文章目录
- 【文章系列】
- 【前言】
- 【算法简介】
- 【正文】
- (一)XGBoost前身:梯度提升树
- (二)XGBoost的特点
- (三)XGBoost实际操作
- 1. 前期准备
- (1)数据格式
- (2)参数设置
- 2. 实际演示
- (1)获取数据
- (2)转换格式
- (3)设定参数
- (4)开始训练
- (5)可视化训练过程
- 可视化训练过程
【文章系列】
第一章 集成学习_LightGBM————集成学习之Boosting方法系列_LightGBM
第二章 集成学习_XGboost————集成学习之Boosting方法系列_XGboost
第三章 集成学习_CatBoost————集成学习之Boosting方法系列_CatBoost
【前言】
集成学习是一种机器学习方法,通过将多个弱学习器(weak learners)组合成一个更强大的集成模型来提高预测性能和泛化能力。
Boosting 是一种迭代的集成方法,它通过逐步调整训练数据的权重和/或模型的权重来训练多个弱学习器,以便每个弱学习器更关注先前被错误分类的样本。AdaBoost、Gradient Boosting 和 XGBoost 都是 Boosting 的变种。
本文将介绍Boosting方法的其中一种:XGBoost
【算法简介】
XGBoost是一种强大的机器学习算法,它采用梯度提升树的方法,通过集成多个决策树模型来提高预测性能。具有特征重要性评估、正则化、高性能和广泛应用等特点,XGBoost在分类、回归和排名等各种预测任务中表现出色,被广泛应用于数据科学竞赛和实际问题解决中。
【正文】
(一)XGBoost前身:梯度提升树
梯度提升树(Gradient Boosting Trees)是一种集成学习方法,用于解决回归和分类问题。它通过串行构建多个决策树模型来提高预测性能。梯度提升树的主要思想是不断纠正前一个模型的错误,以逐步改进整体模型的性能。
梯度提升树的工作流程如下:
- 创建一个简单的基础模型(通常是决策树),这个模型会对数据进行初步拟合。
- 计算基础模型的预测值与真实标签之间的残差(错误)。这些残差代表了模型在训练数据上的错误。
- 构建一个新的决策树模型,它的目标是减小前一个模型的残差。这个新模型会学习如何将残差映射到更接近真实标签的值。
- 重复上述步骤,每次都构建一个新的决策树模型,目标是进一步减小残差,直到达到预定的迭代次数或直到模型性能不再改进为止。
- 将所有模型的预测结果组合起来,得到最终的集成模型。
梯度提升树的优点包括:
- 能够处理各种类型的数据,包括数值型和类别型特征。
- 具有很强的预测性能,通常能够取得竞赛和实际问题中的良好结果。
- 可以估计特征的重要性,帮助特征选择和理解问题。
- 可以通过调整超参数来控制模型的复杂度,从而避免过拟合。
梯度提升树的一些流行实现包括XGBoost、LightGBM和CatBoost,它们在不同情况下都具有优势,并在机器学习和数据科学领域广泛应用。
(二)XGBoost的特点
- 高性能: XGBoost的实现经过了高度优化,能够高效处理大规模数据集,具有较快的训练和预测速度。这使得它在大数据环境中非常有用。
- 梯度提升框架: XGBoost采用梯度提升算法,通过迭代构建一系列的决策树模型,逐步减小模型的预测误差,从而提高模型性能。
- 正则化: XGBoost支持L1(Lasso正则化)和L2(Ridge正则化)正则化技术,以帮助减少模型的过拟合风险。这有助于提高模型的泛化能力。
- 特征重要性评估: XGBoost能够估计输入特征的重要性,帮助用户识别哪些特征对于模型性能最关键。这有助于特征选择和问题理解。
- 并行计算: XGBoost支持并行计算,可以利用多核CPU进行训练和预测,从而进一步提高性能。
- 灵活性: XGBoost适用于分类、回归和排名任务,并支持多分类问题。此外,它允许用户自定义损失函数,以适应各种问题。
- 广泛应用: XGBoost在数据科学竞赛和实际应用中表现出色,常常在分类、回归、排名、异常检测等各种预测建模任务中取得顶级成绩。
(三)XGBoost实际操作
1. 前期准备
(1)数据格式
对于分类和回归任务,XGBoost的输入通常是一个矩阵,其中每行代表一个样本,每列代表一个特征。以下是一般的输入格式:
- 特征矩阵:一个二维矩阵,包含了所有的训练样本和它们的特征。每行是一个样本,每列是一个特征。特征可以是数值型特征或类别型特征,但通常需要进行特征编码,例如独热编码,以便模型能够处理。
- 标签向量:一个一维向量,包含与每个训练样本相关联的目标变量的值。对于分类问题,目标变量通常是类别标签(整数),而对于回归问题,目标变量是连续数值。
示例代码(Python):
import xgboost as xgb
# 特征矩阵
X = [[feature1, feature2, ...],
[feature1, feature2, ...],
...
]
# 标签向量
y = [label1, label2, ...]
# 创建DMatrix对象
dtrain = xgb.DMatrix(X, label=y)
(2)参数设置
类似于LightGBM的参数设置:
-
config, 默认值为空,配置文件的路径 -
任务参数
-
task, 默认值为train,可选项有:train, predict, convert_model-
train, alias=training, for training
-
predict, alias=prediction, test, for prediction.
-
convert_model, 要将模型文件转换成 if-else 格式
-
-
objective, (优化目标),默认值为regression, 可选项有:regression, regression_l1, huber, fair, poisson, quantile, quantile_l2, binary, multiclass, multiclassova, xentropy, xentlambda, lambdarank-
回归问题
regression_l2, L2 loss, alias=regression, mean_squared_error, mseregression_l1, L1 loss, alias=mean_absolute_error, maehuber, Huber lossfair, Fair losspoisson, Poisson regressionquantile, Quantile regressionquantile_l2, 类似于 quantile, 但是使用了 L2 loss -
binary, 二元分类的交叉熵损失 -
多元分类问题
multiclass, softmax 目标函数, 应该设置好 num_classmulticlassova, One-vs-All 二分类目标函数, 应该设置好 num_class -
交叉熵损失
xentropy, 目标函数为 cross-entropy (同时有可选择的线性权重), alias=cross_entropyxentlambda, 替代参数化的 cross-entropy, alias=cross_entropy_lambda标签是 [0, 1] 间隔内的任意值
-
lambdarank, 排序问题的学习算法在 lambdarank 任务中标签应该为 int type, 数值越大代表相关性越高 (e.g. 0:bad, 1:fair, 2:good, 3:perfect)
label_gain 可以被用来设置 int 标签的增益 (权重)
-
-
reg_alpha:用于设置L1的正则化参数 -
reg_lambda:用于设置L2的正则化参数
-
-
训练参数
-
boosting, (提升类型),默认值为gbdt, 可选项有:gbdt, rf, dart, goss, alias=boost, boosting_typegbdt, 传统的梯度提升决策树rf, Random Forest (随机森林)dart, Dropouts meet Multiple Additive Regression Trees(Dropout 与多个加法回归树的结合)goss, Gradient-based One-Side Sampling (基于梯度的单侧采样)
-
data, 默认值为"",代表训练数据, LightGBM 将会使用这个数据进行训练 -
valid, 默认值为"",验证/测试 数据, LightGBM 将输出这些数据的度量- 支持多验证数据集, 以 , 分割
-
num_iterations,默认值为100,代表boosting 的迭代次数- Note: 对于 Python/R 包, 这个参数是被忽略的, 使用 train and cv 的输入参数 num_boost_round (Python) or nrounds ® 来代替
- Note: 在内部, LightGBM 对于 multiclass 问题设置 num_class * num_iterations 棵树
-
learning_rate,(学习率),默认值为0.1- shrinkage rate (收缩率)
- 在 dart 中, 它还影响了 dropped trees 的归一化权重
-
bagging_seed:随机采样的种子,用于确保可复现性 -
bagging_fraction:每次迭代中随机选择的样本比例,用于减少过拟合风险 -
bagging_freq:随机采样的频率,每隔多少次进行一次随机采样 -
feature_fraction:每次迭代中随机选择的特征比例,用于减少过拟合风险 -
metric:模型评估指标
-
-
树的参数
num_leaves, 默认值为31, 每棵树上的最大叶子数min_child_samples(叶子节点最小样本数):叶子节点上所需的最小样本数,用于控制叶子节点的分裂。max_depth:树的最大深度,设置为-1表示不限制树的深度tree_learner,默认值为serial, 可选项有:serial, feature, data, voting, alias=treeserial, 单台机器的 tree learnerfeature, alias=feature_parallel, 特征并行的 tree learnerdata, alias=data_parallel, 数据并行的 tree learnervoting,alias=voting_parallel, 投票并行的 tree learner
-
性能设置
-
num_threads, 默认值为OpenMP_default, type=int, LightGBM 的线程数- 为了更快的速度, 将此设置为真正的 CPU 内核数, 而不是线程的数量 (大多数 CPU 使用超线程来使每个 CPU 内核生成 2 个线程)
- 当你的数据集小的时候不要将它设置的过大 (比如, 当数据集有 10,000 行时不要使用 64 线程)
- 请注意, 任务管理器或任何类似的 CPU 监视工具可能会报告未被充分利用的内核. 这是正常的
- 对于并行学习, 不应该使用全部的 CPU 内核, 因为这会导致网络性能不佳
-
device, 默认为cpu, 可选项有:cpu, gpu- 为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度
- Note: 建议使用较小的 max_bin (e.g. 63) 来获得更快的速度
- Note: 为了加快学习速度, GPU 默认使用32位浮点数来求和. 你可以设置 gpu_use_dp=true 来启用64位浮点数, 但是它会使训练速度降低
-
2. 实际演示
(1)获取数据
以UCI Raisin数据集为例
导入相关包
import numpy as np
import pandas as pd
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import xgboost as xgb # 导入XGBoost库
import matplotlib.pyplot as plt
获取UCI Raisin数据集
# fetch dataset
raisin = fetch_ucirepo(id=850)
# data (as pandas dataframes)
train = raisin.data.features
label = raisin.data.targets
# metadata
print(raisin.metadata)
# variable information
print(raisin.variables)
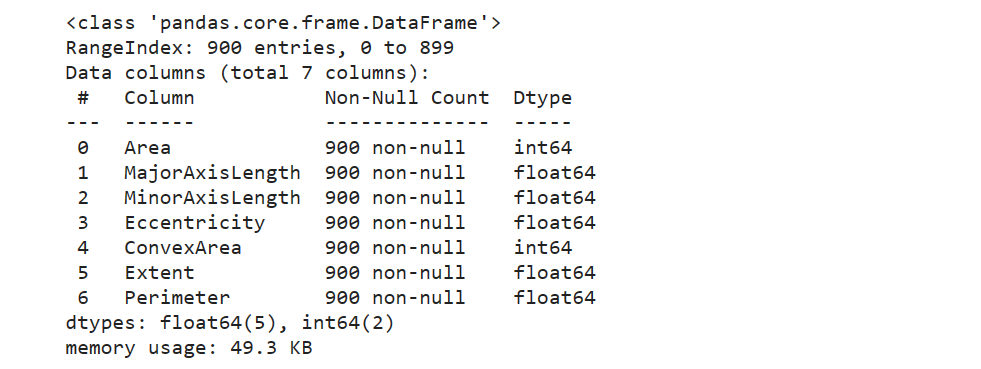
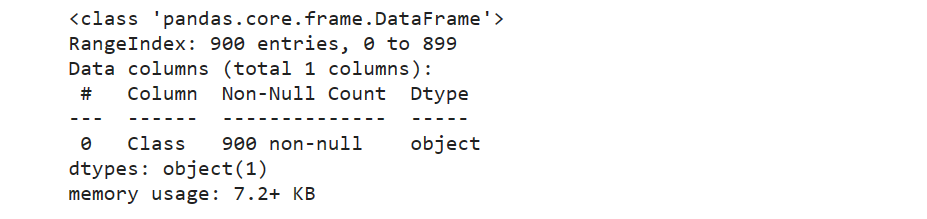
查看输入属性与输出属性
train.info()
label.info()
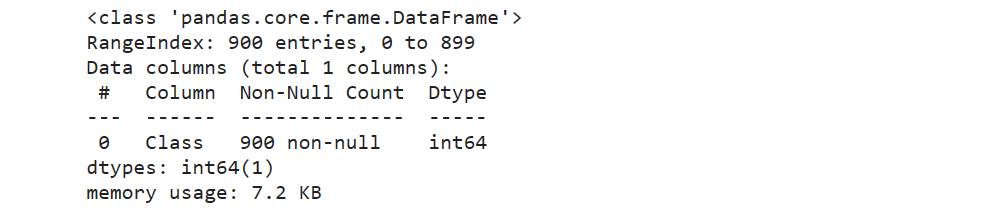
对object数据类型,进行字典编码
def change_object_cols(se):
value = se.unique().tolist()
value.sort()
return se.map(pd.Series(range(len(value)), index=value)).values
label['Class'] = change_object_cols(label['Class'])
label.info()
全部转换为0、1编码
label['Class'].values
(2)转换格式
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(train, label, test_size=0.3, random_state=0)
# 将标签向量转换为一维数组
y_train = y_train.values.ravel()
y_test = y_test.values.ravel()
# 创建XGBoost训练和测试数据集
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test, label=y_test)
(3)设定参数
此数据集是二分类数据集,因此objective设置为’binary’,metric评估指标设置为‘binary_logloss’,使用‘gbdt’方法进行训练。
# 定义XGBoost的参数
params = {
'objective': 'binary:logistic', # 适用于二分类问题
'max_depth': 8, # 决策树深度
'learning_rate': 0.03, # 学习率
'eval_metric': 'logloss', # 评估指标
'num_leaves': 6, # 树的叶子节点数
'subsample': 0.8, # 每次迭代时用于训练的子样本比例
'colsample_bytree': 0.8, # 每次迭代时用于训练的特征比例
'early_stopping_rounds': 20 # 提前停止的轮数,如果验证误差不再下降
}
(4)开始训练
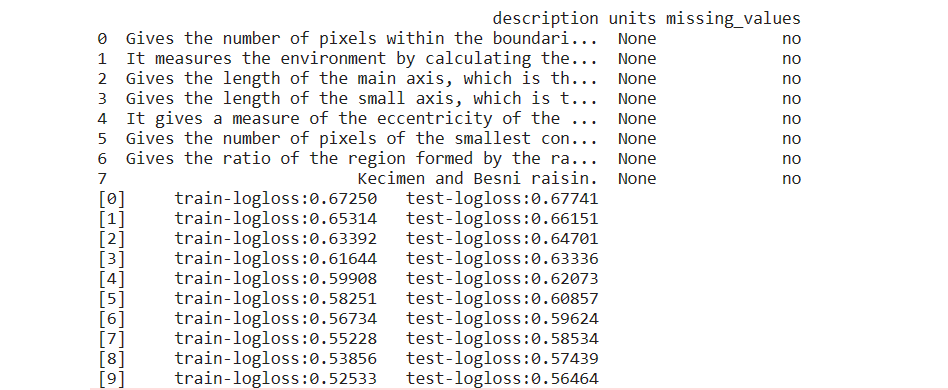
eval_result用于存放每次迭代过程的损失函数值,用于可视化训练过程。
# 训练XGBoost模型
eval_result = {} # 用于存储评估结果
bst = xgb.train(params, dtrain, evals=[(dtrain, "train"), (dtest, "test")], evals_result=eval_result)
(5)可视化训练过程
可视化训练过程
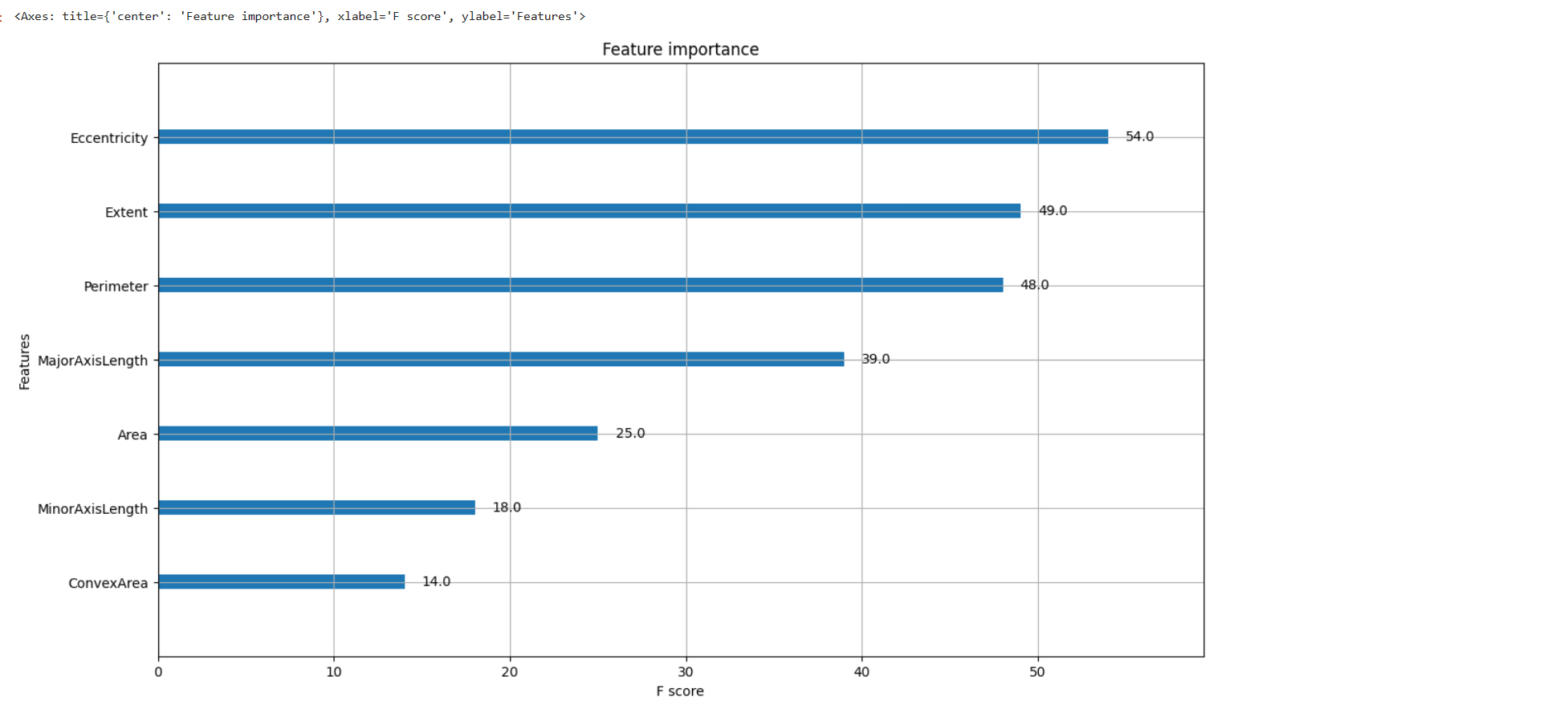
- 特征重要程度
from xgboost import plot_importance
plt.rcParams["figure.figsize"] = (14, 8)
plot_importance(bst)
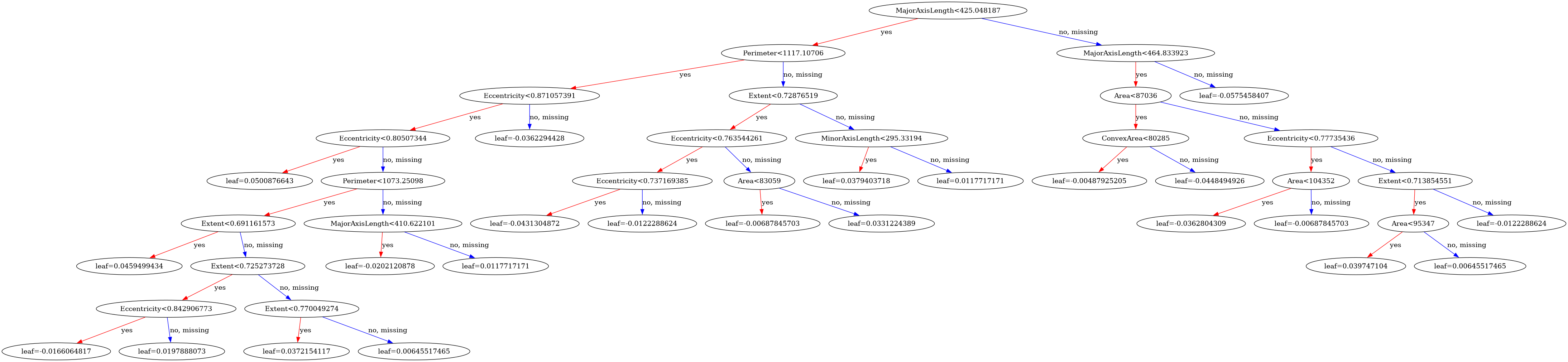
- 树可视化
xgboosts = xgb.to_graphviz(bst)
xgboosts.format = 'png'
xgboosts.render('./xgboost') # 将图形保存为'./xgboost.png'