文章目录
- 一、Doris简介
- 1、Doris介绍
- 2、Doris架构
- 二、Doris单机部署(Centos7.9)
- 1、下载Doris
- 2、准备环境
- 3、安装部署
- 3.1 创建存储目录
- 3.2 配置 FE
- 3.3 启动 FE
- 3.4 查看 FE 运行状态
- 3.5 配置 BE
- 3.6 启动 BE
- 3.7 添加 BE 节点到集群
- 3.8 查看 BE 运行状态
- 3.9 简单用法
- 三、完结
一、Doris简介
1、Doris介绍
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。目前 Apache Doris 社区已经聚集了来自不同行业近百家企业的 300 余位贡献者,并且每月活跃贡献者人数也接近 100 位。 2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)
Apache Doris 如今在中国乃至全球范围内都拥有着广泛的用户群体,截止目前, Apache Doris 已经在全球超过 500 家企业的生产环境中得到应用,在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、网易、快手、微博、贝壳等。同时在一些传统行业如金融、能源、制造、电信等领域也有着丰富的应用。
2、Doris架构
Doris 架构非常简单,只有两类进程:
- Frontend(FE),主要负责
用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作; - Backend(BE),主要负责
数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
在使用接口方面,Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。
在存储引擎方面,Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
Doris 支持比较丰富的索引结构,来减少数据的扫描:
- Sorted Compound Key Index,可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景;
- Z-order Index`:使用 Z-order 索引,可以高效对数据模型中的任意字段组合进行范围查询;
- Min/Max :有效过滤数值类型的等值和范围查询;
- Bloom Filter :对高基数列的等值过滤裁剪非常有效;
- Invert Index :能够对任意字段实现快速检索。
Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
- Aggregate Key 模型:相同 Key 的 Value 列合并,通过提前聚合大幅提升性能;
- Unique Key 模型:Key 唯一,相同 Key 的数据覆盖,实现行级别数据更新;
- Duplicate Key 模型:明细数据模型,满足事实表的明细存储。
Doris 也支持强一致的物化视图,物化视图的更新和选择都在系统内自动进行,不需要用户手动选择,从而大幅减少了物化视图维护的代价。
在查询引擎方面,Doris 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。
-
Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD 指令的效果。在宽表聚合场景下性能是非向量化引擎的 5-10 倍。
-
Doris 采用了 Adaptive Query Execution 技术, 可以根据 Runtime Statistics 来动态调整执行计划,比如通过 Runtime Filter 技术能够在运行时生成生成 Filter 推到 Probe 侧,并且能够将 Filter 自动穿透到 Probe 侧最底层的 Scan 节点,从而大幅减少 Probe 的数据量,加速 Join 性能。Doris 的 Runtime Filter 支持 In/Min/Max/Bloom Filter。
-
在优化器方面 Doris 使用 CBO 和 RBO 结合的优化策略,RBO 支持常量折叠、子查询改写、谓词下推等,CBO 支持 Join Reorder。目前 CBO 还在持续优化中,主要集中在更加精准的统计信息收集和推导,更加精准的代价模型预估等方面。
二、Doris单机部署(Centos7.9)
1、下载Doris
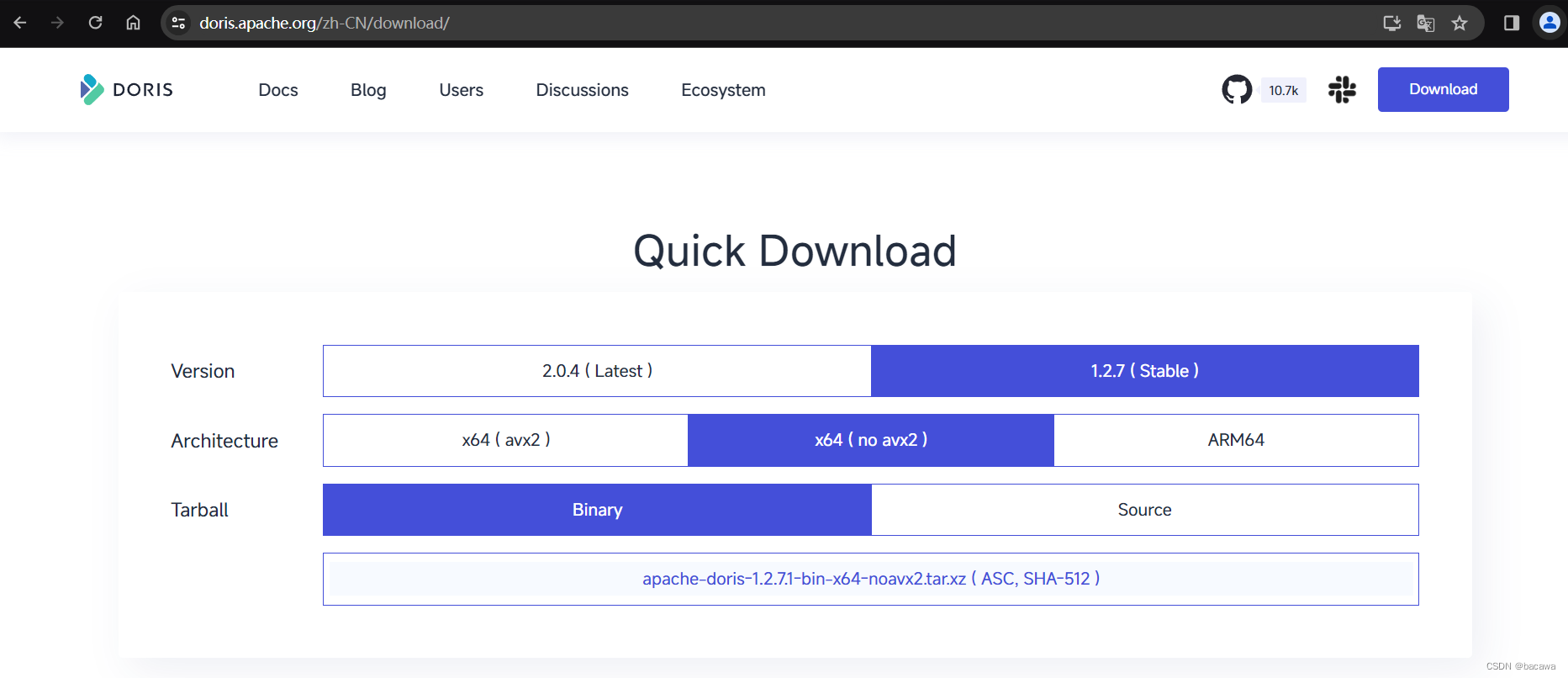
挂网下载地址,选择稳定版本进行下载。
2、准备环境
脚本内容如下
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#永久关闭selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
cat >> /etc/security/limits.conf <<EOF
* soft nofile 65536
* hard nofile 65536
EOF
#安装jdk及依赖包
yum install -y build-essential gcc-10 g++-10 java-1.8.0-openjdk.x86_64 maven cmake byacc flex automake libtool-bin bison binutils-dev libiberty-dev zip unzip libncurses5-dev curl git ninja-build python
#配置java环境变量
cat >>/etc/profile <<EOF
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
EOF
source /etc/profile
新建 install_enviromment.sh脚本文件,使用vi编辑器复制以上内容。
##增加执行权限
chmod 755 install_enviromment.sh
## 执行脚本
./install_enviromment.sh
3、安装部署
3.1 创建存储目录
mkdir -p /doris/data/{storage,doris-meta}
3.2 配置 FE
我们进入到 /doris/apache-doris-1.2.7.1-bin-x64-noavx2/fe 目录
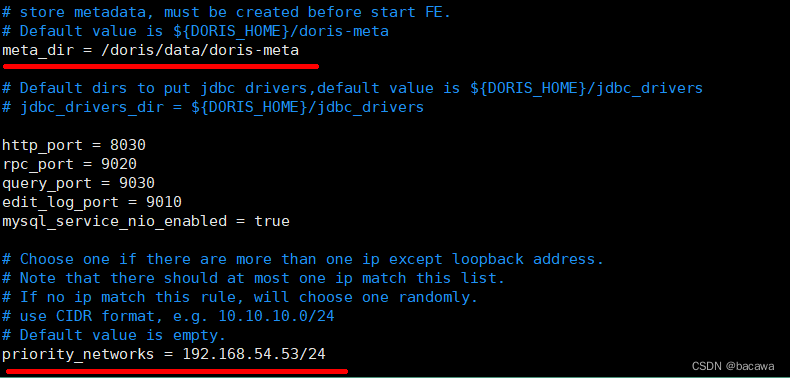
修改 FE 配置文件 conf/fe.conf ,这里我们主要修改两个参数:priority_networks 及 meta_dir ,如果你需要更多优化配置,请参考 FE 参数配置说明,进行调整。
注意事项:
- priority_networks这个参数我们在安装的时候是必须要配置的,特别是当一台机器拥有多个IP地址的时候,我们要为 FE 指定唯一的IP地址。这里假设你的节点 IP 是 172.23.16.32,那么我们可以通过掩码的方式配置为 172.23.16.0/24。
- meta_dir 这个参数指定元数据目录地址,默认是在你的Doris FE 安装目录下的 doris-meta,如果单独配置元数据目录,需要你提前创建好你指定的目录;
- http的端口如果没有冲突,可以不修改。
3.3 启动 FE
./bin/start_fe.sh --daemon
3.4 查看 FE 运行状态
你可以通过下面的命令来检查 Doris 是否启动成功
#通过jps查看
jps
## 看到这样的打印,及表示启动成功
10441 PaloFe
你也可以通过 Doris FE 提供的Web UI 来检查,在浏览器里输入地址
http://IP:8030
可以看到下面的界面,说明 FE 启动成功

注意:
这里我们使用 Doris 内置的默认用户 root 进行登录,密码是空
这是一个 Doris的管理界面,只能拥有管理权限的用户才能登录,普通用户不能登录。
3.5 配置 BE
我们进入到 /doris/apache-doris-1.2.7.1-bin-x64-noavx2/be 目录
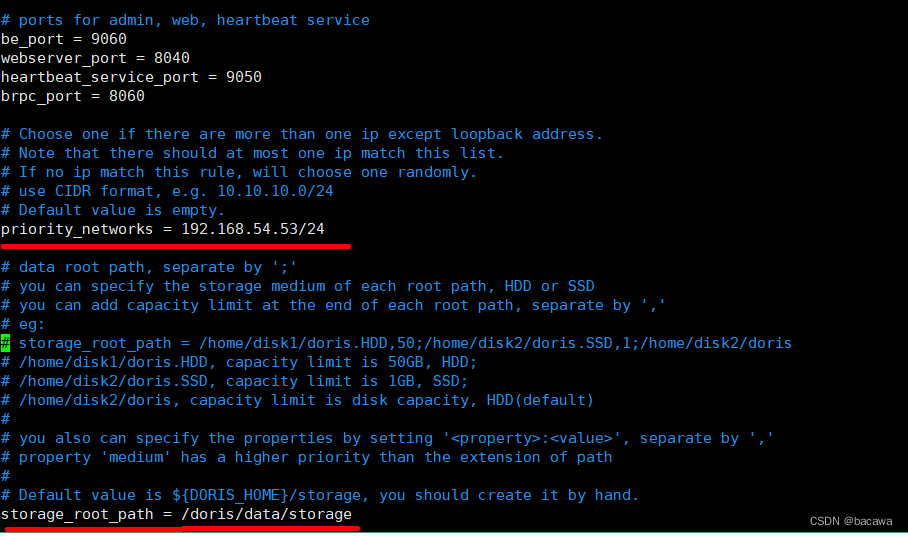
修改 BE 配置文件 conf/be.conf ,这里我们主要修改两个参数:priority_networks 及 meta_dir ,如果你需要更多优化配置,请参考 BE 参数配置说明
注意事项:
- priority_networks这个参数我们在安装的时候是必须要配置的,特别是当一台机器拥有多个IP地址的时候,我们要为 BE 指定唯一的IP地址。这里假设你的节点 IP 是 172.23.16.32,那么我们可以通过掩码的方式配置为 172.23.16.0/24。
- storage_root_path 这个参数指定数据目录地址,默认目录在 BE安装目录的 storage 目录下。,如果单独配置数据目录,需要你提前创建好你指定的目录;
- **webserver_port,brpc_port **的端口如果没有冲突,可以不修改。
3.6 启动 BE
在 BE 安装目录下执行下面的命令,来完成 BE 的启动。
./bin/start_be.sh --daemon
注意:
BE结点和FE结点启动先后次序无要求
3.7 添加 BE 节点到集群
推荐使用 dbeaver 进行连接,默认是没有密码的,我是之前执行过,给配置了密码,密码的配置下文中会有介绍。
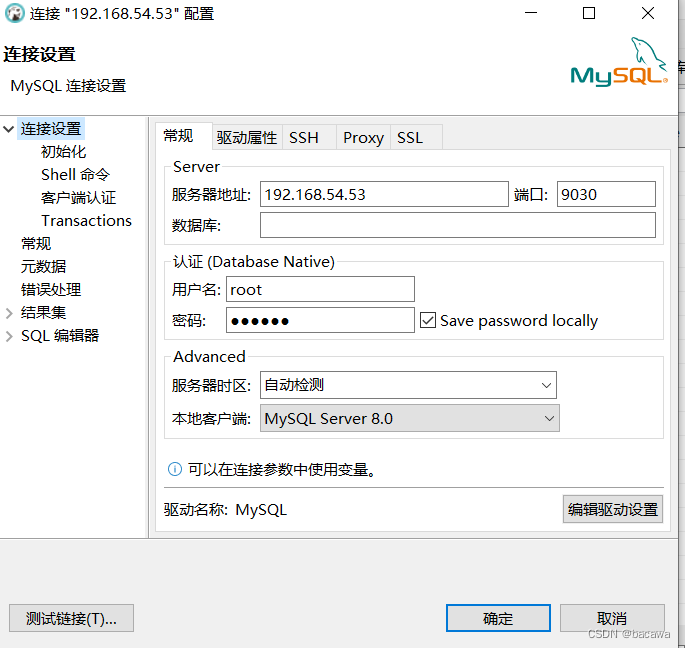
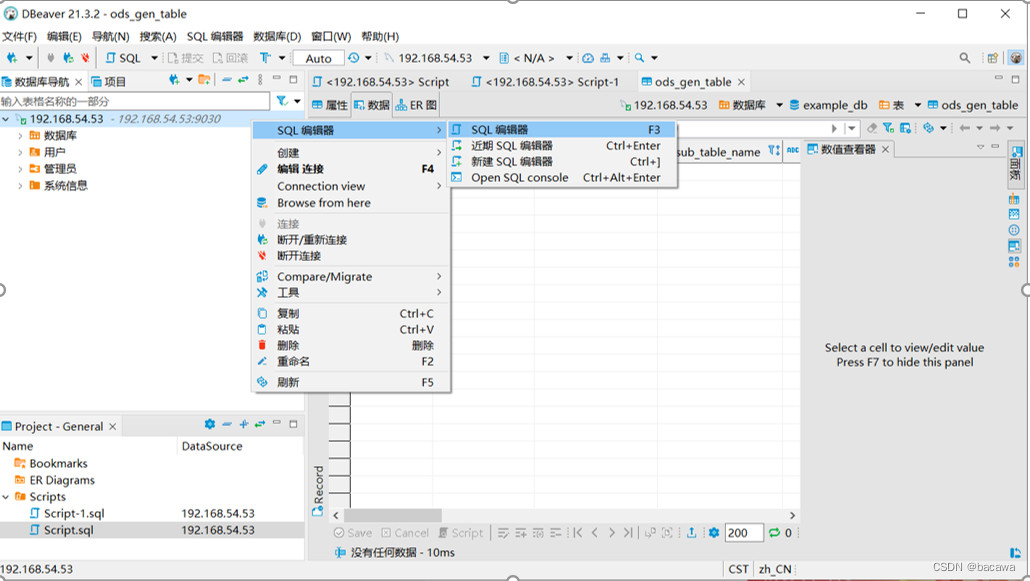
#设置密码
set password = password('123456');
#添加be
alter system add backend "10.10.104.80:9050";
配置语法:ALTER SYSTEM ADD BACKEND “be_host_ip:heartbeat_service_port”;
- be_host_ip:这里是你 BE 的 IP 地址,和你在 be.conf 里的 priority_networks 匹配,需要具体ip
- heartbeat_service_port:这里是你 BE 的心跳上报端口,和你在 be.conf 里的 heartbeat_service_port 匹配,默认是 9050。
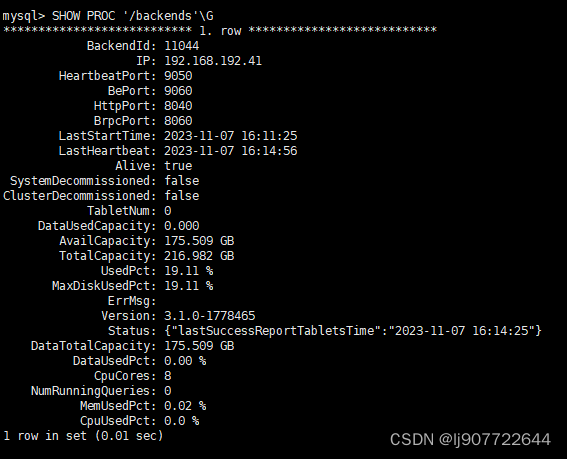
3.8 查看 BE 运行状态
你可以在 MySQL 命令行下执行下面的命令查看 BE 的运行状态。
SHOW BACKENDS
3.9 简单用法
(1)创建一个数据库
create database demo;
(2)创建数据表
use demo;
CREATE TABLE IF NOT EXISTS demo.user_lab(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
(3)查询数据
select * from demo.user_lab;
(4)WebUI查询数据
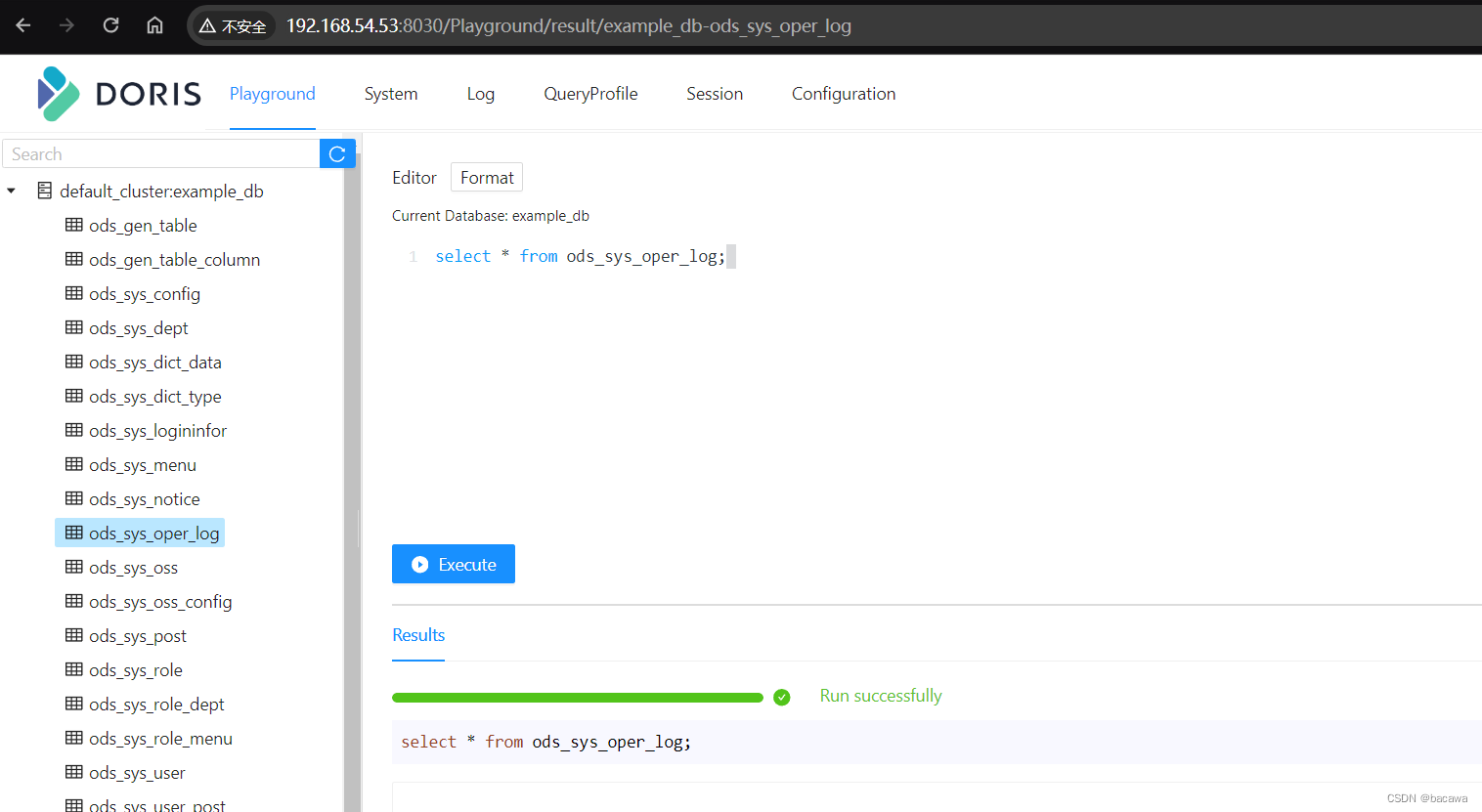
三、完结
完!