机器学习模型预测贷款审批
作者:i阿极
作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
大家好,我i阿极。喜欢本专栏的小伙伴,请多多支持
| 专栏案例:机器学习案例 |
|---|
| 机器学习(一):线性回归之最小二乘法 |
| 机器学习(二):线性回归之梯度下降法 |
| 机器学习(三):基于线性回归对波士顿房价预测 |
| 机器学习(四):基于KNN算法对鸢尾花类别进行分类预测 |
| 机器学习(五):基于KNN模型对高炉发电量进行回归预测分析 |
| 机器学习(六):基于高斯贝叶斯对面部皮肤进行预测分析 |
| 机器学习(七):基于多项式贝叶斯对蘑菇毒性分类预测分析 |
| 机器学习(八):基于PCA对人脸识别数据降维并建立KNN模型检验 |
| 机器学习(十四):基于逻辑回归对超市销售活动预测分析 |
| 机器学习(十五):基于神经网络对用户评论情感分析预测 |
| 机器学习(十六):线性回归分析女性身高与体重之间的关系 |
| 机器学习(十七):基于支持向量机(SVM)进行人脸识别预测 |
| 机器学习(十八):基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习(十九):基于逻辑回归对某银行客户违约预测分析 |
| 机器学习(二十):LightGBM算法原理(附案例实战) |
| 机器学习(二十一):基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习(二十二):基于逻辑回归(Logistic Regression)对股票客户流失预测分析 |
文章目录
- 机器学习模型预测贷款审批
- 1、前言
- 2、导入库和数据集
- 3、数据预处理和可视化
- 4、分割数据集
- 5、模型训练与评估
- 总结
1、前言
贷款是现代世界的主要需求。仅此一点,银行就获得了总利润的主要部分。它有利于学生管理他们的教育和生活费用,也有利于人们购买任何类型的奢侈品,如房子、汽车等。
但在决定申请人的个人资料是否与获得贷款相关时。银行必须照顾很多方面。
因此,在这里我们将使用Python机器学习来简化他们的工作,并使用婚姻状况、教育、申请人收入、信用记录等关键特征来预测候选人的个人资料是否相关。
该数据集包含 13 个特征:
| 1 | 贷款 | 唯一的ID |
|---|---|---|
| 2 | 性别 | 申请人性别 男/女 |
| 3 | 已婚 | 申请人的婚姻状况,值为是/否 |
| 4 | 家属 | 它告诉申请人是否有任何家属。 |
| 5 | 教育 | 它将告诉我们申请人是否已毕业。 |
| 6 | 自雇 | 这定义了申请人是自营职业者,即是/否 |
| 7 | 申请人收入 | 申请人收入 |
| 8 | 共同申请人收入 | 共同申请人的收入 |
| 9 | 贷款额度 | 贷款金额(万) |
| 10 | 贷款金额_期限 | 贷款期限(月) |
| 11 | 信用_历史 | 个人还款信用记录 |
| 12 | 物业_面积 | 房产面积,即农村/城市/半城市 |
| 13 | 贷款状态 | 贷款状态是否已批准,即 Y- 是、N- 否 |
2、导入库和数据集
首先我们必须导入库:
Pandas – 加载数据框
Matplotlib – 可视化数据特征,即条形图
Seaborn – 使用热图查看特征之间的相关性
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("LoanApprovalPrediction.csv")
导入数据集后,让我们使用以下命令查看它。
data.head(5)

3、数据预处理和可视化
获取对象数据类型的列数。
obj = (data.dtypes == 'object')
print("Categorical variables:",len(list(obj[obj].index)))

由于 Loan_ID 是完全唯一的,并且与任何其他列都不相关,因此我们将使用 删除它。drop()函数。
data.drop(['Loan_ID'],axis=1,inplace=True)
使用barplot可视化列中的所有唯一值。这将简单地显示根据我们的数据集哪个值占主导地位。
obj = (data.dtypes == 'object')
object_cols = list(obj[obj].index)
plt.figure(figsize=(18,36))
index = 1
for col in object_cols:
y = data[col].value_counts()
plt.subplot(11,4,index)
plt.xticks(rotation=90)
sns.barplot(x=list(y.index), y=y)
index +=1
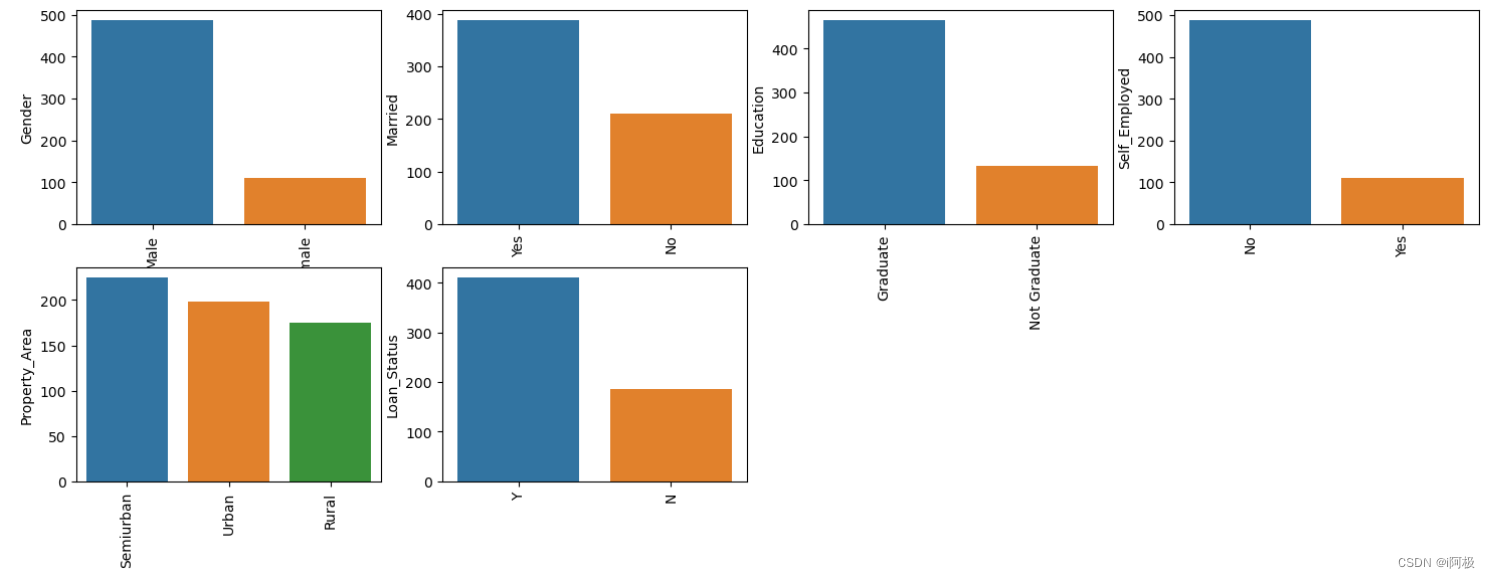
由于所有分类值都是二进制的,因此我们可以对所有此类列使用标签编码器,并且这些值将更改为int数据类型。
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
obj = (data.dtypes == 'object')
for col in list(obj[obj].index):
data[col] = label_encoder.fit_transform(data[col])
再次检查对象数据类型列。让我们看看是否还有剩余。
obj = (data.dtypes == 'object')
print("Categorical variables:",len(list(obj[obj].index)))
使用热力图显示了贷款金额和申请人收入之间的相关性。
plt.figure(figsize=(12,6))
sns.heatmap(data.corr(),cmap='BrBG',fmt='.2f',
linewidths=2,annot=True)
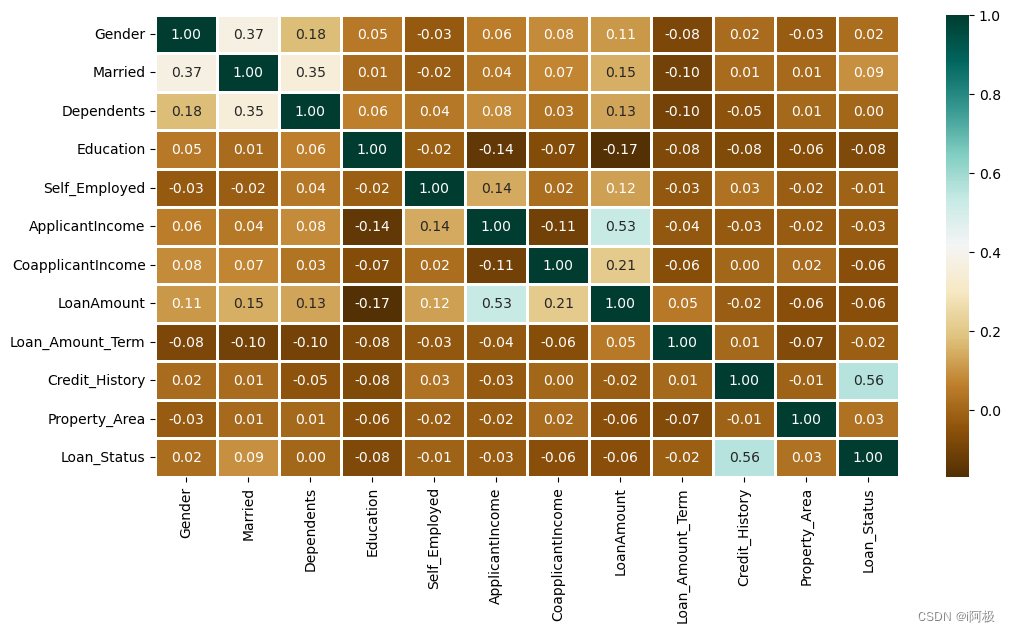
明 Credit_History 对 Loan_Status 有很大影响。
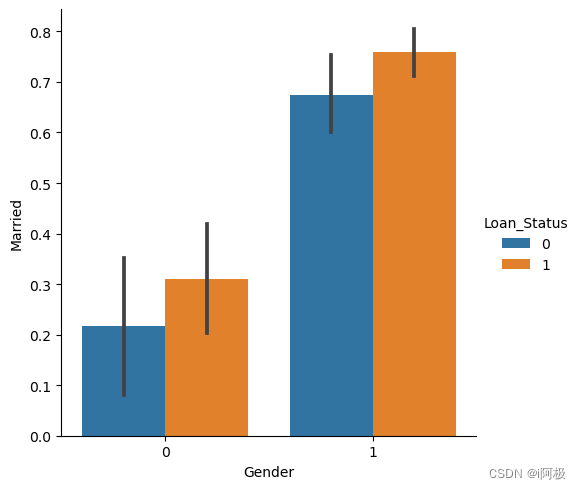
现在我们将使用Catplot可视化申请人的性别和婚姻状况图。
sns.catplot(x="Gender", y="Married",
hue="Loan_Status",
kind="bar",
data=data)
现在我们将使用以下代码找出数据集中是否存在缺失值。
for col in data.columns:
data[col] = data[col].fillna(data[col].mean())
data.isna().sum()

由于没有缺失值,那么我们必须继续进行模型训练。
4、分割数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Loan_Status'],axis=1)
Y = data['Loan_Status']
X.shape,Y.shape
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,
test_size=0.4,
random_state=1)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape
((358, 11), (240, 11), (358,), (240,))
5、模型训练与评估
由于这是一个分类问题,因此我们将使用这些模型:
K邻居分类器
随机森林分类器
支持向量分类器 (SVC)
逻辑回归
为了预测准确性,我们将使用scikit-learn库中的准确性评分函数。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
knn = KNeighborsClassifier(n_neighbors=3)
rfc = RandomForestClassifier(n_estimators = 7,
criterion = 'entropy',
random_state =7)
svc = SVC()
lc = LogisticRegression()
for clf in (rfc, knn, svc,lc):
clf.fit(X_train, Y_train)
Y_pred = clf.predict(X_train)
print("Accuracy score of ",
clf.__class__.__name__,
"=",100*metrics.accuracy_score(Y_train,
Y_pred))
输出:
Accuracy score of RandomForestClassifier = 98.04469273743017
Accuracy score of KNeighborsClassifier = 78.49162011173185
Accuracy score of SVC = 68.71508379888269
Accuracy score of LogisticRegression = 80.44692737430168
对测试集的预测:
for clf in (rfc, knn, svc,lc):
clf.fit(X_train, Y_train)
Y_pred = clf.predict(X_test)
print("Accuracy score of ",
clf.__class__.__name__,"=",
100*metrics.accuracy_score(Y_test,
Y_pred))
输出:
Accuracy score of RandomForestClassifier = 82.5
Accuracy score of KNeighborsClassifier = 63.74999999999999
Accuracy score of SVC = 69.16666666666667
Accuracy score of LogisticRegression = 80.83333333333333
随机森林分类器给出了最好的准确度,测试数据集的准确度得分为 82.5%。为了获得更好的结果,还可以使用Bagging和Boosting等集成学习技术。
总结
在这里我们将使用Python机器学习来简化他们的工作,并使用婚姻状况、教育、申请人收入、信用记录等关键特征来预测候选人的个人资料是否相关。
不要错过驾驭数据革命浪潮的机会!每个行业都在利用数据的力量来攀登新的高度。磨练你的技能,成为 21 世纪最热门趋势的一部分。
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗