你ping一下,服务器累成狗-目录篇文章浏览阅读1.7k次,点赞65次,收藏20次。我们的电脑怎么干活的https://blog.csdn.net/u010187815/article/details/135796967
你ping一下,服务器累成狗--第一篇文章浏览阅读62次,点赞6次,收藏2次。ping的时候都干了什么https://blog.csdn.net/u010187815/article/details/135943085
简简单单
简简单单的一个ping动作,中间涉及的内容几乎包含了计算机领域里面所有的基础内容,复杂而精妙。
这篇文章一次肯定写不完,最后写完了肯定也不可能包含所有的内容。我对其中的一些内容也早就忘的干净,不过既然写了,就认真写,能写多少写多少,能写多细写多细,并且尽量表达的通俗易懂一点,有哪里不对的地方,别打我,跟我说,我会改。
先上一个大致的流程图,后面也会按照这图里的四个点分开讲
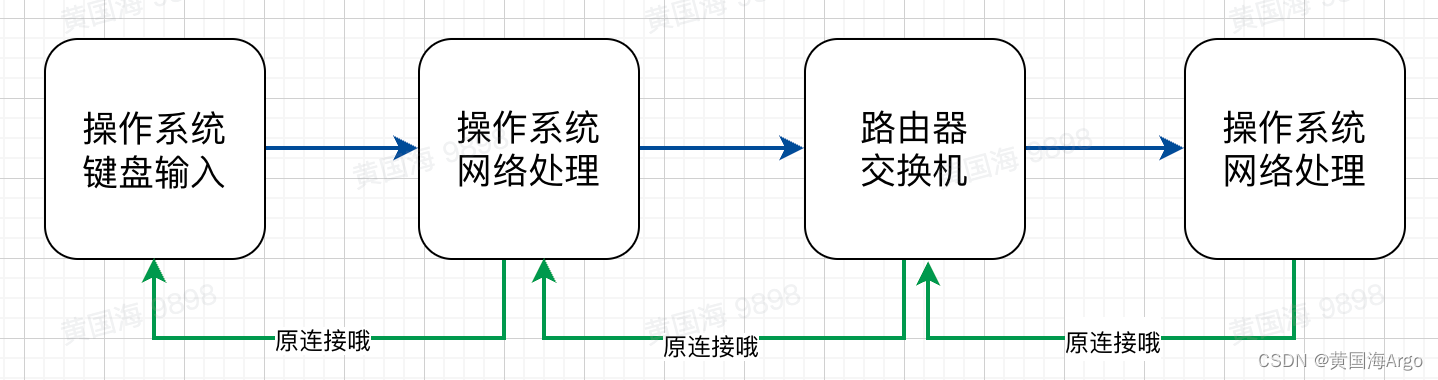 从用户程序到内核执行
从用户程序到内核执行
概述
执行ping命令时,操作系统会创建一个进程,分配一个PID,分配相应的资源,比如内存空间,CPU时间片,文件描述符,网络端口等,这个和执行普通的应用程序没有什么区别。
同样ping命令和普通的应用程序也都需要通过一些系统调用来让内核帮他做一些事情,应为进程正常是在用户空间运行,在用户空间里面,应用程序可以使用的系统资源和系统功能是非常受限的。
进程通过系统调用可以接触到操作系统底层的很多能力,比如:
- 文件操作:open、close、read、write、lseek、stat、fstat、mkdir、rmdir、unlink等。
- 进程管理:fork、exec、exit、wait、waitpid、getpid、getppid、kill、signal等。
- 进程间通信:pipe、shmget、shmat、shmdt、semget、semop、msgget、msgsnd、msgrcv等。
- 网络通信:socket、bind、listen、accept、connect、send、recv、select、poll等。
- 内存管理:brk、mmap、munmap、mprotect、malloc、free等。
- 时间和日期:time、gettimeofday、clock_gettime、strftime等。
- 设备和I/O操作:ioctl、read、write、select等。
- 信号处理:signal、sigaction、kill、sigprocmask等。
- 用户和组管理:getuid、getgid、geteuid、getegid、setuid、setgid等。
可以说进程的很多核心的能力都需要通过系统调用来“陷入内核”,让内核帮忙执行。
分配进程描述符--struct task_struct
- volatile long state:进程状态,表示进程当前的运行状态,例如运行、等待、睡眠等。
- void *stack:进程的内核栈指针。
- struct thread_info *thread_info:指向线程信息的指针。
- struct task_struct *parent:指向父进程的task_struct结构。
- struct list_head children:指向子进程链表的头结点。
- struct list_head sibling:指向同一父进程的兄弟进程链表。
- struct pid_struct *pid:进程ID相关的结构体指针。
- struct cred *real_cred:指向实际用户凭证的指针。
- struct cred *cred:指向当前任务用户凭证的指针。
- struct file *files:文件描述符表的头指针。
- struct signal_struct *signal:进程的信号处理相关信息。
- struct mm_struct *mm:指向进程的内存管理结构。
- struct cpu_struct cpu:表示进程所在CPU的信息。
- struct nsproxy *nsproxy:用于多个命名空间的进程间共享的命名空间信息。
- struct timer_list real_timer:进程的实时定时器。
- struct timer_list virt_timer:进程的虚拟定时器。
- struct kernel_vm86_regs vm86:VM86模式的寄存器信息。
- unsigned long flags:进程的标志位。
- char comm[TASK_COMM_LEN]:进程的名称。
- struct io_context *io_context:用于异步I/O的上下文信息。
内核会把所有的进程描述符放到一个叫任务队列的双向循环链表中。上述中第七项PID是进程的唯一标识,其类型是short类型,所以默认最大为32768,有一些特定的版本中也会用large PID(int类型)来支持4294967295个进程。
创建后的进程经过短暂的创建状态后(会阻止内核将时间片分给它),就会进入Task_Running状态(包含待运行和正在运行)。需要注意的是,如果应用程序因为执行时间片到期了,被内核切出去了,那么这时候他的状态也是Task_Running。如果进程为了等待一些事件就会进入Task_Interruptible或Task_Uninterruptible状态。
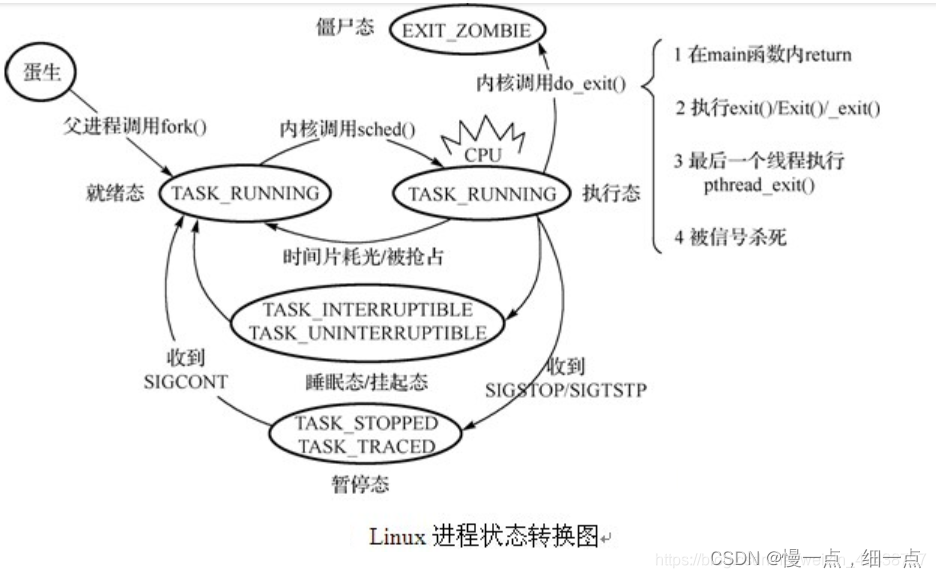
进程的创建和终结时释放资源的过程这里就不阐述了,各位可以网上自己查查。
进程调度
从进程进入Task_Running状态后,就可以接受调度程序为他分配的时间片了,让它可以真正的运行起来。至于怎么调度,完全取决于调度程序的实现。有一点需要区分于硬件硬件的处理,上一篇中我们讲到中断处理程序自身一旦执行是不可中断的。而在进程调度中,会按照优先级和分配的时间片去中断当前的在CPU执行的进程。这个时候就会有进程上下文的概念。先来看看两种调度算法
调度算法
O(1)调度算法:
核心思想:
将进程的调度决策与其优先级相关联,每个进程都被分配一个动态优先级,该优先级的范围通常是0-139,数值越低代表优先级越高。进程的优先级可以在运行时根据其运行情况进行调整。
O(1)调度算法中,进程的状态被分为两个就绪队列:活动队列(Active Queue)和过期队列(Expired Queue)。活动队列中包含了当前正在运行的进程,而过期队列中包含了已经运行一段时间的进程。
算法的主要步骤如下:
- 初始化活动队列和过期队列,并设置时间片(time slice)。
- 从活动队列中选择一个进程来运行。这个选择是基于进程的优先级来进行的,优先级越高的进程被选择的概率越大。
- 当一个进程的时间片用完后,它将被移动到过期队列,同时分配一个新的时间片。
- 在过期队列中选择一个进程,并将其移到活动队列中运行。
- 当活动队列为空时,活动队列和过期队列交换位置,过期队列变为活动队列,继续执行步骤2-4。
- 如果没有可运行的进程,调度器将选择一个最高优先级的空闲进程来执行。
O(1)调度算法的主要优点
其调度决策具有常数时间复杂度,不会随着进程数量的增加而变慢。它还可以根据系统负载动态地调整进程的优先级,以提高系统的整体性能。
O(1)调度算法的主要缺点
由于其调度决策是基于优先级而不是实际执行时间的,可能存在某些进程一直处于低优先级导致无法运行的情况。此外,O(1)调度算法不能很好地适应多核系统和对对称多处理机(SMP)的需求。
CFS调度算法
核心思想:
基于"虚拟运行时间"来进行调度决策。每个进程被分配一个虚拟运行时间片(virtual runtime),它表示进程在CPU上运行的预期时间。系统根据这个虚拟运行时间来决定下一个要运行的进程,以保证进程获得公平的CPU时间。
CFS调度算法的主要步骤如下:
- 初始化CFS调度器,并设置根任务(root task)的虚拟运行时间片。
- 当有进程需要运行时,CFS调度器选择根任务中虚拟运行时间片最低的子任务(即虚拟运行时间最小的进程)作为下一个要运行的进程。
- 选定进程后,CFS调度器将更新进程的虚拟运行时间,并分配给它一个时间片(也称为时间配额),该时间片与进程的优先级成比例。
- 运行过程中,CFS调度器会根据进程的运行时间和虚拟运行时间的差异,动态地调整进程的虚拟运行时间和时间片的长度。
- 当一个进程的时间片用完后,CFS调度器将重新选择一个虚拟运行时间最低的进程作为下一个要运行的进程,并分配时间片给它。
- 如果没有可运行的进程,CFS调度器将选择一个最高优先级的空闲进程来执行。
CFS调度算法的主要优点:
能够提供公平的CPU资源分配,确保每个进程获得相等的CPU时间。它通过虚拟运行时间和时间片的动态调整,可以适应不同进程的运行需求,并提供比较低的延迟和响应时间。
CFS调度算法也支持实时进程的调度,通过提供一个确切的实时进程时间的机制,以确保实时进程能够在特定时间内获得CPU时间。
进程的优先级怎么定
知道了调度算法,我们就需要知道调度算法是根据什么来给应用程序分配时间片的,无论是优先级的绝对值,相对值或者百分比。
进程定义优先级分两种类型,
一种是nice值,这种值使用在普通进程上,范围是-20到+19。值越大表示优先级越低。
另一种是实时优先级,范围值是0到99。值越大表示优先级越高。
进程上下文的由来
当进程A的某次的时间片用完主动释放时或者被其他更高优先级的进程B,C等强行抢占或者需要调用系统能力的时候,就需要将当前的进程的信息上下文信息,并加载下一个进程的上下文信息。主要是用来恢复进程的运行。

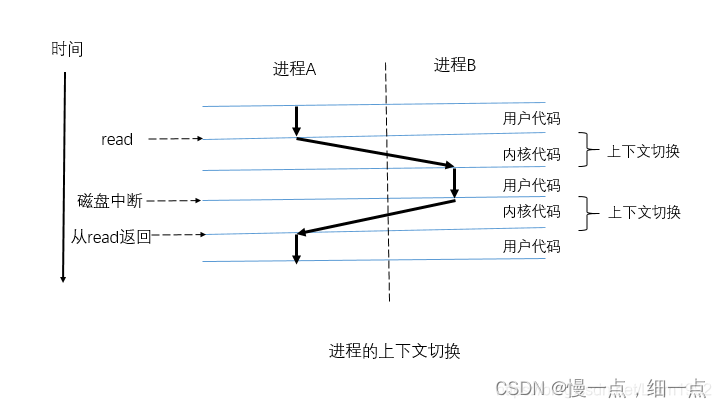
其他两种的就不说明了,主要来说说什么是系统调用
ping里面的系统调用
执行ping命令时,涉及了以下系统调用:
- socket:创建一个套接字,用于与目标主机建立网络连接。
- sendto:将ping请求发送给目标主机的IP地址。
- recvfrom:接收目标主机返回的ping响应。
- gettimeofday:获取当前时间,用于计算ping命令的延迟。
- setsockopt:设置套接字选项,如超时时间等。
- close:关闭与目标主机的连接。
所谓的系统调用就是操作系统中有一些能力是不能被用户空间直接访问的,这时候就需要通过系统调用来让内核帮忙执行。上一文中我们讲了硬件是通过向内核注册的中断处理程序来响应的,而应用程序则是通过系统调用让内核代替用户程序去执行动作。
一般来说,应用程序通过触发一个内核级别的特殊的异常来触发某个系统调用,这个异常会有指定的异常处理程序一般只system_call。
ICMP报文的组装
网络协议层间的处理和传递:ping命令使用的是ICMP协议,在网络协议栈中,操作系统会将ping命令封装为一个ICMP数据报,并通过网络接口发送出去。在传输过程中,操作系统会根据IP地址和MAC地址进行路由选择,并在每一层协议中添加相应的头部信息。
在数据链路层:在以太网、Wi-Fi等物理网络接口层,ICMP报文作为数据负载被封装在一个数据帧中。数据帧的头部包含了目标MAC地址和源MAC地址等信息。
在网络层:ICMP报文被封装在IP数据报中,IP数据报的头部包含了目标IP地址和源IP地址等信息。此外,IP数据报的协议字段(Protocol)标识为ICMP,以指示IP层将数据报交付给上层的ICMP协议进行处理。
在传输层:对于ICMP报文,它并没有在传输层上添加额外的头部信息。这是因为ICMP协议是网络层的一部分,直接封装在IP数据报中,在传输层上没有进行额外的封装。
简化的报文如下
Ethernet II(以太网帧)
- 目标MAC地址:01:23:45:67:89:ab
- 源MAC地址:de:ad:be:ef:12:34
- 类型:IPv4 (0x0800)
IPv4(IP数据报)
- 版本:IPv4
- 首部长度:20字节
- 总长度:84字节
- 标识:0x1234
- 标志(Flags):0x00
- 分片偏移:0
- 生存时间(TTL):64
- 协议:ICMP (1)
- 源IP地址:192.168.0.1
- 目标IP地址:8.8.8.8
ICMP(ICMP Echo Request报文)
- 类型:Echo Request (8)
- 代码:0
- 校验和:0x1234
- 标识符(Identifier):0x5678
- 序列号(Sequence Number):0x0001
- 数据(Payload):具体的ping命令中提供的数据部分(通常为一段字节序列)
DNS解析-替你周游了世界
如果ping命令指定了目标主机的域名,而不是直接的IP地址,操作系统会进行DNS解析,将目标主机域名转换为对应的IP地址。DNS解析过程涉及应用程序向操作系统发起系统调用(如getaddrinfo),操作系统向DNS服务器发送查询请求,接收并解析DNS响应,最终将解析到的IP地址返回给应用程序。
检查目标主机是否为IP地址。如果目标是一个IP地址,跳过DNS解析步骤。
获取目标主机的域名,例如www.baidu.com。
由于ping命令运行在操作系统中,它需要发起系统调用来执行DNS解析。在类Unix系统上,通常使用getaddrinfo()系统调用进行DNS解析。该系统调用将目标主机的域名作为输入参数,并返回一个或多个与该域名对应的IP地址。
当操作系统或应用程序发起DNS解析请求时,解析器会首先检查本地缓存,看是否已经缓存了与请求域名对应的IP地址。如果找到了匹配的缓存项,解析器会直接使用缓存中的IP地址,避免进行完整的DNS解析过程。
系统调用将查询发送给本地DNS解析器,这个解析器通常由本地网络服务提供商(ISP)或者配置的本地DNS服务器提供。解析器将查询转发给根DNS服务器。
根DNS服务器负责管理顶级域名服务器(如.com、.net、.org等)。它可能不知道目标主机的确切IP地址,但它可以指示解析器转到负责特定顶级域名的权威DNS服务器。
解析器将查询转发给负责.com顶级域名的权威DNS服务器。
权威DNS服务器具有目标主机的区域文件,其中包含与目标主机相关的DNS记录。它会查找并返回与目标主机匹配的A记录或AAAA记录(IPv6地址)。
解析器接收到响应,其中包含目标主机的IP地址。
解析器将IP地址返回给ping程序。
ping程序将使用获取的IP地址创建ICMP Echo Request报文,并开始向目标主机发送ping请求。
发送ICMP请求
在网络层中,操作系统会根据目标IP地址创建一个ICMP请求数据包,并在传输层中使用IP协议封装,然后通过网卡发送出去。
应用程序调用发送数据的系统调用(例如,send())将数据写入应用程序缓冲区。
操作系统内核会定期检查应用程序缓冲区中是否有数据需要发送。这可以通过轮询或阻塞等方式完成。
内核从应用程序缓冲区中获取数据,并将其复制到内核的网络数据缓冲区。
内核将数据分割成适当的大小(根据MTU和网络协议的要求),然后为每个数据包分配一个或多个网络缓冲区。
内核将数据包的相关信息(例如目的MAC地址、源MAC地址、目的IP地址、源IP地址、协议类型等)填充到网络数据包的头部中。
内核检查网络接口的状态,确保它处于活动状态,并将数据包传递给网络设备驱动程序。
网络设备驱动程序将数据包发送到相应的网卡(NIC)。
网卡芯片将数据包转换成电信号,并通过物理介质(例如以太网电缆)发送出去。
数据包到达目标主机后,接收端的网卡接收到数据包。
目标主机的操作系统内核接收到数据包,并将其传递给相应的网络协议栈进行处理。
拆包和粘包
由于ICMP报文比较简单,通常只包含一个报文头部和可选的数据字段。因此,ICMP报文很少会出现拆包和粘包的问题。每个ICMP报文都以独立的形式发送和接收,不会与其他报文粘在一起。
拆包和粘包是在传输层的协议栈中处理的,主要由传输层协议(例如TCP或UDP)负责。
拆包和粘包指的是在数据传输过程中,发送方将应用层数据切割成多个数据包进行发送,而接收方在接收数据时,可能会一次接收到多个数据包(粘包)或者只接收到部分数据包(拆包)的情况。
具体来说,在TCP连接中,发送方将应用层数据切分成适当的大小(根据MSS,最大报文段长度)的数据段,并在每个数据段的头部添加TCP头部信息,形成TCP数据包。接收方在接收数据时,会根据TCP头部的信息来将接收到的数据进行重组,还原为应用层数据。因此,在TCP连接中,拆包和粘包问题主要是由TCP协议负责处理的。
在UDP连接中,并没有像TCP一样的连接维护和重组机制。发送方将应用层数据直接封装成UDP数据报,每个UDP数据报都有固定的大小。接收方在接收数据时,根据每个UDP数据报的边界进行接收和处理。由于UDP是面向无连接的传输协议,因此它没有像TCP那样的流量控制和拥塞控制机制,所以拆包和粘包问题在UDP中可能更加突出。

流量控制和拥塞控制机制
流量控制
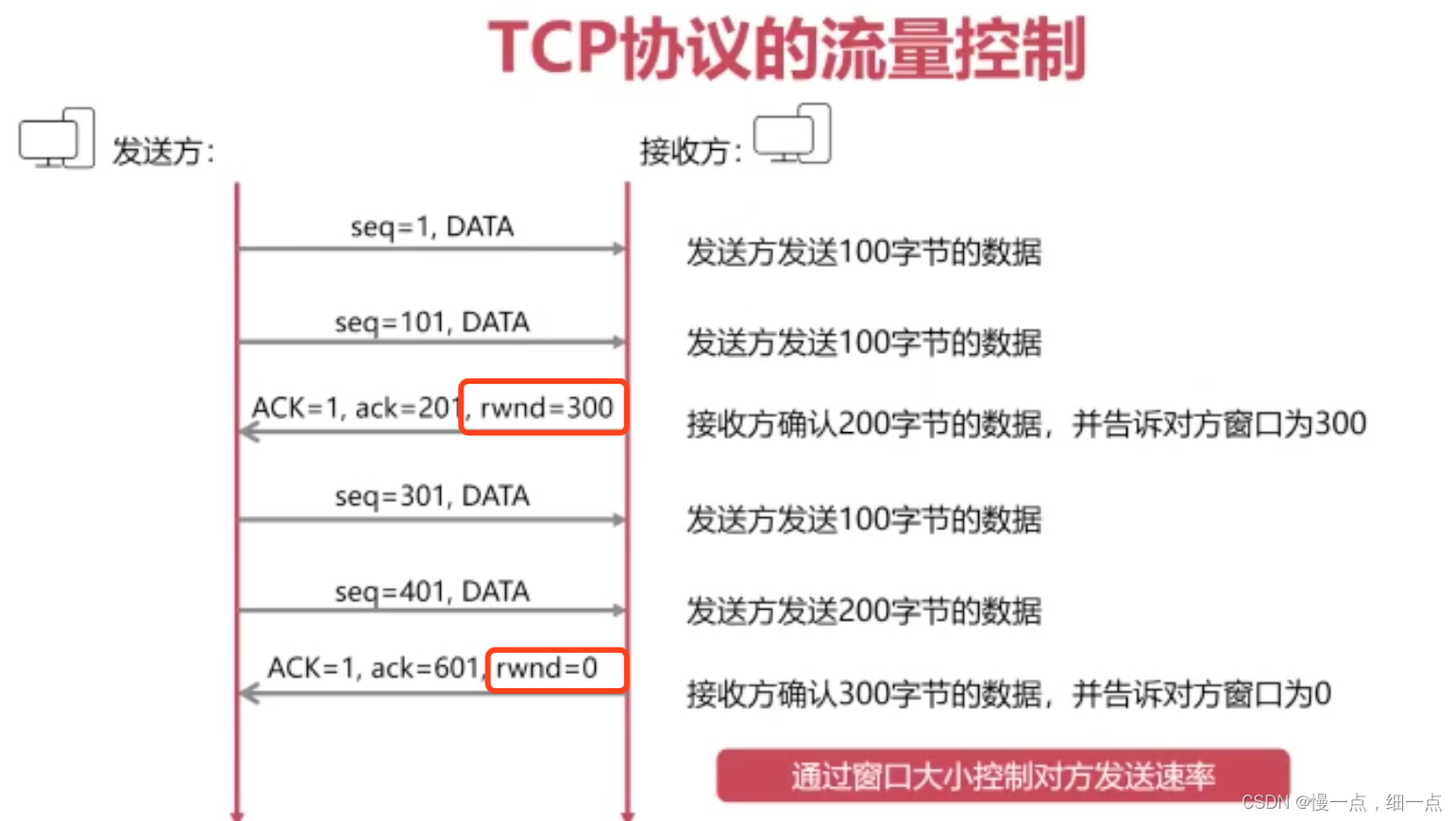
流量控制是通过接收方通知发送方的方式来控制数据的传输速率,确保接收方能够及时处理接收到的数据,避免数据丢失或溢出。TCP使用滑动窗口机制来实现流量控制。发送方根据接收方给出的窗口大小来调整发送数据的速率,窗口大小反映了接收方当前能够接收的数据量。如果窗口大小变小,发送方需要降低发送速率;如果窗口大小增大,发送方可以增加发送速率。通过不断调整窗口大小,TCP可以实现发送和接收之间的匹配,从而实现流量控制。
拥塞控制
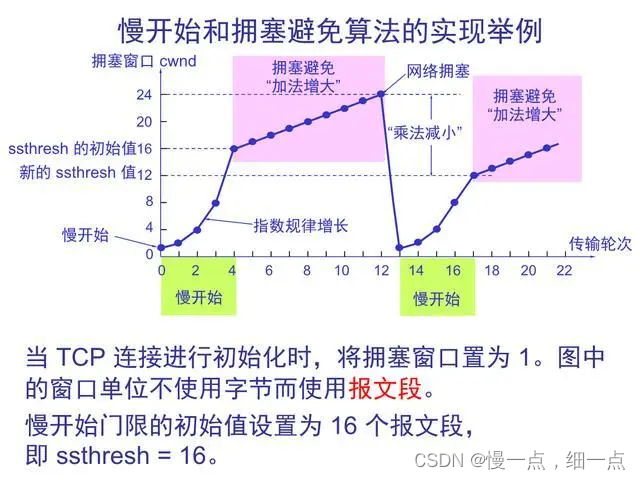
拥塞控制是为了避免网络出现拥塞而引发的性能下降和数据丢失。拥塞发生时,网络中的资源(带宽、缓存等)已经无法满足连接的需求,导致数据包丢失、延迟增加等问题。TCP通过一系列的算法来实现拥塞控制,其中包括拥塞窗口(cwnd)和慢启动、拥塞避免、快速重传、快速恢复等机制。
- 慢启动:初始发送速率较低,随着时间的增加指数级增加发送速率,以便逐步测试网络的负载能力。
- 拥塞避免:在慢启动阶段和拥塞避免阶段,发送方将指数级增加拥塞窗口,但增加速率更慢,确保在发生拥塞之前能够按照网络的容量进行发送。
- 快速重传和快速恢复:当发送方接收到三个重复的ACK时,表明有一个数据包已经丢失,发送方立即重传丢失的数据包并进行快速恢复,而不是等到超时后再进行重传,从而减少网络拥塞的程度。