目录
前言
1.常见命令
2.使用场景
3.渐进式遍历
4.数据库管理
前言
有序集合相对于字符串、列表、哈希、集合来说会有一-些陌生。它保留了集合不能有重复成员的
特点,但与集合不同的是,有序集合中的每个元素都有-个唯- -的浮 点类型的分数(score) 与之关
联,着使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个分数。如图2-26所示,该有序集合显示了三国中的武将的武力。
图2-26有序集合

有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能,合理地利用有序集合,可
以帮助我们在实际开发中解决很多问题。
有序集合中的元素是不能重复的,但分数允许重复。类比于一次考试之后,每个人一定有一
个唯一的分数,但分数允许相同。
表2-7列表、集合、有序集合三者的异同点。

1.常见命令
ZADD
添加或者更新指定的元素以及关联的分数到zset中,分数应该符合double类型,+inf/-inf 作为正负
极限也是合法的。
ZADD的相关选项:
●XX:仅仅用于更新已经存在的元素,不会添加新元素。
●NX: 仅用于添加新元素,不会更新已经存在的元素。
●CH: 默认情况下,ZADD返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。
●INCR: 此时命令类似ZINCRBY的效果,将元素的分数加上指定的分数。此时只能指定一个元素和
分数。
语法:
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member
...]命令有效版本: 1.2.0之后
时间复杂度: O(log(N))
返回值:本次添加成功的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 1 "uno"
(integer) 1
redis> ZADD myzset 2 "two" 3 "three"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
redis> ZADD myzset 10 one 20 two 30 three
(integer) 0
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "uno"
2) "1"
3) "one"
4) "10"
5) "two"
6) "20"
7) "three"
8) "30"
redis> ZADD myzset CH 100 one 200 two 300 three
(integer) 3
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "uno"
2) "1"
3) "one"
4) "100"
5) "two"
6) "200"
7) "three"
8) "300"
redis> ZADD myzset XX 1 one 2 two 3 three 4 four 5 five
(integer) 0
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
redis> ZADD myzset NX 100 one 200 two 300 three 400 four 500 five
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
9) "four"
10) "400"
11) "five"
12) "500"
redis> ZADD myzset INCR 10 one
"11"
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "uno"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
7) "one"
8) "11"
9) "four"
10) "400"
11) "five"
12) "500"
redis> ZADD myzset -inf "negative infinity" +inf "positive infinity"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "negative infinity"
2) "-inf"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
9) "one"
10) "11"
11) "four"
12) "400"
13) "five"
14) "500"
15) "positive infinity"
16) "inf"ZCARD
获取一个zset的基数(cardinality) ,即zset中的元素个数。
语法:
ZCARD key 命令有效版本: 1.2.0之后
时间复杂度: 0(1)
返回值: zset 内的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 2ZCOUNT
返回分数在min和max之间的元素个数,默认情况下,min 和max都是包含的,可以通过(排除。
语法:
ZCOUNT key min max 命令有效版本: 2.0.0之后
时间复杂度: O(log(N))
返回值:满足条件的元素列表个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZCOUNT myzset -inf +inf
(integer) 3
redis> ZCOUNT myzset 1 3
(integer) 3
redis> ZCOUNT myzset (1 3
(integer) 2
redis> ZCOUNT myzset (1 (3
(integer) 1ZRANGE .
返回指定区间里的元素,分数按照升序。带上WITHSCORES可以把分数也返回。
语法:
ZRANGE key start stop [WITHSCORES] 此处的[start, stop]为下标构成的区间从0开始,支持负数.
命令有效版本: 1.2.0之后
时间复杂度: O(log(N)+M)
返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis> ZRANGE myzset 0 -1
1) "one"
2) "two"
3) "three"
redis> ZRANGE myzset 2 3
1) "three"
redis> ZRANGE myzset -2 -1
1) "two"
2) "three"ZREVRANGE
返回指定区间里的元素,分数按照降序。带_ 上WITHSCORES可以把分数也返回。
备注:这个命令可能在6.2.0之后废弃,并且功能合并到ZRANGE中。
语法:
ZREVRANGE key start stop [WITHSCORES] 命令有效版本: 1.2.0 之后
时间复杂度: O(log(N)+M)
返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"
3) "two"
4) "2"
5) "one"
6) "1"
redis> ZREVRANGE myzset 0 -1
1) "three"
2) "two"
3) "one"
redis> ZREVRANGE myzset 2 3
1) "one"
redis> ZREVRANGE myzset -2 -1
1) "two"
2) "one"ZRANGEBYSCORE
返回分数在min和max之间的元素,默认情况下,min 和max都是包含的,可以通过(排除。
备注:这个命令可能在6.2.0之后废弃,并且功能合并到ZRANGE中。
语法:
ZRANGEBYSCORE key min max [WITHSCORES] 命令有效版本: 1.0.5之后
时间复杂度: O(log(N)+M)
返回值:区间内的元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGEBYSCORE myzset -inf +inf
1) "one"
2) "two"
3) "three"
redis> ZRANGEBYSCORE myzset 1 2
1) "one"
2) "two"
redis> ZRANGEBYSCORE myzset (1 2
1) "two"
redis> ZRANGEBYSCORE myzset (1 (2
(empty array)ZPOPMAX
删除并返回分数最高的count个元素。
语法:
ZPOPMAX key [count] 命令有效版本:5.0.0 之后
时间复杂度: 0(log(N)* M)
返回值:分数和元素列表。示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMAX myzset
1) "three"
2) "3" BZPOPMAX
ZPOPMAX的阻塞版本。
语法:
BZPOPMAX key [key ...] timeout 命令有效版本: 5.0.0之后
时间复杂度: O(log(N))
返回值:元素列表。
示例:
redis> DEL zset1 zset2
(integer) 0
redis> ZADD zset1 0 a 1 b 2 c
(integer) 3
redis> BZPOPMAX zset1 zset2 0
1) "zset1"
2) "c"
3) "2"ZPOPMIN
删除并返回分数最低的count个元素。
语法:
ZPOPMIN key [count] 命令有效版本: 5.0.0之后
时间复杂度: O(log(N) * M)
返回值:分数和元素列表。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMIN myzset
1) "one"
2) "1"BZPOPMIN
ZPOPMIN的阻塞版本。
语法:
BZPOPMIN key [key ...] timeout 命令有效版本: 5.0.0之后
时间复杂度: O(log(N))
返回值:元素列表。
示例:
redis> DEL zset1 zset2
(integer) 0
redis> ZADD zset1 0 a 1 b 2 c
(integer) 3
redis> BZPOPMIN zset1 zset2 0
1) "zset1"
2) "a"
3) "0"ZRANK
返回指定元素的排名,升序。
语法:
ZRANK key member 命令有效版本: 2.0.0 之后
时间复杂度: 0(log(N))
返回值:排名。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANK myzset "three"
(integer) 2
redis> ZRANK myzset "four"
(nil)ZREVRANK
返回指定元素的排名,降序。
语法:
ZREVRANK key member命令有效版本: 2.0.0之后
时间复杂度: 0(log(N))
返回值:排名。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANK myzset "one"
(integer) 2
redis> ZREVRANK myzset "four"
(nil)ZSCORE
返回指定元素的分数。
语法:
ZSCORE key member 命令有效版本: 1.2.0之后
时间复杂度: 0(1)
返回值:分数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"ZREM
删除指定的元素。
语法:
ZREM key member [member ...]命令有效版本: 1.2.0之后
时间复杂度: 0(M*log(N))
返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"ZREMRANGEBYRANK
按照排序,升序删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYRANK key start stop 命令有效版本: 2.0.0之后
时间复杂度: O(log(N)+M)
返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYRANK myzset 0 1
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"ZREMRANGEBYSCORE
按照分数删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYSCORE key min max 命令有效版本: 1.2.0之后.
时间复杂度: O(log(N)+M) .
返回值:本次操作删除的元素个数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYSCORE myzset -inf (2
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "three"
4) "3"ZINCRBY
为指定的元素的关联分数添加指定的分数值。
语法:
ZINCRBY key increment member 命令有效版本: 1.2.0之后
时间复杂度: O(log(N))
返回值:增加后元素的分数。
示例:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZINCRBY myzset 2 "one"
"3"
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "one"
4) "3"集合间操作
图2-27有序集合的交集操作
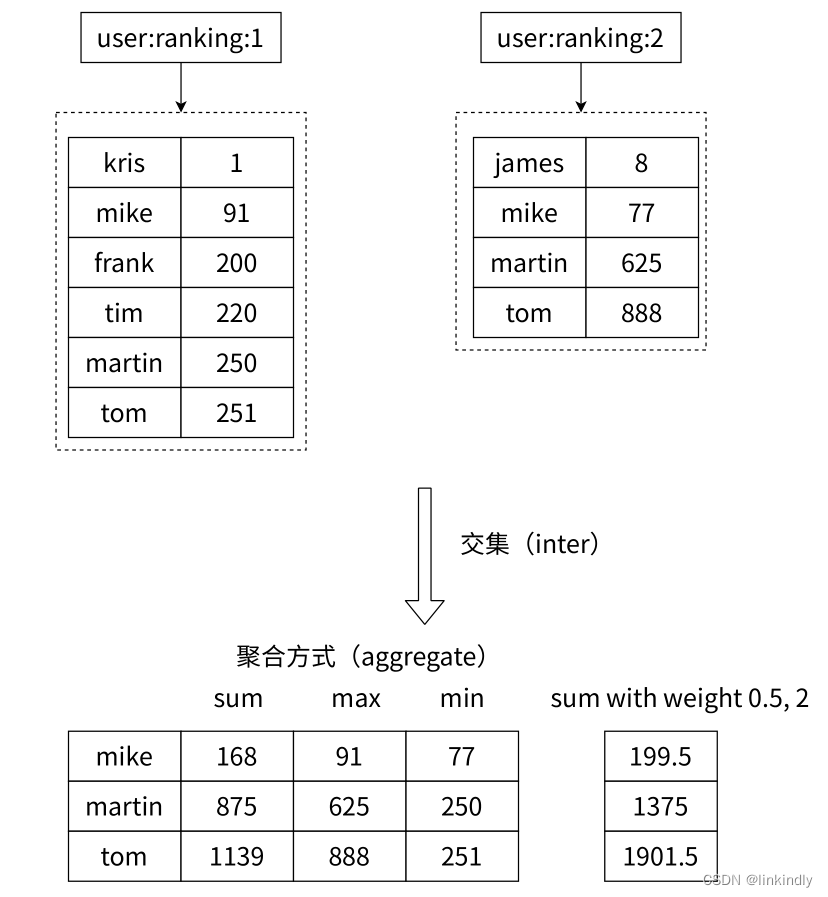
求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight
[weight ...]] [AGGREGATE <SUM | MIN | MAX>]命令有效版本: 2.0.0之后
时间复杂度: O(N*K)+O(M*log(M)) N 是输入的有序集合中,最小的有序集合的元素个数; K是输入了几个有序集合; M是最终结果的有序集合的元素个数.
返回值:目标集合中的元素个数
示例:
redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZINTERSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 2
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "two"
4) "10"图2-28有序集合的并集操作

ZUNIONSTORE
求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数。
语法:
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight
[weight ...]] [AGGREGATE <SUM | MIN | MAX>]命令有效版本: 2.0.0之后
时间复杂度: 0(N)+O(M*log(M)) N是输入的有序集合总的元素个数; M是最终结果的有序集合的元素
个数.返回值:目标集合中的元素个数
示例:
redis> ZADD zset1 1 "one"
(integer) 1
redis> ZADD zset1 2 "two"
(integer) 1
redis> ZADD zset2 1 "one"
(integer) 1
redis> ZADD zset2 2 "two"
(integer) 1
redis> ZADD zset2 3 "three"
(integer) 1
redis> ZUNIONSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 3
redis> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "three"
4) "9"
5) "two"
6) "10"命令小结
表2-8有序集合命令
 内部编码
内部编码
有序集合类型的内部编码有两种:
●ziplist (压缩列表) :当有序集合的元素个数小于zset- max -ziplist-entries配置(默认128个)
同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis 会用ziplist来作
为有序集合的内部实现,ziplist 可以有效减少内存的使用。
●skiplist (跳表) :当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时
ziplist的操作效率会下降。
1)当元素个数较少且每个元素较小时,内部编码为ziplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3
(integer) 3
127.0.0.1:6379> object encoding zsetkey
"ziplist"2)当元素个数超过128个,内部编码skiplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3 ... 省略 ... 82 e129
(integer) 129
127.0.0.1:6379> object encoding zsetkey
"skiplist"3)当某个元素大于64字节时,内部编码skiplist:
127.0.0.1:6379> zadd zsetkey 50 "one string bigger than 64 bytes ... 省略 ..."
(integer) 1
127.0.0.1:6379> object encoding zsetkey
"skiplist"2.使用场景
有序集合比较典型的使用场景就是排行榜系统。例如常见的网站上的热榜信息,榜单的维度可能
是多方面的:按照时间、按照阅读量、按照点赞量。本例中我们使用点赞数这个维度,维护每天的热
榜:
1)添加用户赞数
例如用户james发布了一篇文章,并获得3个赞,可以使用有序集合的zadd和zincrby功能:
zadd user:ranking:2022-03-15 3 james 之后如果再获得赞,可以使用zincrby:
zincrby user:ranking:2022-03-15 1 james 2)取消用户赞数
由于各种原因(例如用户注销、用户作弊等)需要将用户删除,此时需要将用户从榜单中删除掉,可
以使用zrem。例如删除成员tom:
zrem user:ranking:2022-03-15 tom 3)展示获取赞数最多的10个用户
此功能使用zrevrange命令实现:
zrevrangebyrank user:ranking:2022-03-15 0 9 4)展示用户信息以及用户分数
此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户的分数和排名可以使用zscore和zrank来实现。
hgetall user:info:tom
zscore user:ranking:2022-03-15 mike
zrank user:ranking:2022-03-15 mike3.渐进式遍历
Redis使用scan命令进行渐进式遍历键,进而解决直接使用keys获取键时可能出现的阻塞问题。每次scan命令的时间复杂度是0(1),但是要完整地完成所有键的遍历,需要执行多次scan。整个过程如图2-29所示。
图2-29 scan命令渐进式遍历

首次scan从0开始.
当scan返回的下次位置为0时,遍历结束.
SCAN
以渐进式的方式进行键的遍历。
语法:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type] 命令有效版本: 2.8.0之后
时间复杂度: 0(1)
返回值:下一次scan的游标(cursor) 以及本次得到的键。
示例:
127.0.0.1:6379> scan 0
1) "10"
2) 1) "counter"
2) "myzset"
3) "setkey"
4) "lastname"
5) "myset1"
6) "keys"
7) "key2"
8) "mylist"
9) "zset2"
10) "age"
127.0.0.1:6379> scan 17
1) "0"
2) 1) "firstname"
2) "hello"
3) "myset"
4) "key3"
5) "mhash2"
6) "mykey"
7) "out"
8) "mhash1"
9) "myhash"
除了scan以外,Redis 面向哈希类型、集合类型、有序集合类型分别提供了hscan、sscan、 zscan 命令,它们的用法和scan基本类似,感兴趣的读者可以自行做扩展学习。
渐进性遍历scan虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删除),可能导致遍历时键的重复遍历或者遗漏,这点务必在实际开发中考虑。
4.数据库管理
Redis提供了几个面向Redis数据库的操作,分别是dbsize、select、 flushdb、 flushall 命令,
本机将通过具体的使用常见介绍这些命令。
切换数据库
select dbIndex 许多关系型数据库,例如MySQL支持在一个实例下有多个数据库存在的,但是与关系型数据库用
字符来区分不同数据库名不同,Redis 只是用数字作为多个数据库的实现。Redis 默认配置中是有16 个数据库。select 0操作会切换到第一个数据库,select 15会切换到最后一个数据库。0号数据库和15号数据库保存的数据是完全不冲突的(如图2-30所示), 即各种有各自的键值对。默认情况下,我们处于数据库0。
redis管理的数据库
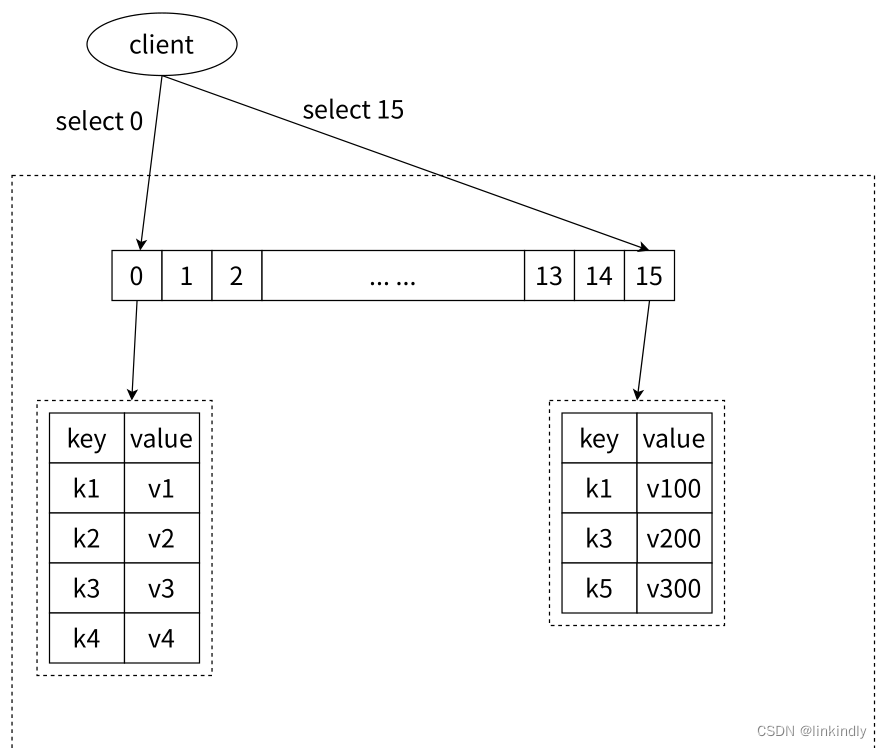
Redis中虽然支持多数据库,但随着版本的升级,其实不是特别建议使用多数据库特性。如
果真的需要完全隔离的两套键值对,更好的做法是维护多个Redis实例,而不是在一个
Redis实例中维护多数据库。这是因为本身Redis并没有为多数据库提供太多的特性,其次
无论是否有多个数据库,Redis 都是使用单线程模型,所以彼此之间还是需要排队等待命令
的执行。同时多数据库还会让开发、调试和运维工作变得复杂。所以实践中,始终使用数据
库0其实是一个很好的选择。
清除数据库
flushdb / flushall命令用于清除数据库,区别在于flushdb只清除当前数据库,flushall 会清楚所有数
据库。