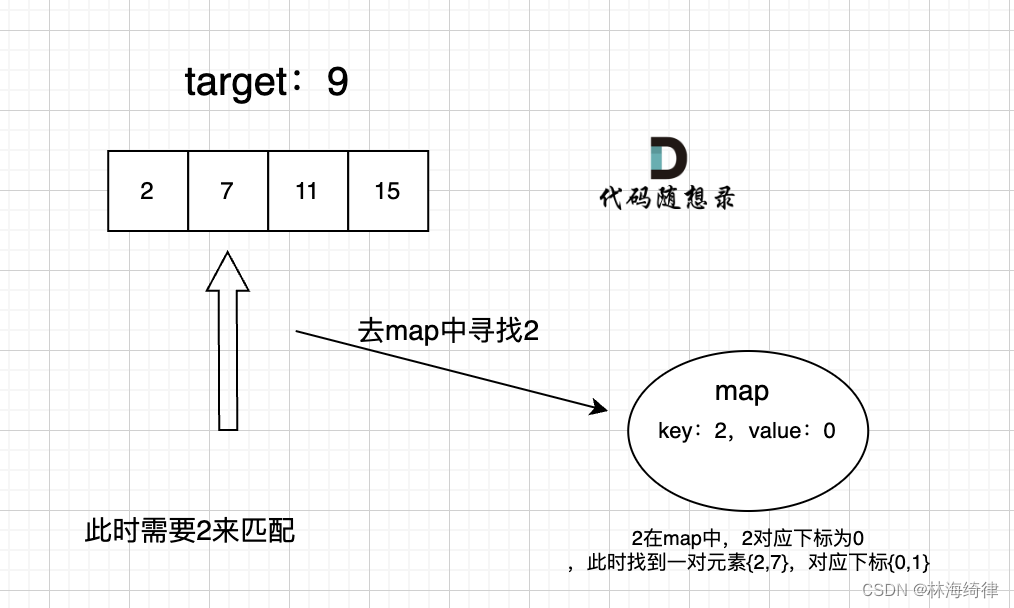
CoCa3D
- 摘要
- 引言
- Collaborative Camera-Only 3D Detection
- Collaborative depth estimation
- Collaborative detection feature learning
- 实验
- 结论和局限
摘要
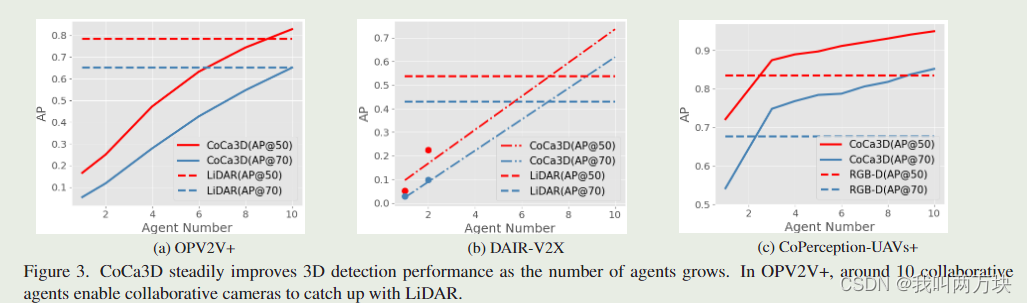
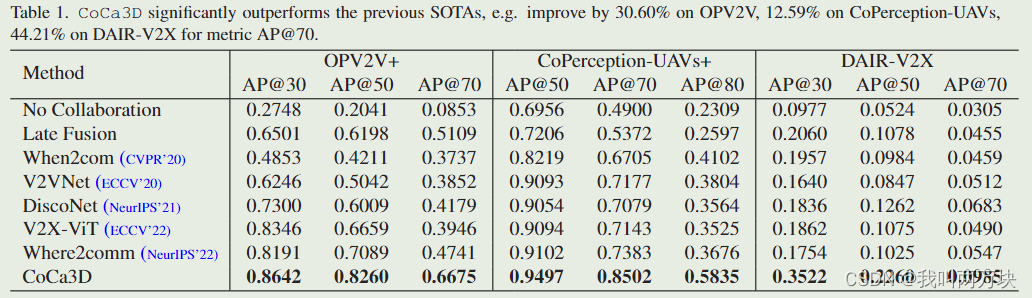
与基于 LiDAR 的检测系统相比,仅相机 3D 检测提供了一种经济的解决方案,具有简单的配置来定位 3D 空间中的对象。然而,一个主要的挑战在于精确的深度估计,因为输入中缺乏直接的3D测量。许多以前的方法试图通过网络设计来改进深度估计,例如可变形层和更大的感受野。这项工作提出了一个orthogonal direction,通过引入多智能体协作来改进仅相机的 3D 检测。我们提出的仅协作相机的 3D 检测 (CoCa3D) 使代理能够通过通信相互共享互补信息。同时,我们通过选择信息量最大的线索来优化通信效率。来自多个视点的共享消息消除了单智能体估计深度的歧义,并补充了单智能体视图中被遮挡和远程区域。我们在一个真实的数据集和两个新的模拟数据集上评估 CoCa3D。结果表明,CoCa3D 在 DAIR-V2X 上比之前的 SOTA 性能提高了 44.21%,OPV2V+ 提高了 30.60%,CoPerception-UAV+ 提高了 1.59%,AP@70。我们的初步结果表明,在有足够的协作的情况下,相机可能会在某些实际场景中过度接受 LiDAR。我们发布了数据集和代码。
引言
在本文中,我们提出了一个orthogonal direction,通过引入多智能体协作来提高仅相机的3D检测性能。假设在先进的通信系统的支持下,只配备摄像头的多个代理可以相互共享视觉信息。
【orthogonal direction】是指一种与现有方法不同的方法或方向。在这篇论文中,作者提出了一种通过引入多智能体协作来提高相机仅3D检测性能的正交方向。这种方法与现有的基于网络设计的方法不同,通过允许智能体共享互补信息,从而提高3D检测性能。
这将带来三个突出的好处。
- 首先,来自多个代理的不同视点可以在很大程度上解决仅相机3D检测中的深度模糊问题,从而在深度估计方面与昂贵的激光雷达弥补差距。
- 其次,多智能体协作避免了单智能体3D检测中不可避免的局限性,如遮挡和长距离问题,并有可能实现更全面的3D检测;即检测3D场景中存在的所有对象,包括超出视觉范围的对象。由于激光雷达的视场也有限,这可能使协作相机的性能优于激光雷达。
- 第三,由于相机比激光雷达便宜,大型车队的总费用显著降低。
然而,多智能体协作也带来了新的挑战。与许多多视角几何问题不同,这里我们还必须关注通信带宽限制。因此,每个代理都需要选择信息量最大的线索来共享。
根据这一设计原理,我们提出了一种新的协作式纯相机3D检测框架CoCa3D。它包括三个部分:
- i)单智能体仅摄像头的三维检测,实现了对每个智能体的基本深度估计和三维检测;
- ii)协作深度估计,其通过促进跨多个代理的视点的空间一致性来消除所估计的深度的歧义;
- iii)协同检测特征学习,其通过彼此共享关键检测消息来补充检测特征。
我们的主要贡献:
- 我们提出了一种新的协作式仅摄像头3D检测框架CoCa3D,它通过多智能体协作提高了摄像头的检测能力,促进了更全面的3D检测。
- 我们提出了核心通信高效协作技术,该技术探索空间稀疏但关键的深度信息,并通过融合来自不同视角的互补信息来解决深度模糊、遮挡和长期问题,实现更准确和完整的3D表示。
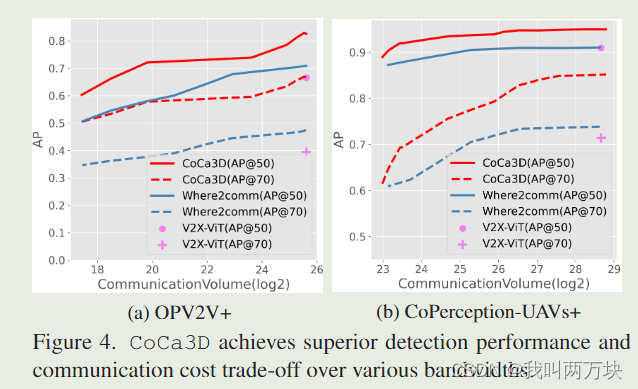
- 我们用更多的代理扩展了之前的两个协作数据集,并进行了广泛的实验,验证了i)CoCa3D在OPV2V+和DAIR-V2X上显著弥合了相机和激光雷达之间的性能差距;以及ii)CoCa3D实现了最先进的性能-带宽折衷。
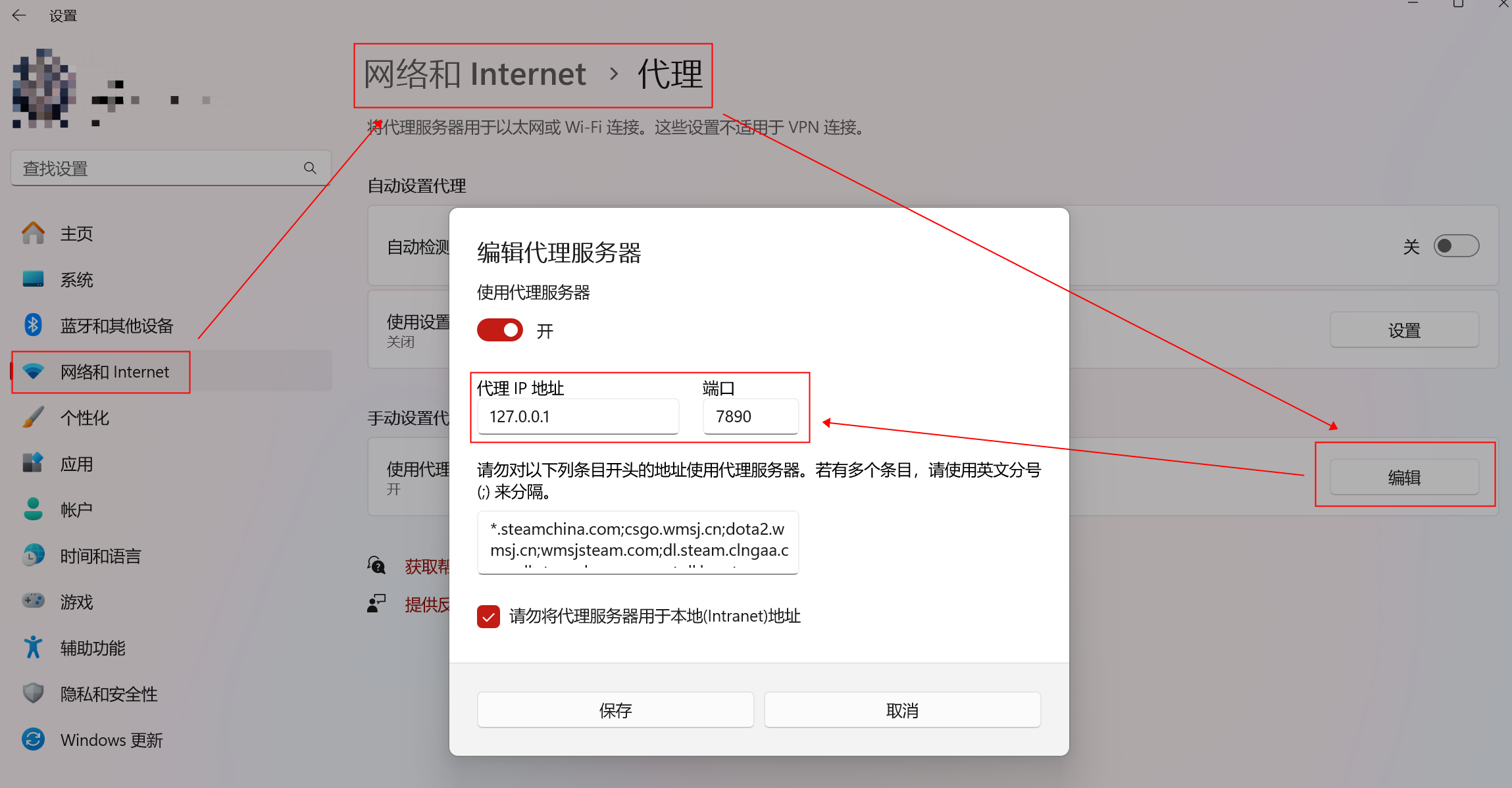
Collaborative Camera-Only 3D Detection
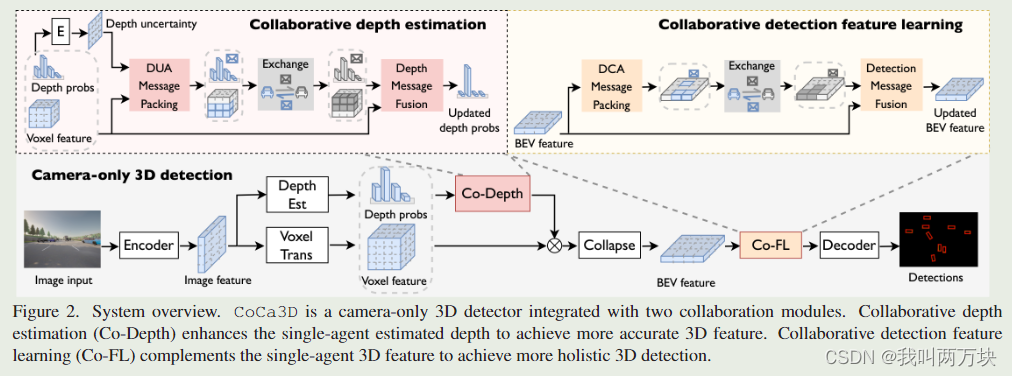
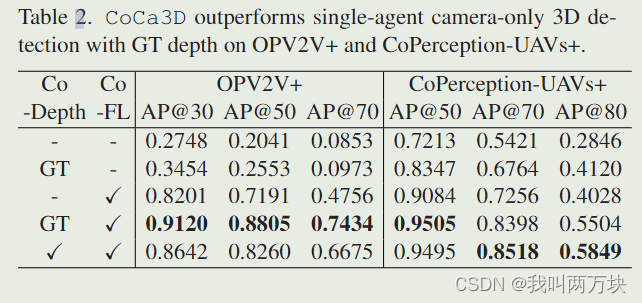
【CoCa3D是一个只有摄像头的3D探测器,集成了两个协作模块。协同深度估计(Co-Depth)增强了单智能体估计深度,以获得更准确的3D特征。协同检测特征学习(Co-FL)是对单智能体3D特征的补充,可以实现更全面的3D检测。】
我们的设计思路来自两个方面:
- 第一,由于摄像头和LiDAR的主要差距是深度,所以信息中应该包含深度信息。这将允许来自多个代理的不同观点消除无限深度可能性的歧义并定位正确的深度候选。
- 其次,消息中应该包含检测线索,以提供互补的检测信息,这可以从根本上克服单智能体检测不可避免的局限性,如遮挡和远程问题。
Collaborative depth estimation
协同深度估计(Co-Depth)的目标是消除单智能体相机深度估计中无限深度可能性的歧义,并通过多视图一致性定位正确的候选深度。直觉是,对于正确的深度候选,其对应的3D位置应从多个智能体的视点在空间上保持一致。为此,各个agent可以通过通信交换深度信息。同时,我们通过选择最关键、最明确的深度信息来提高通信效率。因此,Co-Depth包括:
-
a)深度不确定性感知的消息打包,它将具有明确深度信息的紧凑消息打包;
【深度不确定性感知报文封装(DUA)基于深度不确定性将用于多视图一致性的最关键深度信息打包到待发送报文中。深度信息包括:i)体素特征,用于多视图视觉相似性测量;ii)深度概率,表示特征像素属于体素的置信度,用于多视图候选选择。】 -
b)深度信息融合,利用接收到的深度信息增强深度估计
【深度信息融合的目标是在多个智能体不同视点接收深度信息的情况下增强深度估计。直觉是,对于一个正确的深度候选,多个代理在同一3D点观察到的视觉特征应该是相似的。为了实现这一点,我们引入了多视图深度一致性加权(匹配分数)。】
Collaborative detection feature learning
协作深度估计仔细地细化了深度,并为每个单个代理提供了更准确的3D表示。然而,单智能体的物理局限性,如视野受限、遮挡和远程问题仍然存在。为了实现更全面的三维检测,各个agent应该能够交换三维检测特征并利用互补信息。同时,我们通过选择感知上最关键的信息来提高沟通效率。因此,协同检测特征学习(Co-FL)包括:
- a)检测置信度感知的消息打包,即在检测置信度的指导下对空间稀疏但感知上至关重要的3D特征进行打包;
【检测置信度感知(DCA)消息打包的目标是将互补的感知信息打包成一个紧凑的消息。其核心思想是探索感知信息的空间异质性。直觉是,包含对象的区域比背景区域更重要】 - b)检测信息融合,利用接收到的检测信息增强三维特征。
【这里我们通过聚合从其他代理接收到的检测消息来增强每个代理的检测特征。我们用简单而有效的非参数逐点最大融合实现了这一点。】
实验
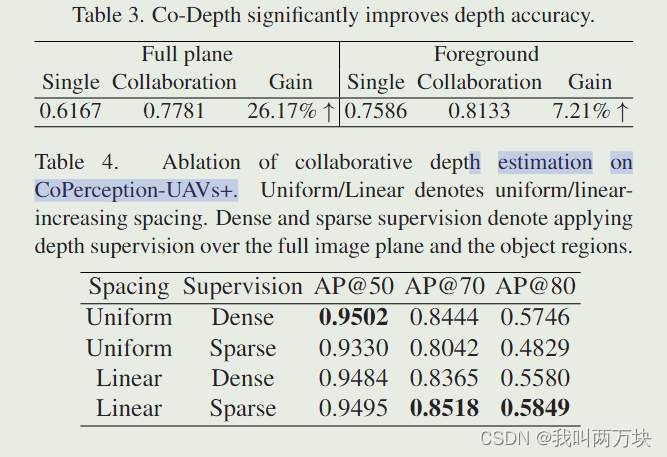

结论和局限
我们提出CoCa3D,一种新颖的协作相机3D检测,接近整体3D检测。其核心思想是引入多智能体协作来提高摄像机的检测能力。同时,对通信成本进行优化,每个agent仔细选择空间稀疏但深度关键的消息进行共享。广泛的实验涵盖了现实世界和模拟场景,以及多种类型的代理(汽车,无人机和基础设施),表明CoCa3D不仅实现了最先进的感知带宽权衡,而且在OPV2V+上超过了基于lidar的探测器,具有足够数量的协作代理。
局限性和未来的工作:收集真实世界的多智能体感知数据集是非常昂贵的。到目前为止,DAIRV2X是唯一一个公开的真实世界数据集,它只有一辆车和一个路边单元。本工作主要利用仿真数据来验证所提出的新方法,并勾画出一个有前景的研究方向。我们提倡为真实世界的数据收集提供更多的资源