算法带来的误差,采用了 Soft-NMS 算法[15],该算法使用高斯函数作为权重函数,降低预测边界的得分来替代原始得分,而不是直接将其设为零,从而修改了边界框的误差规则。
4 实验(Experiments)
4.1 数据集(Datasets)
在两个细胞图像数据集上评估了所提出的 ASF-YOLO 模型的性能:DSB2018 和 BCC 数据集。2018 Data Science Bowl(DSB2018)数据集[47]包含 670 张带分割掩膜的细胞核图像,旨在评估算法在不同细胞类型、放大倍数和成像模式(亮视野与荧光)下的通用性。每个掩膜包含一个细胞核,掩膜之间没有重叠(没有像素属于两个掩膜)。数据集按 8:2 的比例随机分为训练集和测试集。训练集和测试集的样本量分别为 536 张图像和 134 张图像。
乳腺癌细胞(Breast Cancer Cell,BCC)数据集 [48] 收集自加州大学圣巴巴拉分校生物图像信息学中心(UCSB CBI)。该数据集包括 160 张用于乳腺癌细胞检测的苏木精和伊红染色组织病理学图像,以及相关的真实值数据。数据集随机分为 128 幅图像(80%)作为训练集,32 幅图像(20%)作为测试集。
4.2 实现细节(Implementation details)
实验在英伟达™(NVIDIA®)GeForce 3090 (24G) GPU 和 Pytorch 1.10、Python 3.7 和 CUDA 11.3 的支持下进行。采用了预训练 COCO 数据集的初始权重。输入图像大小为 640×640。训练数据的batch size大小为 16。训练过程持续 100 个epochs。使用随机梯度下降(Stochastic Gradient Descent, SGD)作为优化函数来训练模型。SDG 的超参数设置为动量 0.9、初始学习率 0.001 和权重衰减 0.0005。
4.3 定量结果(Quantitative results)
表 1 显示了 ASF-YOLO 在 DSB2018 数据集上与其他经典和先进方法的性能比较,这些方法包括 Mask R-CNN [2]、Cascade Mask R-CNN [3]、SOLO [4]、SOLOv2 [5]、YOLACT [6]、Mask R-CNN with Swin Transformer backbone (Mask RCNN Swin T)、YOLOv5l-seg v7.0 [8] 和 YOLOv8l-seg [9]。

作者的模型有 4618 万个参数,准确率最高,Box mAP50 为 0.91,Mask mAP50 为 0.887,推理速度达到 47.3 FPS,性能最佳。由于图像输入大小为 800×1200,使用 Swin Transformer 主干网络的 Mask R-CNN 的精度和速度都不高。提出的模型还超越了经典的单级算法 SOLO 和 YOLACT。
如表 2 所示,提出的模型在 BCC 数据集上也取得了最佳的实例分割性能。实验验证显示了 ASF-YOLO 对不同细胞类型数据集的泛化能力。

4.4 定性结果(Qualitative results)
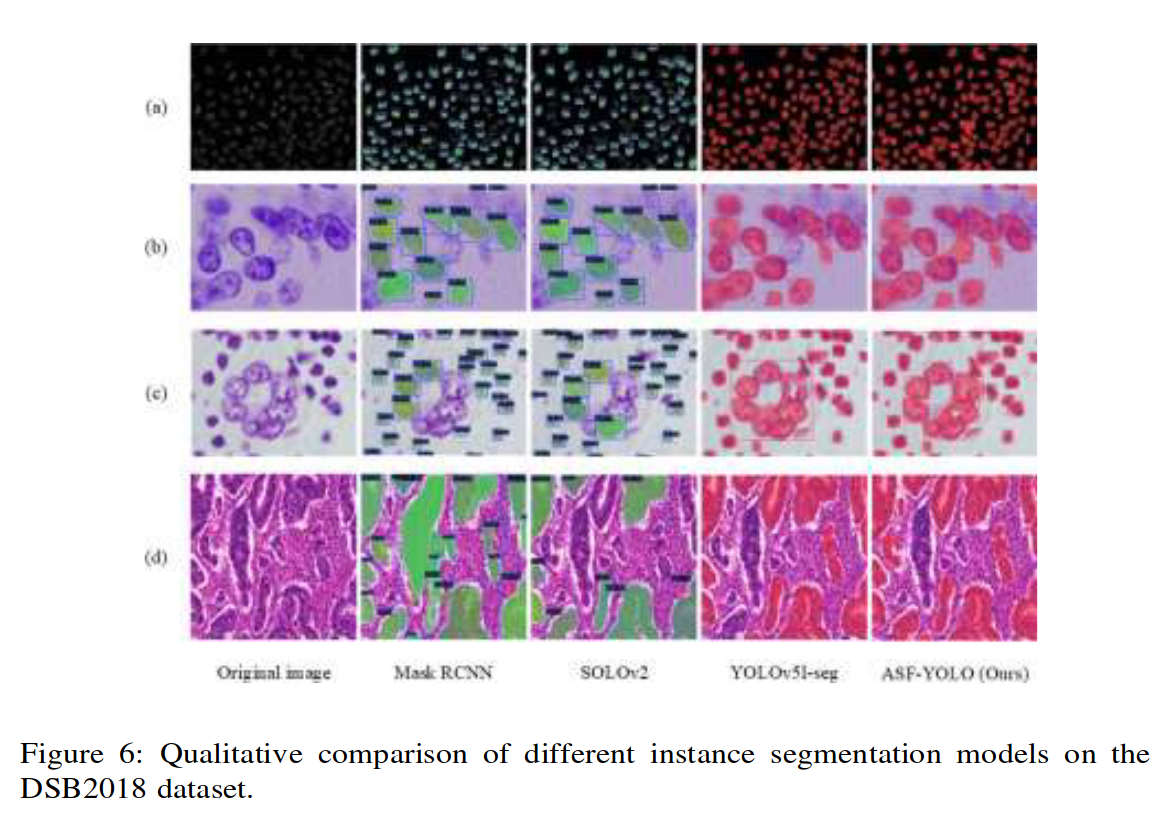
图 6 直观对比了不同方法在 DSB2018 数据集样本图像上的细胞分割效果。通过使用 TFC 模块提高小物体检测性能,ASF-YOLO 对于单通道中密集且小物体的细胞图像具有良好的召回值。通过使用 SSFF 模块提高多尺度特征提取性能,ASF-YOLO 对复杂背景下的大尺寸细胞图像也有很好的分割精度。这表明提出的方法对不同类型的细胞具有良好的普适性。从图 6(a)和(b)中可以看出,由于细胞图像相对简单,因此每个模型都有很好的结果。从图 6©和(d)中可以看出,由于两阶段算法的设计原理,Mask R-CNN 的误检率较高。SOLO 有很多漏检,YOLOv5l-seg 无法分割边界模糊的细胞。
4.5 消融研究(Ablation study)
对提出的 ASFYOLO 模型进行了一系列大量的消融研究。
4.5.1 提出方法的影响(Effect of the proposed methods)
表 3 显示了每个提出的模块在提高分割性能方面的贡献。在 YOLOv5l-seg 中使用 Soft-NMS 可以克服在检测密集小物体细胞时由于相互遮挡而产生的误差抑制问题,从而提高性能。EIoU 损失函数改善了小物体边界框的效果,使 mAP50:95 提高了 1.8%。SSFF、TFC 和 CPAM 模块通过解决细胞图像的小物体实例分割问题,有效提高了模型性能。

4.5.2 注意力机制的影响(Effect of attention mechanisms)
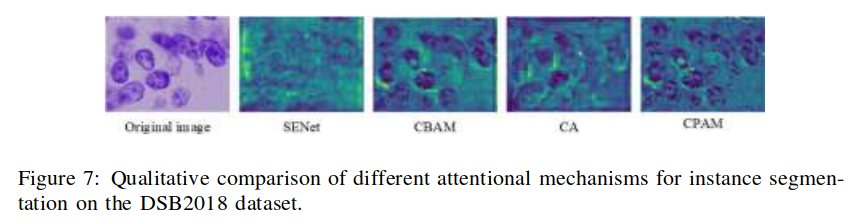
与通道注意力SENet、通道和空间注意力CBAM 以及空间注意力 CA [49]相比,尽管计算量和参数略有增加,但所提出的 CPAM 注意力机制具有更好的性能。图 7 显示了 ASF-YOLO 模型中使用不同注意力模块的分割结果。提出的 CPAM 具有更好的通道和位置特征信息,能从原始图像中挖掘出更丰富的特征。
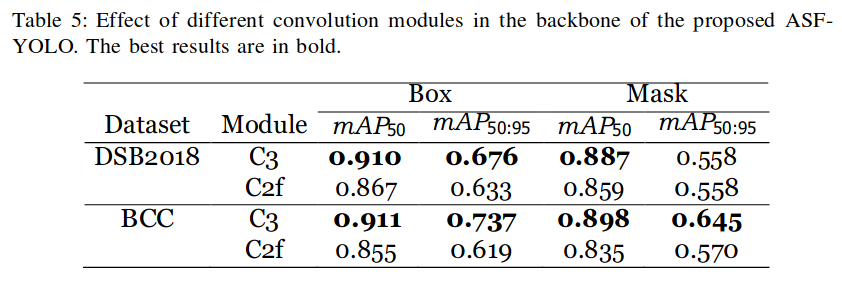
4.5.3 骨干网络中卷积模块的影响(Effect of convolution module in the backbone)
表 5 显示,当 YOLOv5 的 C3 模块被 YOLOv8 的 C2f 模块取代后,提出模型的主干网络就会发生变化,在两个数据集上,骨干网络中 C2f 模块的性能都有所下降。
5 总结
作者提出了一种用于细胞图像分析的准确而快速的实例分割模型 ASF-YOLO,该模型融合了可用于细胞图像的检测和分割的空间和尺度特征。在 YOLO 框架中引入了几个新模块。SSFF 和 TFE 模块提高了多尺度和小对象实例分割的性能。通道和位置注意力机制进一步挖掘了这两个模块的特征信息。大量的实验结果表明,提出的模型能够处理各种细胞图像的实例分割任务,并大大提高了原始 YOLO 模型对小物体和密集物体进行细胞分割的准确性。在细胞实例分割的准确性和推理速度方面,方法都大大优于最先进的方法。由于本文的数据集规模较小,模型的泛化性能有待进一步提高。此外,在消融研究中讨论了 ASF-YOLO 中各模块的有效性,为进一步改进提供了研究依据。
![[机器学习]TF-IDF算法](https://img-blog.csdnimg.cn/direct/87fcdb2e1e484015ac3e7e9f384d5845.png)