文章目录
- 数组
- 切片
- append 函数
- copy 函数
- 删除元素
- 映射
- delete 函数
- 函数
- init 特殊的函数
- defer 语句
- panic / recover 错误处理
- 类型
- 结构体
- 内存对齐
- JSON 序列化与反序列化
- 方法和接收者
项目代码地址:03-ArraySliceMapFuncStruct
数组
基本格式:var 数组变量名 [元素数量]T
- 数组长度必须是常量或者常量表达式
- 数组大小不可以修改
- 数组不支持负数索引
...自动推导第一维数组长度
// Array 1
func function01() {
const lenA = 2
var a [lenA + 1]int // 常量表达式定义数组长度
// var lenB = 3
// b := [lenB]int{} 错误!变量不可用于定义数组长度
var b = [1]bool{true} // 基本初始化
var c [2]string = [...]string{"A", "B"} // 省略号自行推断数组长度
d := [...]int{1: -1, 3: 5} // 索引值初始化
fmt.Println(a, b, c, d) // [0 0 0] [true] [A B] [0 -1 0 5]
// 第一维可自动推导长度
citys := [...][3]string{
{"北京", "上海", "广州"},
{"重庆", "湖南", "武汉"},
}
fmt.Println(citys) // [[北京 上海 广州] [重庆 湖南 武汉]]
// 二维数组遍历
for _, v1 := range citys {
for _, city := range v1 {
fmt.Print(city)
}
} // 北京上海广州重庆湖南武汉
}
- 数组是值类型,赋值和传参会拷贝副本
- 数组同类型,可以进行比较
// Array 2
func function02() {
a := [...]int{1, 2}
b := a
b[0] = 3
fmt.Println(a, b) // [1 2] [3 2]
for i, length := 0, len(a); i < length; i++ {
fmt.Printf("%v ", a[i])
} // 1 2
fmt.Println()
// 同类型且内部元素可比较,那么可以使用 == 和 != 比较两个数组
fmt.Printf("%#v %#v %T %T %t %t\n", a, b, a, b, b == a, b != a) // [2]int{1, 2} [2]int{3, 2} [2]int [2]int false true
}
切片
基本格式:var 切片变量名 []T
切片表达式:a[low: high: max],满足 0 <= low <= high <= max <= cap(a),仅 low 可以省略(默认 0)
切片不同于数组,切片长度不固定,可以通过 append 向切片动态添加元素,并且会自动扩容。切片是一个引用类型,可以基于字符串、数组、切片及其指针,通过切片表达式得到切片。
// Slice 1
func function03() {
a := [5]int{1, 2, 3, 4: -1} // 1 2 3 0 -1
strA := "Hello Golang"
ptrStrA := new(string)
ptrStrA = &strA
sliceA := a[1:5] // 基于数组
sliceStrA := strA[6:] // 基于字符串
slicePtrStrA := (*ptrStrA)[:5] // 基于字符串指针
fmt.Println(sliceA, sliceStrA, slicePtrStrA) // [2 3 0 -1] Golang Hello
sliceB := sliceA[2:] // 基于切片
fmt.Println(sliceB) // [0 -1]
sliceB[0] = -2 // 引用类型
fmt.Println(a, sliceA, sliceB) // [1 2 3 -2 -1] [2 3 -2 -1] [-2 -1]
}
切片表达式第三维 max,表示当前截取出的切片的容量 cap = max - low。即 low 是起始位置,high 是 len 长度的结尾位置后一位(左闭右开),max 是 cap 容量的结尾位置后一位。

如果想要动态创建切片,需要使用内置 make 函数:make([]T, size, cap)
使用 make 函数,可以一次性将切片所需容量申请到位,可以避免小切片的多次动态扩容。
// Slice 2
func function04() {
a := [...]int{0, 1, 2, 3, 4, 5, 6, 7}
fmt.Println(a, len(a), cap(a)) // [0 1 2 3 4 5 6 7] 8 8
sliceA1 := a[1:5]
fmt.Println(sliceA1, len(sliceA1), cap(sliceA1)) // [1 2 3 4] 4 7
sliceA2 := a[1:5:7]
fmt.Println(sliceA2, len(sliceA2), cap(sliceA2)) // [1 2 3 4] 4 6
b := make([]int, 1, 4)
b = append(b, 2, 3)
fmt.Println(b) // [0 2 3]
}
-
nil切片和empty切片-
nil 切片,不仅没大小容量,且不指向任何底层数组;
-
empty 切片,没大小容量,但指向一个特殊的内存地址 zerobase — 所有 0 字节分配的基地址
-
判断一个切片是否为空,使用 len(a) == 0 而不要直接使用 a == nil,因为切片元素不是直接存储的值,所以也不允许切片之间使用 == 比较,唯一合法可以和 nil 进行比较。
// Slice 3
func function05() {
var s1 []int // nil 切片,不仅没大小容量,且不指向任何底层数组
s2 := []int{}
s3 := make([]int, 0) // s2、s3 都是 empty 切片,没大小容量,但指向一个特殊的内存地址 zerobase - 所有 0 字节分配的基地址
fmt.Println(len(s1), len(s2), len(s3), cap(s1), cap(s2), cap(s3)) // 0 0 0 0 0 0
fmt.Println(s1 == nil, s2 == nil, s3 == nil) // true false false
fmt.Printf("%#v %#v %#v\n", s1, s2, s3) // []int(nil) []int{} []int{}
// fmt.Println(s1 == s2) // 切片之间不允许直接使用 == 比较,唯一可以和 nil 进行比较
}
append 函数
基本格式:append(slice []Type, elems ...Type) []Type
切片在使用 append 函数后,可能会造成扩容,改变底层数组的地址,Go 编译器也不允许调用 append 函数后不使用其返回值,所以通常使用原变量接收 append 函数的返回值。
- 可以对
nil切片直接使用append - 可以一次性添加多个元素到末尾
// Slice 4
func function06() {
var a []int // nil 切片
a = append(a, 2, 3, 4)
fmt.Println(a, len(a), cap(a)) // [2 3 4] 3 3
}
copy 函数
基本格式:copy(destSlice, srcSlice []T) int
不希望两个切片共享底层同一个数组,可以使用 copy 函数,执行深拷贝
// Slice 5
func function07() {
a := []int{1, 2, 3}
var b = make([]int, len(a), len(a))
copy(b, a) // 深拷贝
fmt.Println(a, b) // [1 2 3] [1 2 3]
b[0] = -1
fmt.Println(a, b) // [1 2 3] [-1 2 3]
}
删除元素
- 借助切片本身的特性来删除索引
x元素:append(a[:x], a[x + 1:]...) - 借助
copy来删除索引x元素:copy(a[x:], a[x + 1:]),最终元素需要少一位输出
// Slice 6
func function08() {
a := []int{1, 2, 3}
b := append(a[:1], a[2:]...)
fmt.Println(b) // [1 3]
copy(a[1:], a[2:])
fmt.Println(a[:len(a)-1]) // [1 3]
}
映射
基本格式:map[KeyType]ValueType
Go 中的 map 是引用类型,并且必须初始化才能使用,不像 nil 切片能直接使用。
// Map 1
func function09() {
var a map[string]int
b := map[string]int{}
c := make(map[string]int)
fmt.Println(a == nil, b == nil, c == nil) // true false false
}
同样使用 make 函数初始化:make(map[T]T, cap),第二个参数表示初始化创建的 map 容量大小。
判断键值是否存在:val, ok := map[key]
- key 存在,返回 key 对应 val,且 ok 为 true
- key 不存在,返回 值类型零值,ok 为 false
// Map 2
func function10() {
b := map[string]int{
"周一": 1,
"周二": 2,
}
b["周三"] = 3
// 遍历 map
for k, v := range b {
println(k, v)
}
// 取值第二个返回值,表示是否存在该元素
if v, ok := b["周二"]; ok {
fmt.Println(v)
}
}
delete 函数
基本格式:delete(m map[Type]Type1, key Type)
// Map 3
func function11() {
m := make(map[int]string, 4)
m[1] = "Python"
m[2] = "Go"
m[3] = "Lua"
for _, v := range m {
fmt.Println(v)
} // Python Go Lua
delete(m, 2)
for _, v := range m {
fmt.Println(v)
} // Python Lua
}
函数
基本格式:
func 函数名(参数)(返回值) {
函数体
}
Go 语言中支持函数、匿名函数和闭包,并且函数在 Go 语言中属于“一等公民”。
- 多返回值
// 多返回值
func function13(a int, b int) (int, int) {
return b, a
}
- 返回值命名
// 返回值命名
func function12(x, y int) (ret int) {
ret = x + y
return
}
- 变参函数
// 变参函数
func function14(nums ...int) int {
sum := 0
for _, v := range nums {
sum = sum + v
}
return sum
}
变参传递:
func function14_1() {
ret := function14([]int{1, 2, 3}...)
fmt.Print(ret) // 6
}
- 函数参数
// 函数参数
func function15(a, b int, f func(int, int) int) {
f(a, b)
return
}
- 函数变量,匿名函数
// 函数变量
func function16() {
add := func(a, b int) int {
return a + b
}
function15(1, 2, add)
}
- 函数返回值,函数闭包
// 函数返回值
func function17() func(int) int {
y := 1
return func(x int) int {
return x + y
}
}
- 递归
闭包也可以是递归的,但要求在定义闭包之前用类型化的 var 显式声明闭包。
// 递归
func function20() {
var dfs func(int) int
dfs = func(x int) int {
if x > 3 {
return 3
}
return x + dfs(x+1)
}
ret := dfs(1)
fmt.Print(ret) // 1+2+3+3 == 9
}
init 特殊的函数
程序启动时自动执行每个包的 init 函数
func init() {
fmt.Println("main init")
}
defer 语句
Go 语言中的 defer 语句会将其后面跟随的语句进行延迟处理。
在 defer 归属的函数即将返回时,将延迟处理的语句按 defer 定义的逆序进行执行,也就是说,先被 defer 的语句最后被执行,最后被 defer 的语句,最先被执行。
// defer
func function18() {
f1 := func() {
fmt.Print(1)
}
f2 := func() {
defer f1()
fmt.Print(2)
}
defer func() {
fmt.Print(3)
defer f2()
}() // 321
return
}
Go 函数中 return 语句在底层并不是原子操作,它分为给返回值赋值和 RET 指令两步。
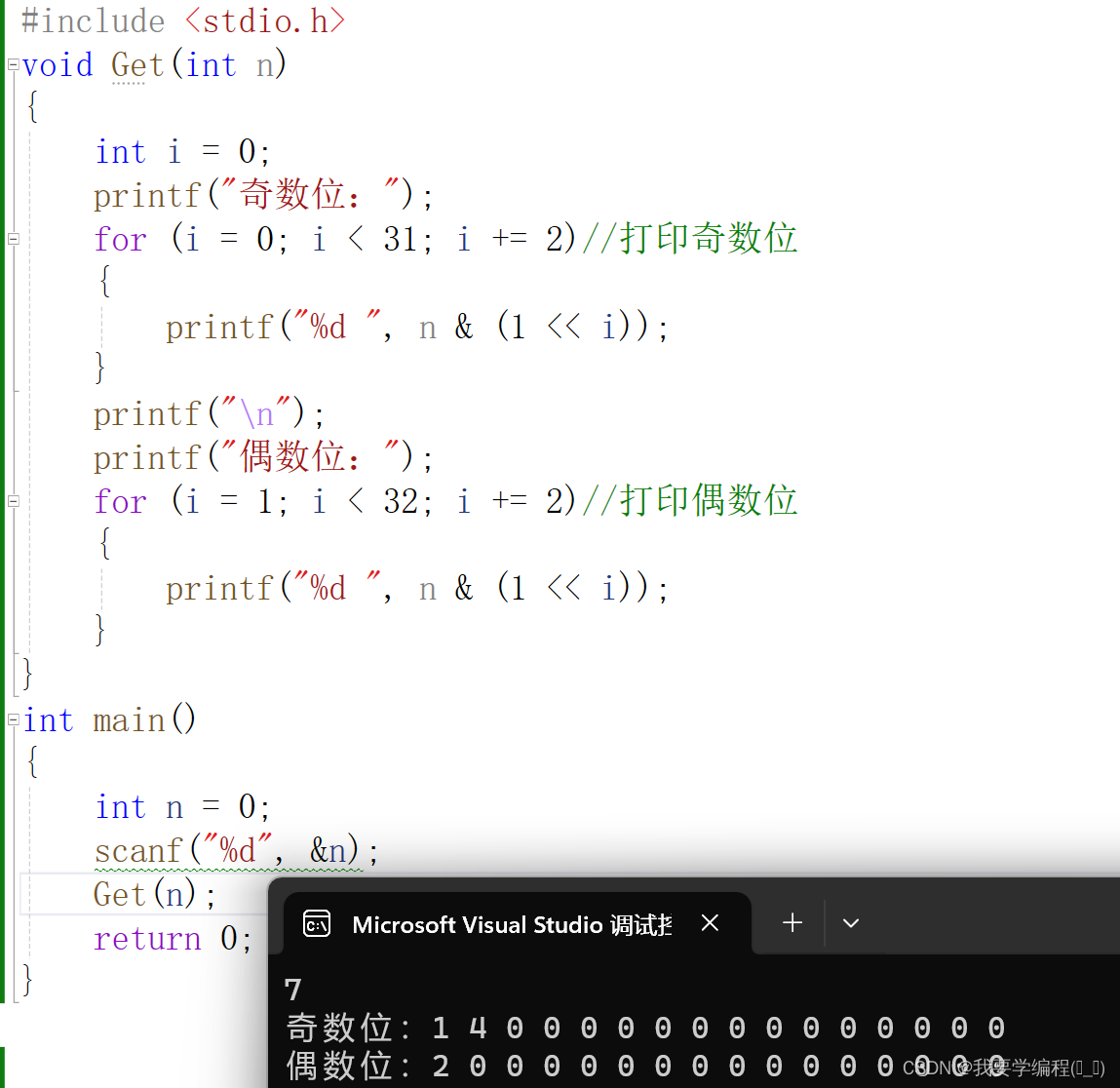
而 defer 语句执行的时机就在返回值赋值操作后,RET 指令执行前。如下图所示:(参考)
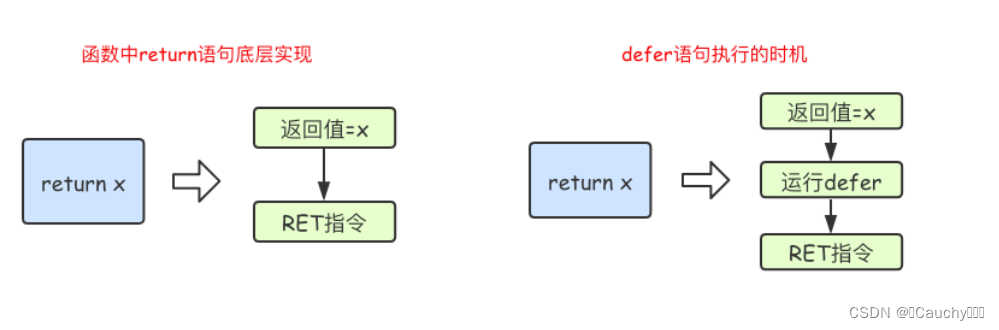
defer注册要延迟执行的函数时该函数所有的参数都需要确定其值
func calc(index string, a, b int) int {
ret := a + b
fmt.Println(index, a, b, ret)
return ret
}
func function19() {
x := 1
y := 2
defer calc("AA", x, calc("A", x, y))
x = 10
defer calc("BB", x, calc("B", x, y))
y = 20
}
A 1 2 3
B 10 2 12
BB 10 12 22
AA 1 3 4
panic / recover 错误处理
panic 的一种常见用法是:当函数返回我们不知道如何处理(或不想处理)的错误值时,中止操作。
recover 可以阻止 panic 中止程序,并让它继续执行。
举例:
当其中一个客户端连接出现严重错误,服务器不希望崩溃。 相反,服务器希望关闭该连接并继续为其他的客户端提供服务。
注意:
- 必须在
defer的函数中调用recover,不可以直接defer recover() defer一定要在可能引发panic的语句之前定义
// panic, recover
func function21() {
defer func() {
if err := recover(); err != nil {
fmt.Println("recover err:", err)
}
}() // recover err: function error!
func() {
panic("function error!")
}()
fmt.Println("After panic") // 不会执行
}
当跳出引发 panic 的函数时,defer 会被激活, 其中的 recover 会捕获 panic,并且 recover 的返回值是在调用 panic 时抛出的错误。
最后一行代码不会执行,因为 main 程序的执行在 panic 点停止,并在继续处理完 defer 后结束。
类型
- 类型定义
语法规则:type NewType SourceType
类型定义定义了全新类型,该类型与源类型底层类型相同。
- 类型别名
语法规则:type TypeAlias = Type
类型别名和其源类型本质上同属一个类型。
// 类型定义,类型别名
func function22() {
type MyInt int // 类型定义
var a int = 1
var b MyInt
b = MyInt(a) // 必须显示转换
fmt.Printf("%T\n", b) // main.MyInt
type MyFloat = float32 // 类型别名
var A float32 = 0.1
var B MyFloat
B = A // 只是别名,本质同属一个类型
fmt.Printf("%T\n", B) // float32
}
从上述输出结果来看,类型定义是表示 main 包下定义的类型 MyInt,而类型别名仍然是源类型,类型别名只存在源代码中,编译时会自动替换为原来的类型。
结构体
基本格式:
type 类型名称 struct {
字段名称 字段类型
}
在声明结构体字段时,也可以指定标签 tag,形如 key1:"value1" key2:"value2",并且需要用反引号包裹。标签信息可以在程序运行时通过反射机制被读取,比如被用于在结构体变量和 JSON 数据之间转换时,通过 tag 建立联系。
// 结构体
type Info struct {
Email string
Phone string
}
type Person struct {
ID int64 `json:"id" form:"id"` // tag 标签
Name string
Contact Info
}
- 结构体不能包含自己,但可以包含它的指针类型
type Node struct {
val int
next *Node
}
- 结构体初始化
func function23() {
a := Info{
Email: "123@163.com",
Phone: "123456",
}
// 结构体简单,按顺序初始化
b := Info{
"456@163.com",
"987654",
}
fmt.Printf("%T %T\n", a, Person{}) // main.Info main.Person
fmt.Println(a, b) // {123@163.com 123456} {456@163.com 987654}
}
- 匿名结构体
func function24() {
a := struct {
x, y int
}{
1, 2,
}
fmt.Println(a) // {1 2}
}
- 结构体嵌套
func function27() {
type Student struct {
Name string
Info // 结构体嵌套
}
var a Student
a = Student{
Name: "Cauchy",
Info: Info{
Email: "123@163.com",
Phone: "123456",
},
}
fmt.Println(a.Name, a.Email, a.Phone) // Cauchy 123@163.com 123456
}
- 自定义结构体构造函数
一般结构体较为复杂,则可以使用返回指针对象。
// 自定义结构体构造函数
func NewInfo() *Info {
return &Info{
Email: "123@163.com",
Phone: "123456",
}
}
func function29() {
a := NewInfo()
fmt.Println(a) // &{123@163.com 123456}
}
内存对齐
内存对齐同 C++ 语言类似,不过多阐述。
需要注意的是,一个空的结构体不占用内存空间,但是当一个结构体最后一个字段是空结构体,编译器会额外填充 1 字节。
func function25() {
fmt.Println(unsafe.Sizeof(struct{}{})) // 0
type structA struct {
A int8 // 1 byte
B struct{} // 0 byte
}
var a structA
fmt.Println(unsafe.Sizeof(a)) // 2
}
这是为了防止对结构体最后一个零内存占用字段进行取地址操作时发生越界,而空结构体不放最后一个字段,不会额外填充。
当然,额外填充一字节也是会进行内存对齐的,unsafe.Alignof 返回变量的对齐要求:
func function26() {
type structA struct {
A int32 // 4 byte
B struct{} // 0 byte
}
var a structA
fmt.Println(unsafe.Sizeof(a), unsafe.Alignof(a)) // 8 4
}
JSON 序列化与反序列化
利用 encoding/json 包的 json.Marshal 和 json.Unmarshal 进行序列化和反序列化。
// JSON
func function28() {
type Phone struct {
Price int `json:"price"`
Name string `json:"name"`
}
s := Phone{
Price: 3888,
Name: "小米",
}
s1, _ := json.Marshal(s) // JSON 序列化
fmt.Printf("%s\n", s1) // {"price":3888,"name":"小米"}
var a Phone
_ = json.Unmarshal(s1, &a) // JSON 反序列化
fmt.Println(a) // {3888 小米}
}
上述序列化后,字段变为了 tag 定义的名称 price 和 name。
方法和接收者
Go 允许为特定的变量设置专用的函数,这个专用的函数被称为方法(method)。通过方法接收者(receiver)来绑定方法和对象,接收者类似于 this、self。
方法声明
func (接收者 接收者类型) 方法名(参数) (返回值) {
方法体
}
-
建议接收者类型名称为首字母小写
-
接收者类型:值接收者、指针接收者
- 函数传参都是值拷贝,实参体积较大或函数内部需要修改实参,需要传递实参地址(指针)
- 保持一致性。一个类型的某个方法使用了指针接收者,那么该类型其他方法应该保持一致
-
通过结构体嵌套进行组合,实现面向对象的继承
-
Go 的语法糖
.运算符,如果是指针,则会自动获取变量的地址
Go 通过内嵌其他结构体进行组合,每个被嵌入的结构体均会为其提供一些方法。当进行方法调用,会先查找当前结构体中是否声明了该方法,没有则依此去内嵌字段的方法中查找。
type Course struct {
Name string
Score int8
}
// 值接收者
func (c Course) getName() string {
return c.Name
}
// 指针接收者
func (c *Course) setScore(score int8) {
c.Score = score
}
type Math struct {
People int8
Course
}
func function30() {
m := Math{
People: 36,
Course: Course{
Name: "math",
Score: 100,
},
}
fmt.Println(m.Course.Name, m.Score) // math 100
m.setScore(120)
fmt.Println(m.Course.getName(), m.Course.Score) // math 120
}
通过类型定义,声明一个新的类型,再为其声明方法。
- 不支持为其他包的类型声明方法
- 不支持为接口类型和基于指针定义的类型定义方法
type MyBool bool
func (m MyBool) SayType() {
fmt.Printf("%T\n", m)
}
//type PtrMyBool *MyBool
//func (p PtrMyBool) SayType() {} // *MyBool' is a pointer type
func function31() {
var a MyBool
a.SayType() // main.MyBool
}
补充
Go 中根据首字母的大小写确定访问权限,无论是方法名、常量、变量名还是结构体的名称。
- 首字母大写,则可以被其他的包访问
- 首字母小写,则只能在本包中使用
可以简单的理解:首字母大写是公有的,首字母小写是私有的。


![[AI]文心一言爆火的同时,ChatGPT带来了这么多的开源项目你了解吗](https://img-blog.csdnimg.cn/direct/1ceb3fd255254ceeaa91ded1c5c1ddba.png)