文章目录
- 一、Self-Attention 各式各样的变型
- 二、How to make self-attention efficient?
- 三、Notice
- 四、Local Attention / Truncated Attention
- 五、Stride Attention
- 六、Global Attention
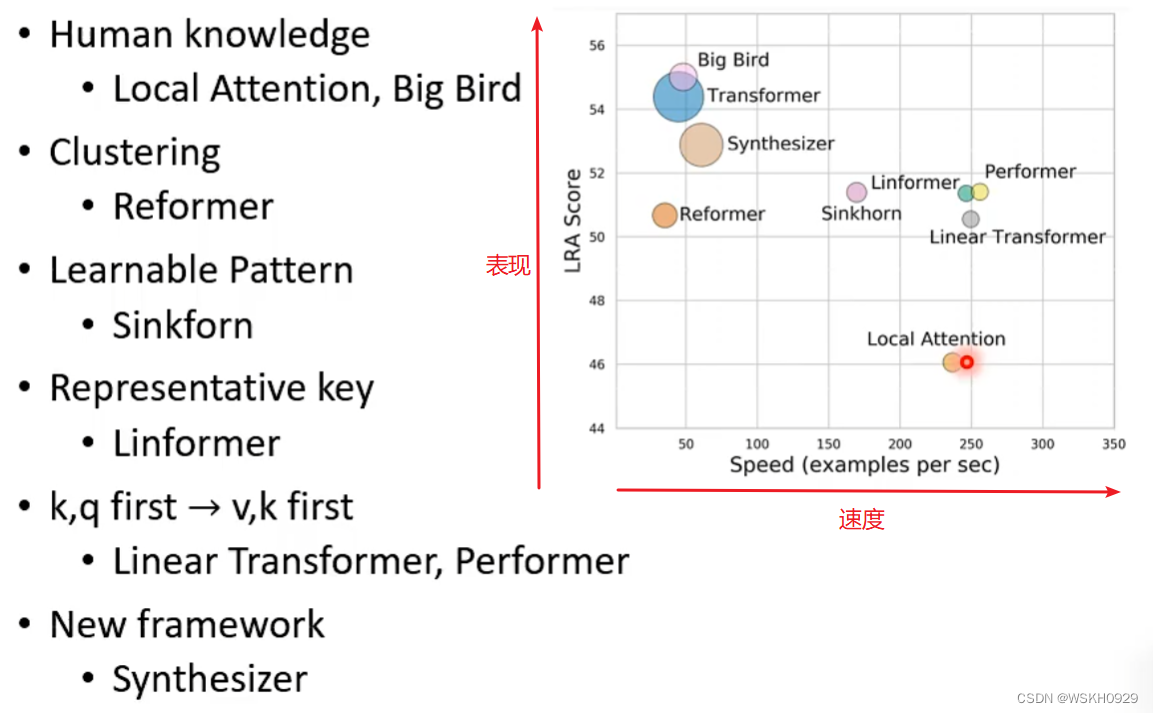
- 七、Many Different Choices
- 八、Can we only focus on Critical Parts?
- 8.1 Clustering
- 8.2 Learnable Patterns
- 九、Do we need full attention matrix?
- 十、Attention Mechanism is three-matrix Multiplication
- 十一、Do we need Q and K to compute attention?Synthesizer!
- 十二、Attention-free?
- 十三、Summary
在看这篇文章之前,我假设你已经了解了自注意力机制和多头自注意力机制的基本原理,如果你还不了解,可以先看看下面链接:
【深度学习】李宏毅2021/2022春深度学习课程笔记 - (Multi-Head)Self-Attention (多头)自注意力机制 + Pytorch代码实现
一、Self-Attention 各式各样的变型

二、How to make self-attention efficient?
将Key和Query进行点积,可以得到一个N×N的Attention Matrix,但是,当N比较大时,点积的计算量是我们无法承受的

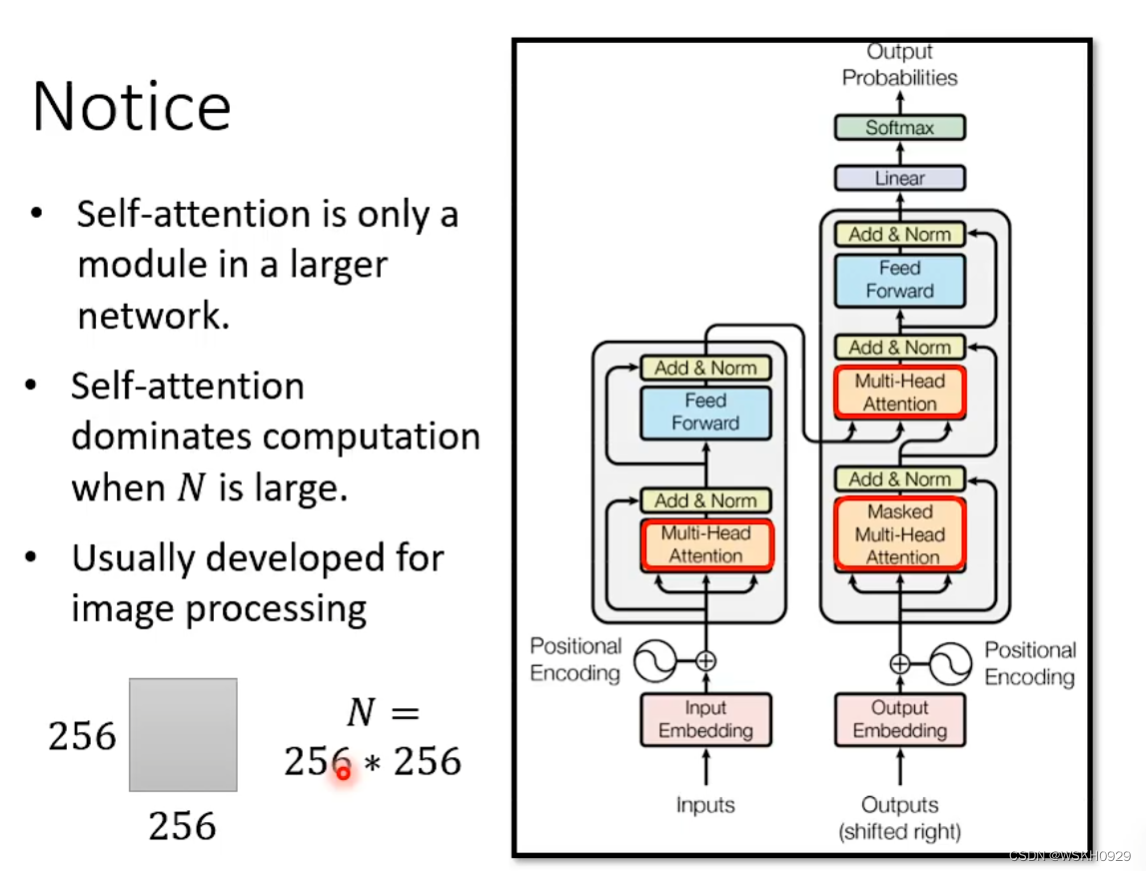
三、Notice
- Self-Attention只是神经网络里的一个Module
- Self-Attention只有当N较大时,才会Dominates整个神经网络的计算过程,也就是说,只有在N较大时,我们去加速Self-Attention才有用
- Self-Attention的各种加速技术大多数最早都使用在图像处理上。因为在图像处理里,N往往比较大,假设图片为256×256规格,那么N就是 256*256 = 65536
四、Local Attention / Truncated Attention
加速Attention计算最直觉的想法就是想办法加速Attention Matrix的计算。
Local Attention / Truncated Attention 的思想是,在计算Attention的时候,不利用整个序列的信息,而是只利用当前位置附近的一些信息进行Attention的计算(如下图,只利用了当前位置左右两边的信息进行Attention的计算)。

五、Stride Attention
和Local Attention / Truncated Attention,Stride Attention 也是只考虑部分信息计算Attention,但不同点在于 Stride Attention 是根据一定的步长去考虑信息计算Attention

六、Global Attention
如下图所示,只用其中某两个单位去和整个序列(包括自身)的其他单位进行点积计算

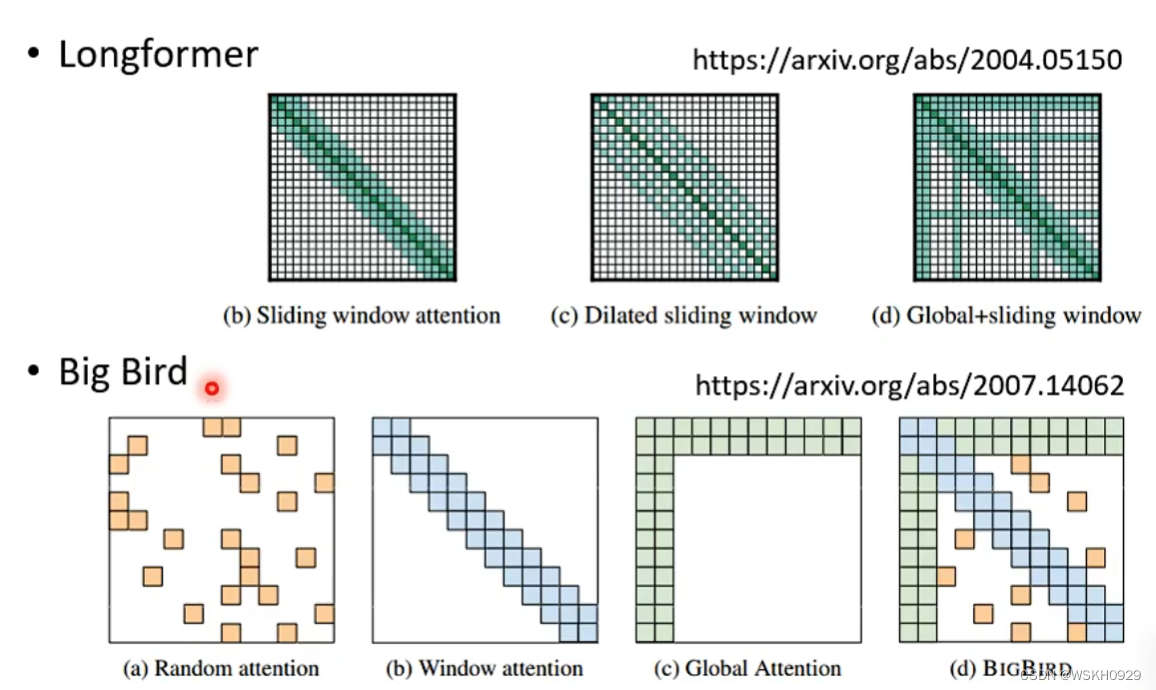
七、Many Different Choices
那么Local Attention、Stride Attention 和Gloal Attention到底用哪个呢?
答案是:可以都用!之前讲过多头注意力机制,只需要在每个头用不同的Attention就可以了呀

事实上,的确有人这么做了
八、Can we only focus on Critical Parts?
上面的方法都是通过人工的力量去确定哪些位置要计算Attention,那我们能不能通过Data Based的方法去确定呢?
8.1 Clustering
将Query和Key拼接为一个序列,然后进行聚类

然后只对属于相同类别的位置进行Attention的计算

8.2 Learnable Patterns
可以Learning另外一个神经网络来决定哪些位置要进行Attention的计算

九、Do we need full attention matrix?
实际上,Attention Matrix通常是Low Rank的,也就是说大部分列之间都是有线性关系的。所以我们可以将原本N×N的Matrix进行缩减,从而降低计算量。
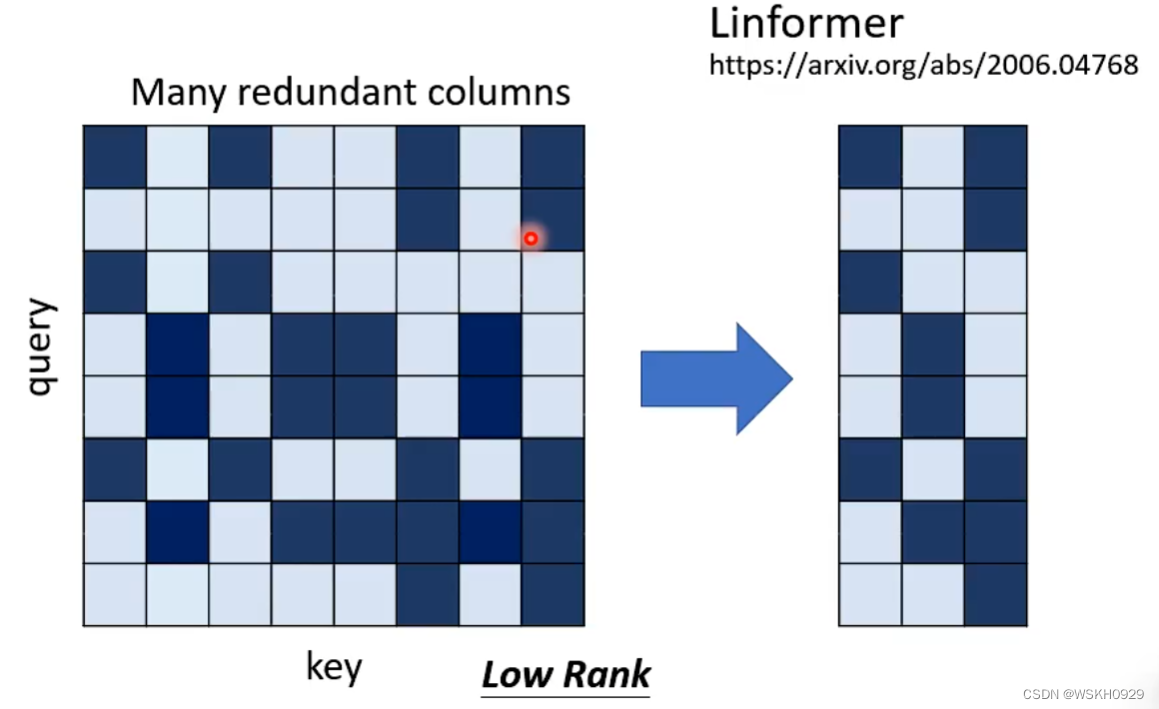
问:实际上应该怎么做呢?
答:从N个Key和Value中选出K个具有代表性的Key和Value进行Attention的计算
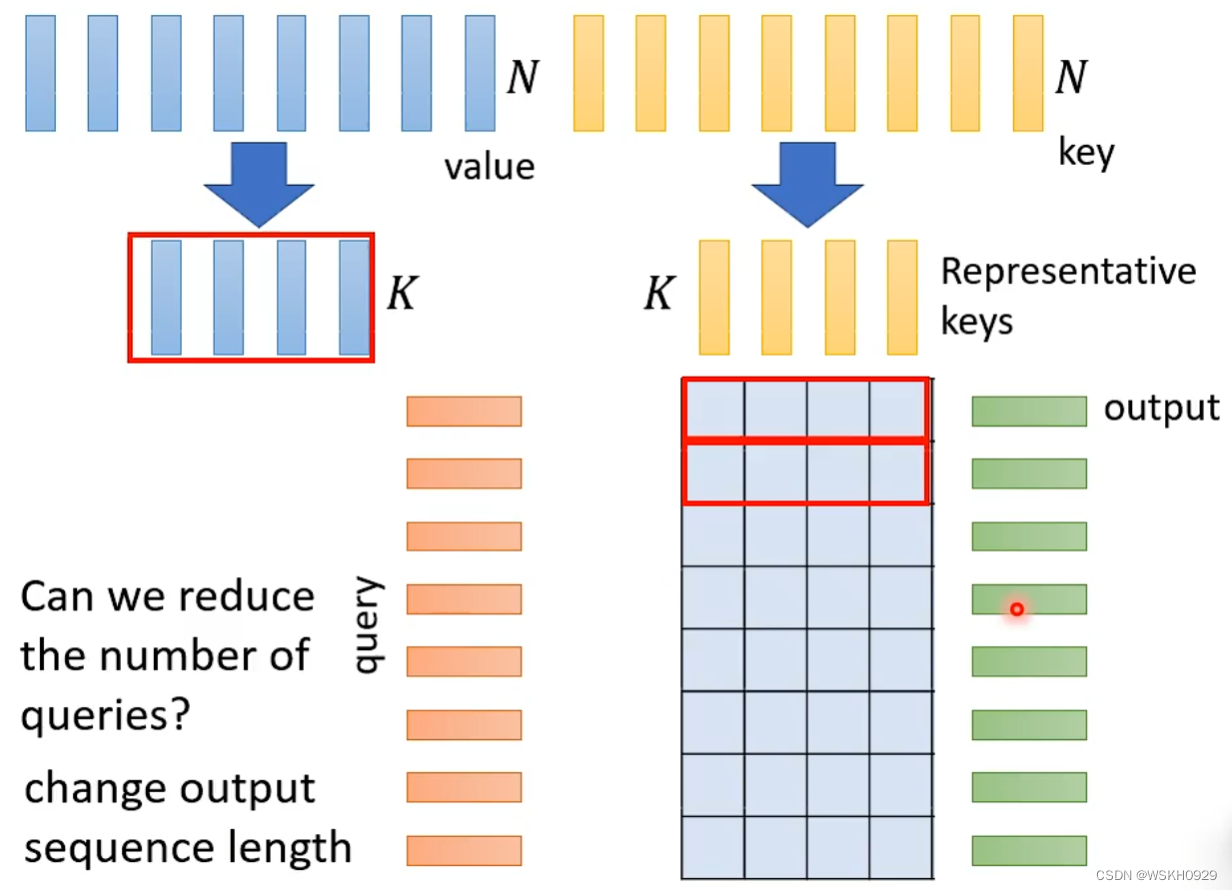
问:那么怎么选取具有代表性的Key呢?
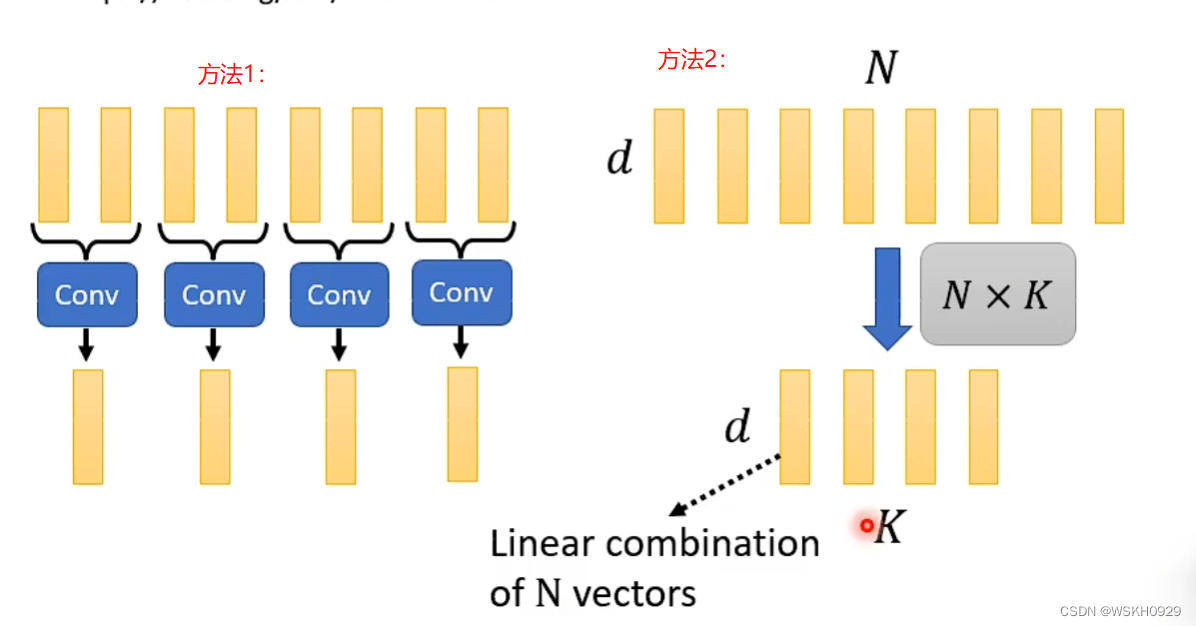
答:有两个方法。
方法1:对N个Key进行卷积操作,从而达到降维的效果
方法2:将原本的d×N的矩阵乘上一个N×K的矩阵,就可以得到d×K的矩阵,从而实现降维
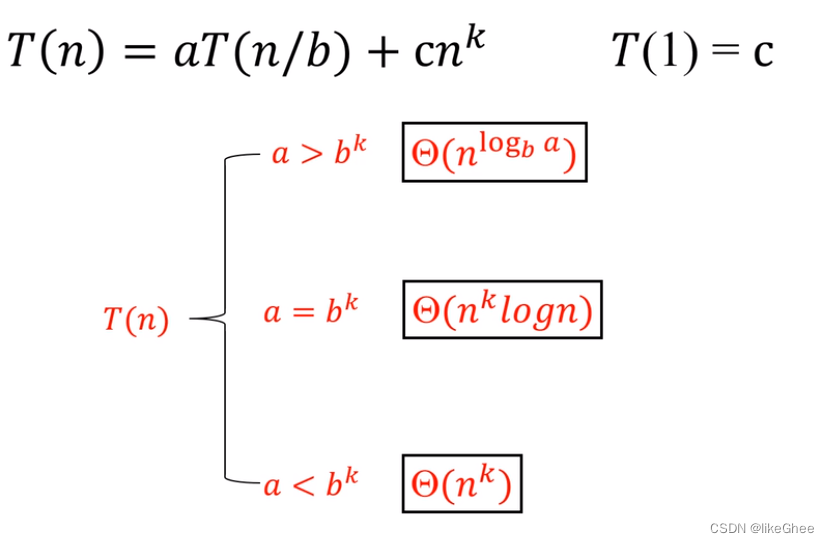
十、Attention Mechanism is three-matrix Multiplication
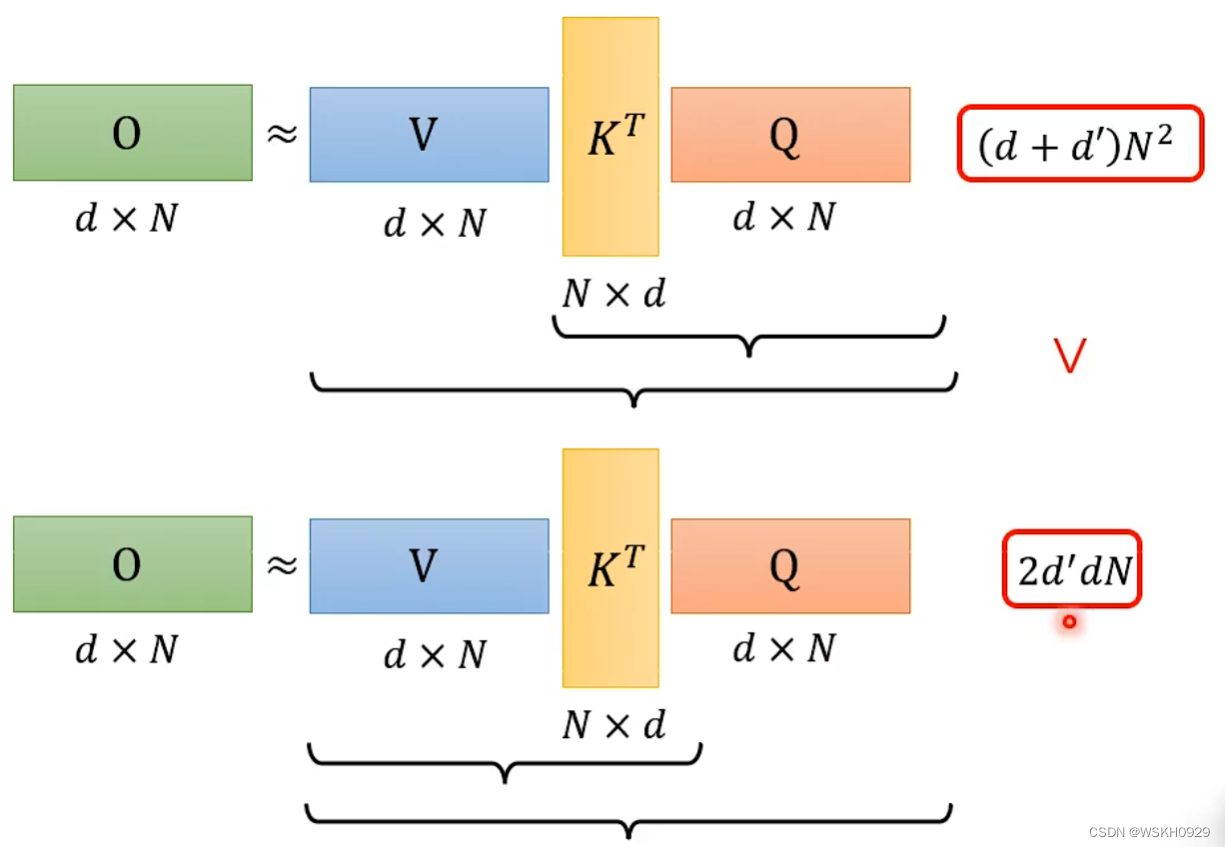
下面回顾一下Attention的计算过程
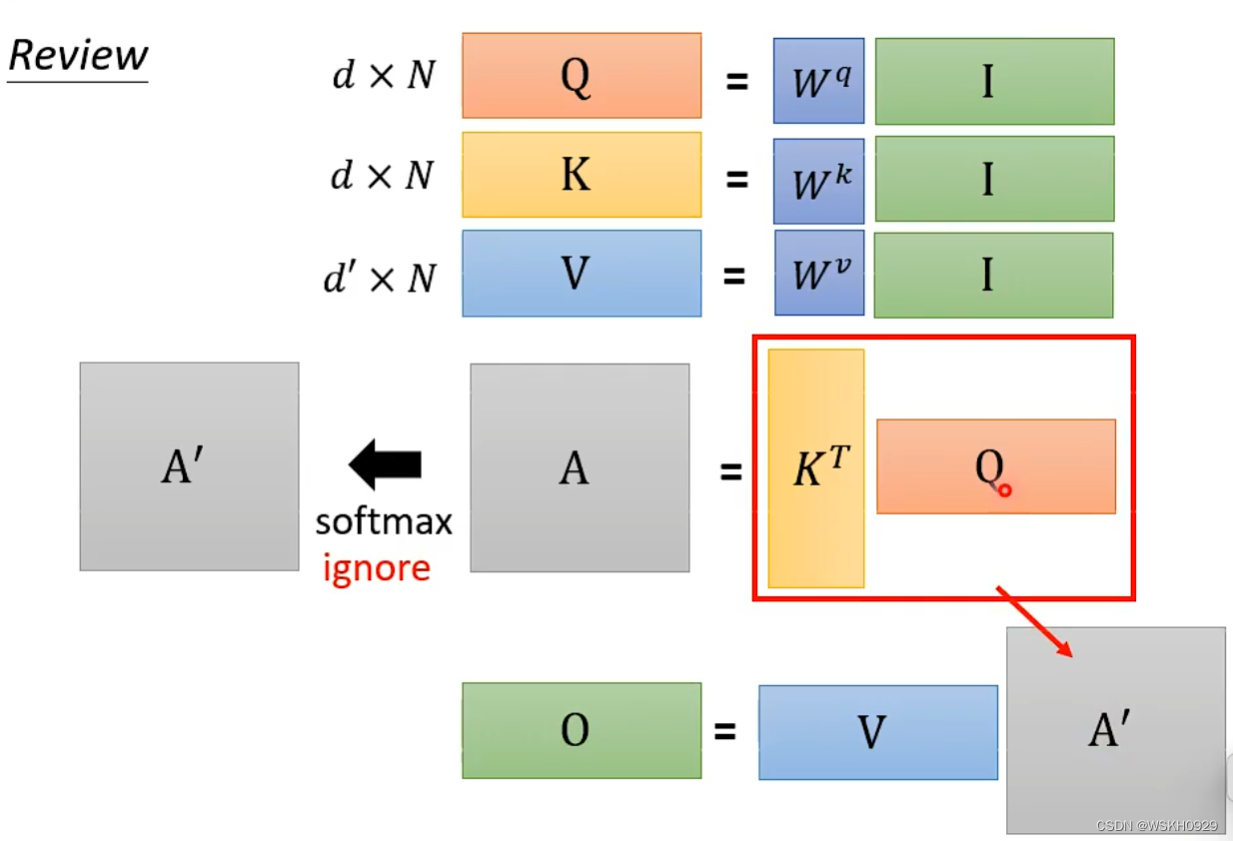
假设不考虑SoftMax过程,计算O矩阵的过程可以近似如下
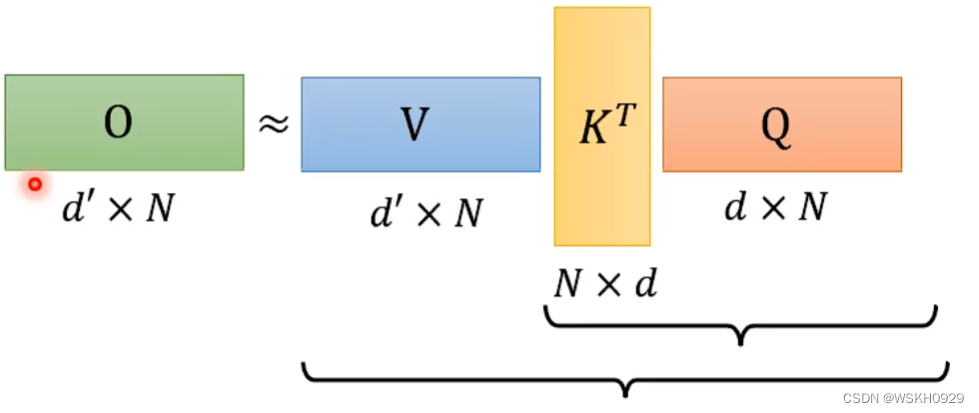
那么我们可以通过改变矩阵的求解顺序来实现加速
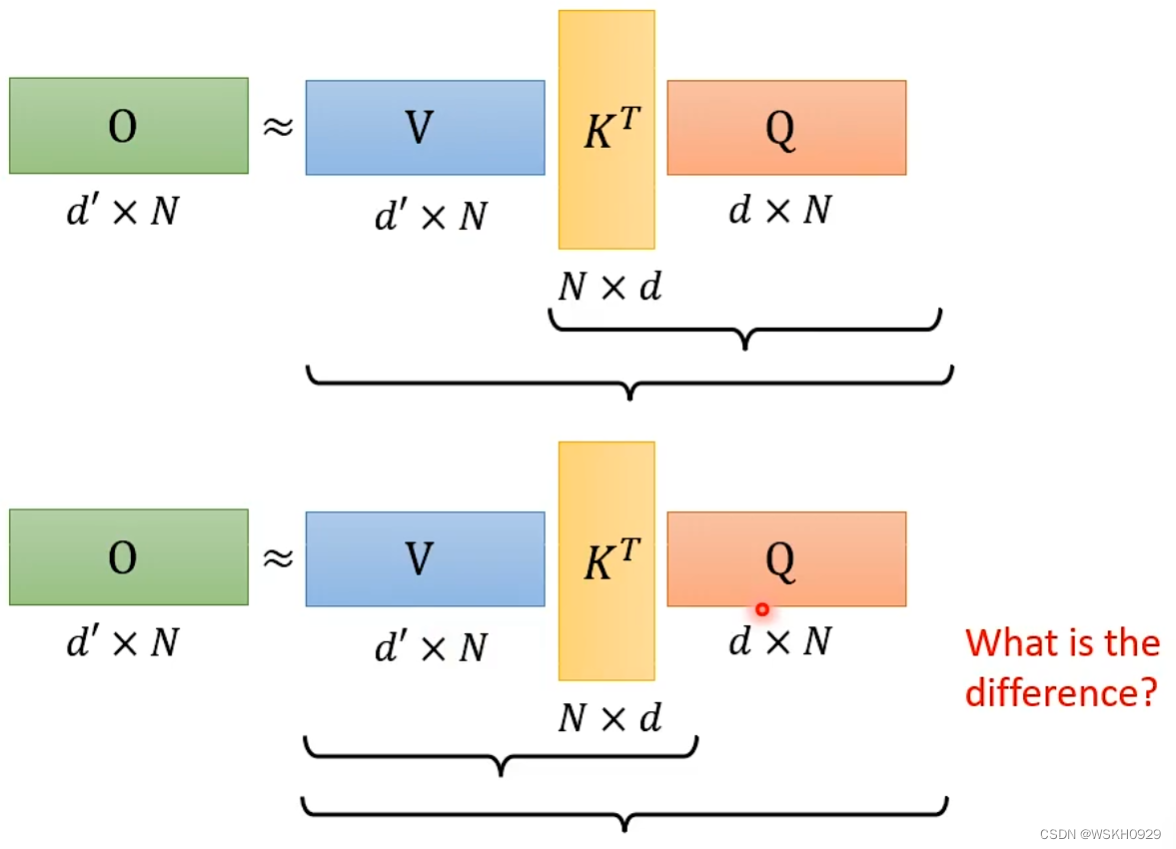
先来看看原本求解顺序所需要的计算量
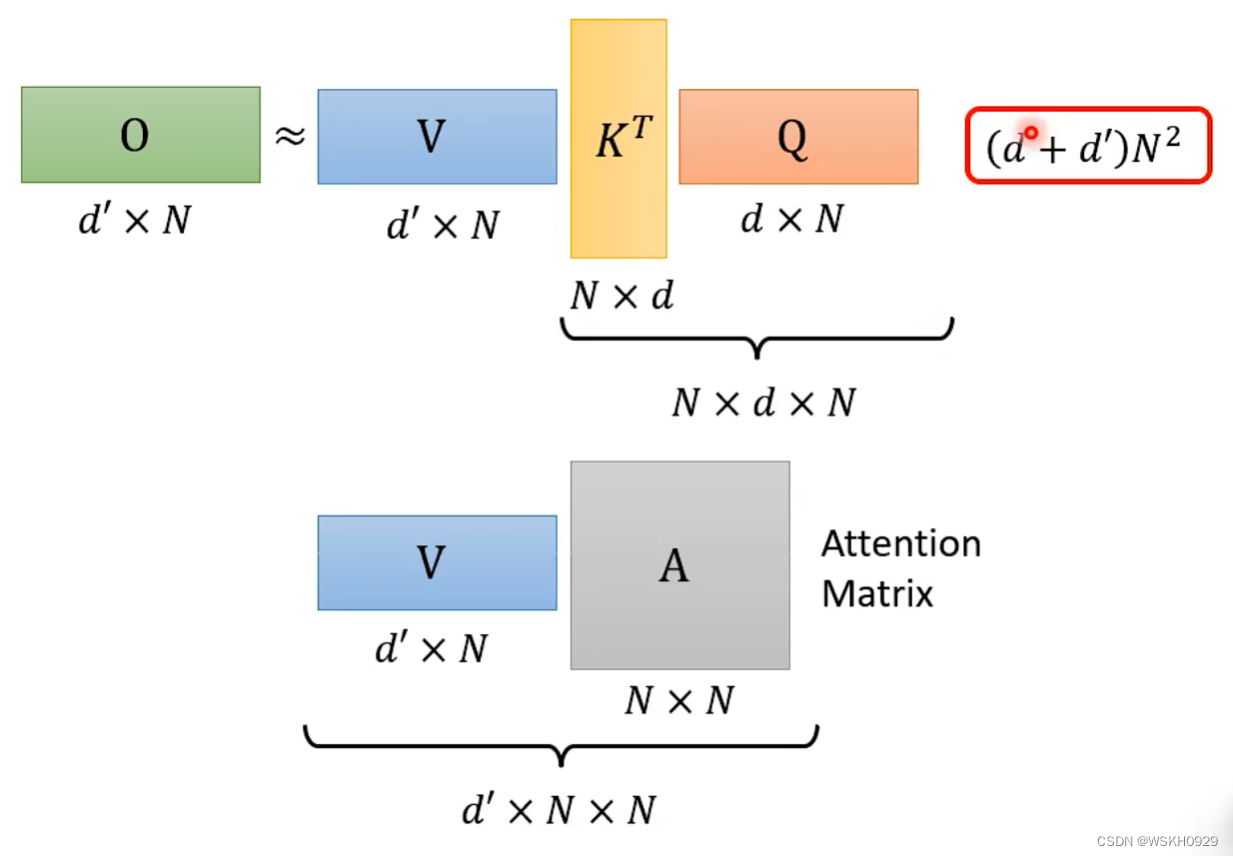
再来看看交换顺序后的求解计算量
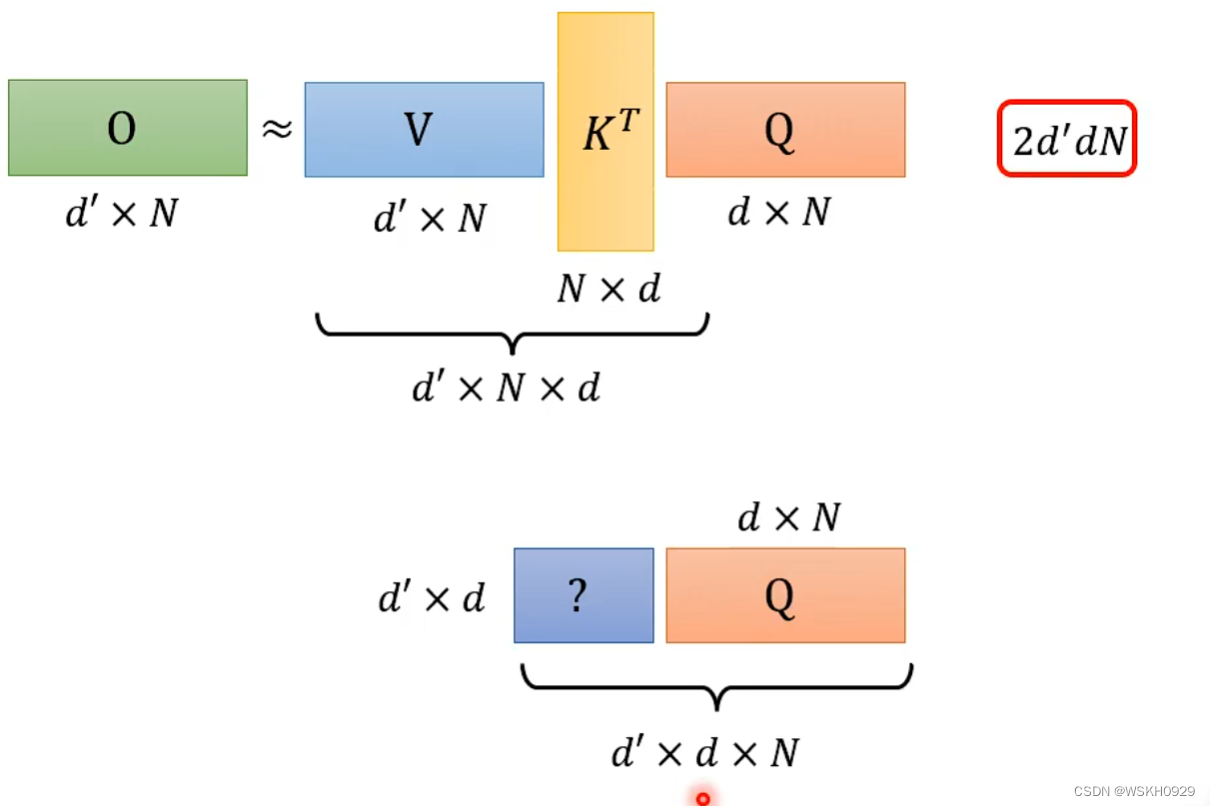
对比一下,由于N是序列的长度,所以往往N会比d大很多,所以通常情况下 ( d + d ′ ) N 2 > 2 d d ′ N (d+d')N^2>2dd'N (d+d′)N2>2dd′N
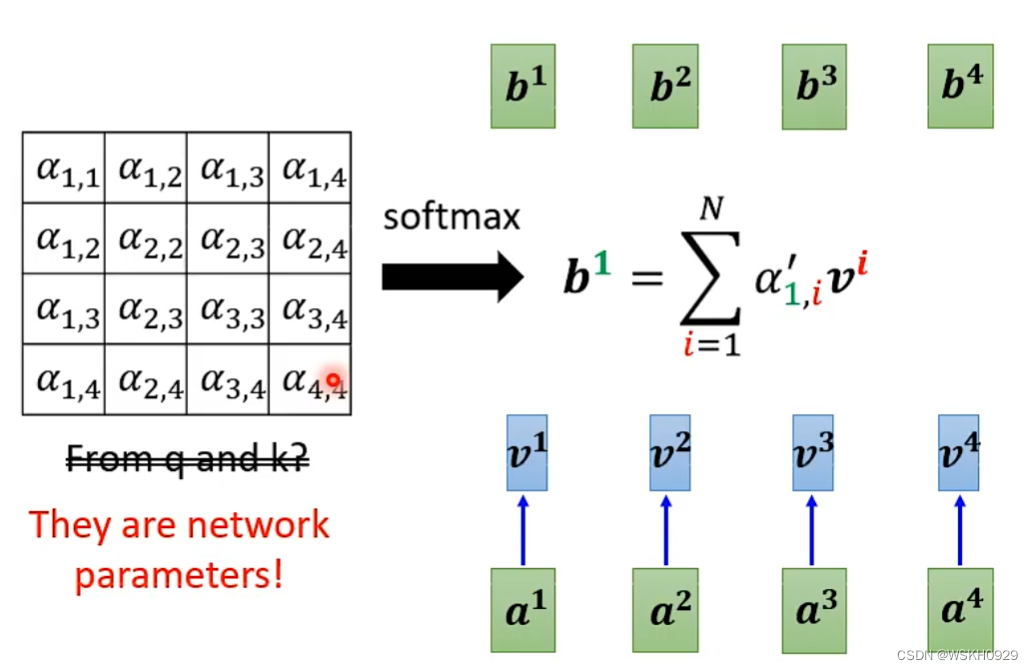
十一、Do we need Q and K to compute attention?Synthesizer!
我们其实可以不用Q和K计算Attention Matrix,而是直接将Attention Matrix替换为可学习的一组参数矩阵!
十二、Attention-free?
Attention是必须的吗?不用Attention能得到很好的效果吗?下面是对这个问题的一些研究
十三、Summary