文章目录
- 0. 前言
- 1. ROI池化的提出背景
- 2. RoI池化的结构与工作原理
- 3. RoI池化的作用及意义
- 4. RoI使用示例
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文基于Ross Girshick在2015年发表的论文Fast R-CNN 讲解在Fast R-CNN中的RoI池化的作用及原理。
1. ROI池化的提出背景
在目标检测领域,早期的方法R-CNN(Region-based Convolutional Neural Networks)虽然取得了显著的进步,但它将任务分解为多个阶段工作流(multi-stage pipelines),每个阶段都负责处理特定的子任务,并将其输出传递给下一个阶段。
这就造成了训练时也要分阶段进行,最终导致计算效率低下、无法实现端到端训练等不足。另外,R-CNN中,每个候选区域需要独立地通过全卷积网络提取特征,特征图不共享,这样导致了大量的重复计算。受此启发,Girshick等人提出了Fast R-CNN模型,该模型首次引入了RoI池化这一关键组件。
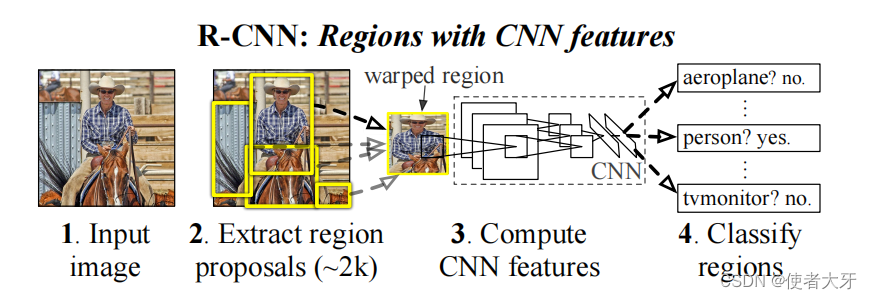
除了计算效率低之外,R-CNN的另一个缺点是丢失训练原图的精度,这是因为深度卷积网络之后是全连接网络,而全连接层的输入大小是必须固定的,进而也就要求了卷积层输出的特征图尺寸也要固定,但候选区域(proposal region)大小是不固定的,这就意味着需要对原图进行缩放(warp)或裁剪(crop),最终导致原图精度丢失。
RoI池化的设计初衷是为了优化R-CNN中的特征提取步骤,它解决了传统方法中由于候选框尺寸不一而导致的特征大小不匹配问题,并把训练由多阶变成单阶有效减少了计算成本。在Fast R-CNN之后,Ross Girshick等人又于2016年进一步发展了Faster R-CNN模型,在保持高效性能的同时,利用区域提议网络(RPN)生成候选框,而RoI池化则负责将这些候选框映射回特征图并进行特征统一化处理,从而实现了更为高效的检测流程。
关于RPN,之前的文章已经介绍过:RPN(Region Proposal Networks)候选区域网络算法解析(附PyTorch代码)
2. RoI池化的结构与工作原理
RoI池化位于整个Faster R-CNN架构的特征提取部分与分类回归部分之间:
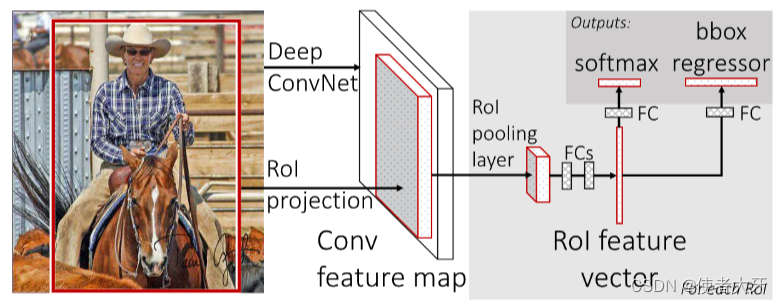
其结构主要包括以下2步:
-
RoI投影:首先,来自RPN或外部提供的候选区域被映射到预训练的主干网络(如VGG)输出的共享特征图上。每个候选区域定义了一个在特征图上的矩形区域,其数据维度为(N, 5),其中N为候选区域(候选框)的数量,5为候选框的尺寸(x, y, w, h)加一个候选框id。
-
RoI池化层:对于每个映射后的候选区域,RoI池化层采用最大池化,将其转换为一个固定的尺寸,例如7x7像素。这意味着不论原始候选框尺寸如何变化,经过RoI池化层后都会得到相同维度的特征向量。
经过RoI池化以及后续的全连接层等最后有两个输出:①分类输出:输出目标的分类向量,例如onehot向量;②回归输出:输出bounding box的尺寸(x, y, w, h)。
3. RoI池化的作用及意义
RoI池化在目标检测框架中具有核心作用:
-
减少计算复杂度:通过一次前向传播计算出整张图像的特征图,然后在该特征图上对所有候选区域进行池化操作,避免了对每个候选框都进行单独的卷积计算,极大地提高了算法效率。
-
标准化特征表示:无论输入的目标对象尺寸如何变化,ROI池化都能将其转化为固定长度的特征向量,这使得后续全连接层可以接受统一格式的输入,便于进行分类和边界框回归任务。
-
增强模型泛化能力:通过池化操作,模型能够更好地应对不同尺度和长宽比的目标,增强了模型在各种复杂场景下的适应性和鲁棒性。
综上所述,RoI池化作为Fast R-CNN的核心组成部分,它的设计和应用不仅提升了目标检测系统的实时性和准确性,而且为深度学习目标检测算法的发展奠定了坚实基础。
4. RoI使用示例
这里以 torchvision.ops中的roi_pool模块说明RoI的使用示例,首先看下roi_pool的源代码定义:
在开始前需要对比说明下
torchvision中的roi_pool和roi_align:roi_align是roi_pool的一个改进版本,它在Mask R-CNN等更现代的目标检测和实例分割模型中被广泛采用,目前roi_align是更常用的方法。
本文作为示例仅说明roi_pool的使用方法。当然在实际使用中也很少有人会单独使用RoI模块,这个示例纯粹是为了加深对RoI的理解。
def roi_pool(
input: Tensor,
boxes: Union[Tensor, List[Tensor]],
output_size: BroadcastingList2[int],
spatial_scale: float = 1.0,
) -> Tensor:
"""
Performs Region of Interest (RoI) Pool operator described in Fast R-CNN
Args:
input (Tensor[N, C, H, W]): The input tensor, i.e. a batch with ``N`` elements. Each element
contains ``C`` feature maps of dimensions ``H x W``.
boxes (Tensor[K, 5] or List[Tensor[L, 4]]): the box coordinates in (x1, y1, x2, y2)
format where the regions will be taken from.
The coordinate must satisfy ``0 <= x1 < x2`` and ``0 <= y1 < y2``.
If a single Tensor is passed, then the first column should
contain the index of the corresponding element in the batch, i.e. a number in ``[0, N - 1]``.
If a list of Tensors is passed, then each Tensor will correspond to the boxes for an element i
in the batch.
output_size (int or Tuple[int, int]): the size of the output after the cropping
is performed, as (height, width)
spatial_scale (float): a scaling factor that maps the box coordinates to
the input coordinates. For example, if your boxes are defined on the scale
of a 224x224 image and your input is a 112x112 feature map (resulting from a 0.5x scaling of
the original image), you'll want to set this to 0.5. Default: 1.0
Returns:
Tensor[K, C, output_size[0], output_size[1]]: The pooled RoIs.
"""
使用示例:
import torch
from torchvision.ops import roi_pool
# 假设我们有以下输入:
input_feature_map = torch.randn(10, 256, 32, 32, dtype=torch.float32) # [N, C, H, W],N是批量大小,C是通道数,H和W是特征图的高度和宽度
rois = torch.tensor([[0, 1, 1, 10, 10], # 对于每个ROI,前一个数字是batch索引,后四个是左上角和右下角坐标
[1, 30, 30, 100, 100]], dtype=torch.float32) # [K, 5],K是ROI的数量,这里K=2
# 定义输出尺寸(例如7x7)
output_size = (7, 7)
# 定义空间比例因子,通常是在特征图与原始图像之间做归一化处理
spatial_scale = 1.0 / 16 # 假设特征图是原图经过16倍下采样得到的
# 应用ROI Pooling
pooled_features = roi_pool(input_feature_map, rois, output_size, spatial_scale)
print(pooled_features.shape)
# pooled_features 的形状将是 [K, C, output_size[0], output_size[1]],输出为torch.Size([2, 256, 7, 7])