FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
3. 方法
3.1 LDM
3.2 FreeStyle 的模型结构
3.3 特征调制模块
4. 实验
0. 摘要
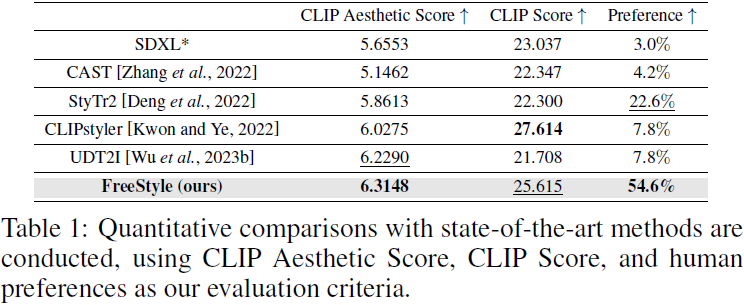
生成扩散模型的快速发展显著推动了风格迁移领域。然而,基于扩散模型的大多数当前风格迁移方法通常涉及缓慢的迭代优化过程,例如模型微调和风格概念的文本反演。在本文中,我们介绍了FreeStyle,这是一种创新的风格迁移方法,建立在一个预训练的大型扩散模型之上,无需进一步优化。此外,我们的方法通过所需风格的文本描述实现风格迁移,消除了风格图像的必要性。具体而言,我们提出了一个双流编码器和单流解码器架构,取代了扩散模型中的传统 U-Net。在双流编码器中,两个独立的分支以内容图像和风格文本提示作为输入,实现内容和风格的解耦。在解码器中,我们进一步调制来自双流的特征,基于给定的内容图像和相应的风格文本提示,实现精确的风格迁移。我们的实验结果展示了我们的方法在各种内容图像和风格文本提示中的高质量合成和忠实度。
项目网站:https://freestylefreelunch.github.io/
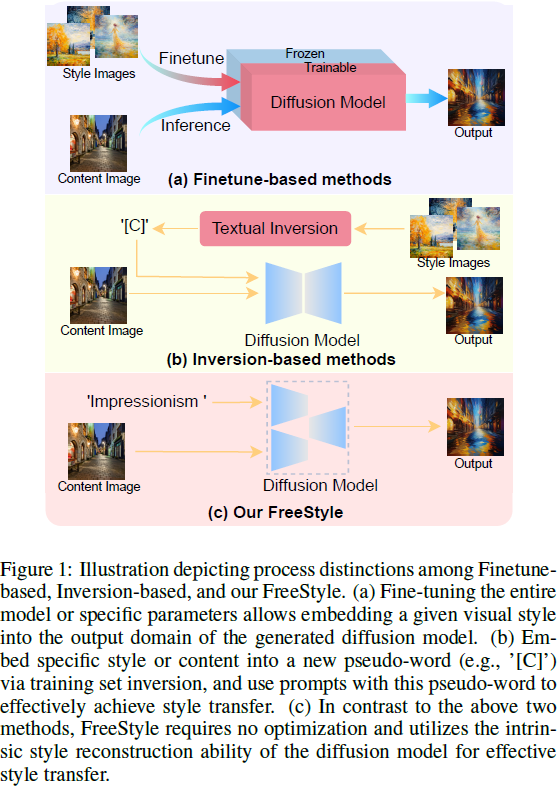

3. 方法
3.1 LDM
3.2 FreeStyle 的模型结构
在扩散模型中,U-Net 结构通常用作噪声预测网络。它包括一个编码器和一个解码器,以及便于信息在编码器和解码器对应层之间交换的跳跃连接。受到 FreeU [Si等人,2023] 的启发,该论文提出了平衡 U-Net 骨干和跳跃层低频和高频特征的方法,我们引入了一种新颖的调制方法,用于融合应用于风格转移的内容信息和风格信息。图 2(a)展示了 FreeStyle 的整体结构,包括双流编码器和单流解码器。FreeStyle 中的双流编码器由两个共享参数的 U-Net 编码器组成,而单流解码器由 U-Net 解码器结构组成。双流下采样过程可以分别描述如下:

其中,c 表示风格文本提示的嵌入,而 x_σ 表示经过 σ 步噪声添加后的内容图像。f_s 和 f_c 分别表示携带风格和内容信息的图像特征。给定有噪输入 x_t,去噪过程将扩散过程反转为预测的干净数据 x_(t−1):
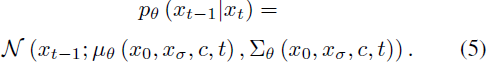
3.3 特征调制模块
FreeU [Si等人,2023] 策略性地重新调整了 U-Net 的跳跃连接和骨干特征图的贡献,有效地利用了 U-Net 架构这两个组成部分的优势,增强了生成图像的质量。我们认为图像由控制图像内容的低频信号和管理图像风格的高频信号组成。因此,我们通过调制风格特征 f_s 和内容特征 f_c 来实现一种有效的无需训练的风格转移。与 FreeU 不同的是,需要调制的两个特征来自两个不同的输入,即风格输入 f_s 和内容输入 f_c。
如图 2(b)所示,内容特征 f_c 是由无噪声的内容图像 x_0 引导生成的,而风格特征 f_s 是由风格文本提示 c 和添加噪声的图像 x_σ 引导生成的。在 U-Net 的上采样过程中,特征 f_c 主要影响生成结果的语义表达,而特征 f_s 对结果的高频详细信息有更大的影响。因此,我们对 f_s 和 f_c 进行特殊的调制,以进一步激活 U-Net 的内在风格重建能力。为了增强特征 f_c 的语义特征,我们增加了它们的方差。具体而言,我们对特征的某些维度应用大于 1 的权重参数 b,以扩大它们的方差。我们可以简洁地表示这个过程如下:
![]()
其中,n 用于截断特征的一部分。另一方面,为了从特征 f_s 中提取风格特征,我们认为有必要抑制低频语义特征,同时保留高频细节和其他风格表达信息。为了实现这一点,我们首先使用傅里叶变换将特征 f_s 转换为频域信息,然后应用一个阈值 r_thresh = 1 来过滤掉特征中的低频语义信息。随后,我们使用一个大于 1 的权重参数 s 来增强风格信息。最后,我们使用逆傅里叶变换将处理过的频域特征转换回空间域特征。我们可以简单地表示这个过程如下:
![]()
FFT 和 IFFT 分别代表傅里叶变换和反傅里叶变换。函数 F 定义为:

其中 r 为半径。应用以上方法,我们调制 f_c 和 f_s,最后将它们连接起来馈送到 U-Net 解码器的块中。
4. 实验