KVM 内存概述
- CPU缓存基本概念
- 内存基本概念
- EPT和VPID
- 内存过载使用
- 大页
- 透明大页
- 透明大页使用
- KSM
- NUMA
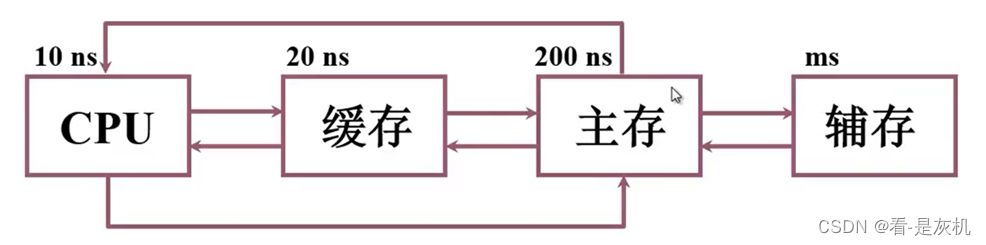
CPU缓存基本概念
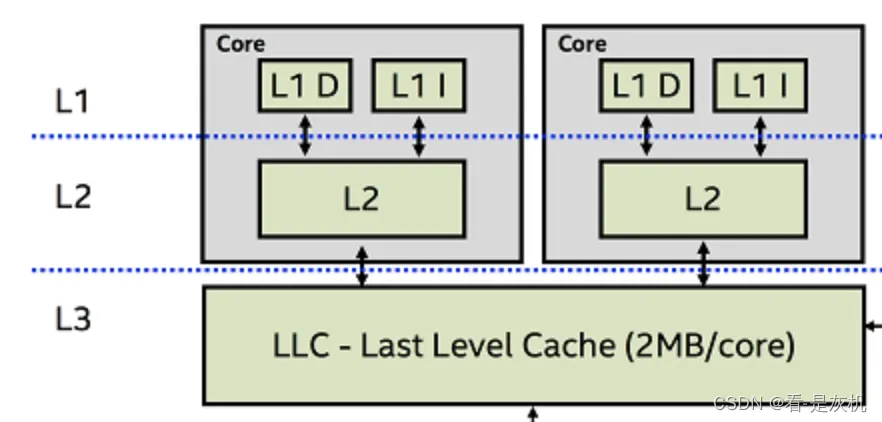
CPU工作过程中会直接读取内存的数据,而大部分同学对内存的感觉是内存条的一个概念,其实CPU中也有内存的概念,称之为L1-L3缓存。
L1,L2,L3 指的都是CPU的缓存,速度快,成本高,CPU查找数据时首先在L1,然后L2,最后L3,如果没有,才到内存中,设计的主要目的也是提高速度。
注:最开始CPU是直接访问内存的,直到80386的芯片组增加了对可选的Cache的支持,目前L4也已经出来。
L1 Cache:(一级缓存)是CPU第一层高速缓存,分为数据缓存D和指令缓存I。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM(SRAM)组成,一般服务器CPU的L1缓存的容量通常在32—256KB。静态随机存取存储器(SRAM):由6个晶体管组成,体积大,性能高,不需周期性充电,断电后数据丢失
动态随机存取存储器(DRAM):由1个晶体管和1个电容组成,体积小,性能低,需要周期性给电容充电,断电后数据丢失L2 Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,现在家庭用CPU容量最大的是512KB,而服务器和工作站上用CPU的L2高速缓存更高达256-1MB,有的高达2MB或者3MB。
L3 Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。而实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力。在服务器领域增加L3缓存,在性能方面仍然有显著的提升。是多核心共享缓存。
# 查看L1-3缓存,以cpu0为例
[root@node ~]# cd /sys/devices/system/cpu/cpu0/cache/
[root@node cache]# ls
index0 index1 index2 index3
# index0和index1分别为L1的数据和指令缓存,type为Data和Instruction
[root@node cache]# cat index{0,1}/{id,level,type,size}
0
1
Data
32K
0
1
Instruction
32K
# 查看L2和L3信息
[root@node cache]# cat index{2,3}/{id,level,type,size}
0
2
Unified
1024K
0
3
Unified
33792K
内存基本概念
链接
EPT和VPID
内存虚拟化的目的是给虚拟客户机操作系统提供一个从0地址开始的连续物理内存空间,同时在多个客户机之间实现隔离和调度。客户机的内存访问路径依次是GVA(客户机虚拟地址,Guest Virtual Address) > GPA(客户机物理地址,Guest Physical Address) > HVA(宿主机虚拟地址,Host Virtual Address) > HPA(宿主机物理地址,Host Physical Address)。
在ETP(Extended Page Tables,扩张页表)特性加入之前,主要使用影子页表(Shadow Page Tables)来维护GVA > HPA之间的映射,每一份客户机操作系统页表对应一份影子页表,实现了从GVA到HPA的直接转换。但其缺点是,影子页表的实现非常复杂,导致其开发、调试和维护都十分困难,而且由于需要为每一份客户机操作系统进程维护一份影子页表,导致内存消耗较大。所以Intel提拱了EPT技术(AMD类似的技术叫NPT)。
EPT是针对内存管理单元MMU的虚拟化扩展,直接在硬件上支持GVA > GPA > HPA地址转换,降低了内存虚拟化实现的复杂度,也提升了内存虚拟化的性能。使用EPT的情况下,客户机内部的Page Fault、INVLPG指令、CR3寄存器的访问等都不会引发VM-Exit,而且EPT只需要维护一张EPT页表即可,降低了内存的开销。
VPID(Virtual Processor Identifers,虚拟处理器标识)是在硬件上对TLB资源管理的优化,通过在硬件上为每个TLB项增加一个标识,用于不同的虚拟处理器的地址空间,从而能够区分Hypervisor和不同处理器的TLB。在这之前不同的客户机的逻辑CPU在切换时需要重新刷新TLB,有了VPID后可以避免每次进行VM-Entry和VM-Exit时TLB全部失效,提高了VM切换的效率。由于有了这些在VM切换后仍然继续存在的TLB项,硬件减少了一些不必要的页表访问,减少了内存访问次数,从而提高了Hypervisor和客户机的运行速度。VPID也会对客户机的实时迁移(Live Migration)有很好的效率提升,会节省实时迁移的开销,提升实时迁移的速度,降低迁移的延迟(Latency)。
# 查看系统是否支持EPT和VPID
[root@node ~]# grep -Ei "ept|vpid" /proc/cpuinfo
# 打开EPT和VPID
[root@node ~]# cat /sys/module/kvm_intel/parameters/ept
Y
[root@node ~]# cat /sys/module/kvm_intel/parameters/vpid
Y
# 加载kvm_intel模块时加载EPT和VPID功能
[root@node ~]# modprobe kvm_intel ept=1,vpid=1
内存过载使用
大页
x86架构的CPU默认使用4KB大小的内存页面,这也是为什么许多内存默认分为4KB的原因。现在CPU已经可以支持大于4KB页面的能力,这一点也可以在cpuinfo的flags中看到,如pae、pse、pdpe1gb等。使用了大页(Huge Page)后,内存页的数量会减少,节约了页表信息占用的内存数量,并且所需地址转换也减少,TLB缓存命中率增加,提高了内存访问的性能。
PAE标志:启用物理页拓展(简称PAE),可以最多寻址64GB物理内存,否则最多寻址4GB物理内存。
PSE标志:用于启用大页面支持。在32位保护模式下,PAE=1时,大页面是2MB,当PAE=0时,大页面是4MB。
pdpe1gb标志:支持1GB的内存大页。
大页虽然能提高系统内存的使用效率及性能,但也有缺点:
1、大页必须在使用前就准备好。
2、应用程序代码必须显式地使用大页 (一般是调用mmap、shmget系统调用,或用libhugetlbfs库对它们封装)。
3、大页必须常驻物理内存中,不能交换到交换分区中。
4、需要超级用户权限来挂载 hugetlbfs 文件系统,尽管挂载之后可以指定挂载点的uid、gid、mode 等使用权限供普通用户使用。
5、如果预留了大页内存但没实际使用,就会造成物理内存的浪费。
透明大页
透明大页针对如上缺点,作出一些调整。首先在使用透明大页时,普通使用hugetlbfs大页的依然可以使用,在没有普通大页使用的时候,才开始使用透明大页。且透明大页对所有应用程序都是透明的,不需要任何修改及,即可使用。同时透明大页在交换到交换空间时,以常规的4kb大小进行存储。
使用透明大页时,如果因为内存碎片导致大页内存分配失败,系统可以优雅的使用常规的4kb页替换,且不会发生任何错误、故障或用户态的通知。而当系统内存较为充裕、有很多的大页可用时,常规分配的物理内存可以通过khugepaged内核线程自动迁往透明大页内存,内核线程khugepaged的作用是,扫描正在运行的进程,然后试图将使用的常规内存页转换到使用大页。目前透明大页仅支持匿名内存。
透明大页使用
1、编译Linux内核时,配置透明大页支持
CONFIG_HAVE_ARCH_TRANSPARENT_HUGEPAGE=y
CONFIG_TRANSPARENT_HUGEPAGE=y
CONFIG_TRANSPARENT_HUGEPAGE_ALWAYS=y
# CONFIG_TRANSPARENT_HUGEPAGE_MADVISE is not set
也可以在启动Linux内核时配置transparent_hugepage=[always|madvise|never]
查看透明大页配置
# 开启透明大页,madvise表示仅在“MADV_HUGEPAGE”标识的内存区域使用透明大页,never关闭
[root@node ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
# 表示系统在发生页故障时同步地做内存碎片的整理工作,由于运行频率较高,可能影响性能
[root@node ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
[always] madvise never
# 表示在khugepaged进程运行时进行内存碎片的整理工作,运行频率较低
[root@node ~]# cat /sys/kernel/mm/transparent_hugepage/khugepaged/defrag
1
# 查看系统使用透明大页情况,如果想查看具体应用程序使用情况,可查看cat /proc/进程号/smaps | grep AnonHugePages
[root@node ~]# grep AnonHugePages /proc/meminfo
AnonHugePages: 14336 kB
KSM
KSM(Kemel SamePage Merging,内核同页合并)允许内核在两个或多个进程(包括虚拟客户机)之间共享完全相同的内存页。KSM 让内核扫描检查正在运行中的程序并比较它们的内存,如果发现它们有完全相同的内存区域或内存页就将多个相同的内存合并为一个单一的内存页,并将其标识为“写时复制”。这样可以起到节省系统内存使用量的作用。之后,如果有进程试图去修改被标识为“写时复制”的合并内存页,就为该进程复制出一个新的内存页供其使用。
在QEMU/KVM 中,一个虚拟客户机就是一个 QEMU 进程,所以使用KSM 也可以实现多个客户机之间的相同内存合并。而且,如果在同一宿主机上的多个客户机运行的是相同的操作系统或应用程序,则客户机之间的相同内存页的数量就可能比较大,这种情况下KSM的作用就更加显著。在 KVM 环境下使用 KSM,还允许 KVM 请求哪些相同的内存页是可以被共享而合并的,所以 KSM 只会识别并合并那些不会干扰客户机运行且不会影响宿主机或客户机运行的安全内存页。
由于KSM对KVM宿主机中的内存使用有较大的效率和性能的提高,所以一般建议打开KSM功能,并且使用时应保证系统的交换空间足够大,因为如果被合并的内存页需要修改时,会被重新复制出来一个新的内存页,占用更多的内存空间,因此导致系统内存不足。
KSM的使用也会占用CPU的资源,如果一个宿主机上的各进程间运行的操作系统或应用程序不相同,就要考虑使用KSM是否符合其所需要了。
RHEL6和RHEL7中提供了两个服务KSM和ksmtuned,ksmtuned会一直保持循环执行,来动态调节ksm服务运行情况,配置文件/etc/ksmtuned.conf。
KSM配置
# ksm的内核进程
[root@iZ8vb4294tuxbs742pmxveZ ~]# ps -ef | grep ksm
root 37 2 0 Jan10 ? 00:00:00 [ksmd]
root 19980 19952 0 16:09 pts/0 00:00:00 grep --color=auto ksm
# ksm相关配置
[root@iZ8vb4294tuxbs742pmxveZ ~]# cd /sys/kernel/mm/ksm/
[root@iZ8vb4294tuxbs742pmxveZ ksm]# ll
total 0
-r--r--r-- 1 root root 4096 Jan 29 16:10 full_scans
-rw-r--r-- 1 root root 4096 Jan 29 16:10 max_page_sharing
-rw-r--r-- 1 root root 4096 Jan 29 16:10 merge_across_nodes
-r--r--r-- 1 root root 4096 Jan 29 16:10 pages_shared
-r--r--r-- 1 root root 4096 Jan 29 16:10 pages_sharing
-rw-r--r-- 1 root root 4096 Jan 29 16:10 pages_to_scan
-r--r--r-- 1 root root 4096 Jan 29 16:10 pages_unshared
-r--r--r-- 1 root root 4096 Jan 29 16:10 pages_volatile
-rw-r--r-- 1 root root 4096 Jan 29 16:10 run
-rw-r--r-- 1 root root 4096 Jan 29 16:10 sleep_millisecs
-r--r--r-- 1 root root 4096 Jan 29 16:10 stable_node_chains
-rw-r--r-- 1 root root 4096 Jan 29 16:10 stable_node_chains_prune_millisecs
-r--r--r-- 1 root root 4096 Jan 29 16:10 stable_node_dups
full_scans:记录已经对所有可合并的内存区域扫描过的次数。
pages_shared:记录正在使用中的共享内存页数量
pages_sharing:记录有多少内存页正在使用被合并的共享页,不包括合并内存页本身。这是实际节省的内存页数量。
pages_to_scan:记录在ksmd进程休眠之前扫描的内存页的数量。
pages_unshared:记录无重复内容而不可以被合并的内存页数量。
pages_volatile:记录因为内容很容易变化而不被合并的内存页数量。
run:控制ksmd是否运行。0:停止运行但是保存合并的内存页;1:马上运行ksmd;2:停止运行,并且分立已经合并的所有内存页。
sleep_millisecs:ksmd进程的休眠时间,单位毫秒。
NUMA
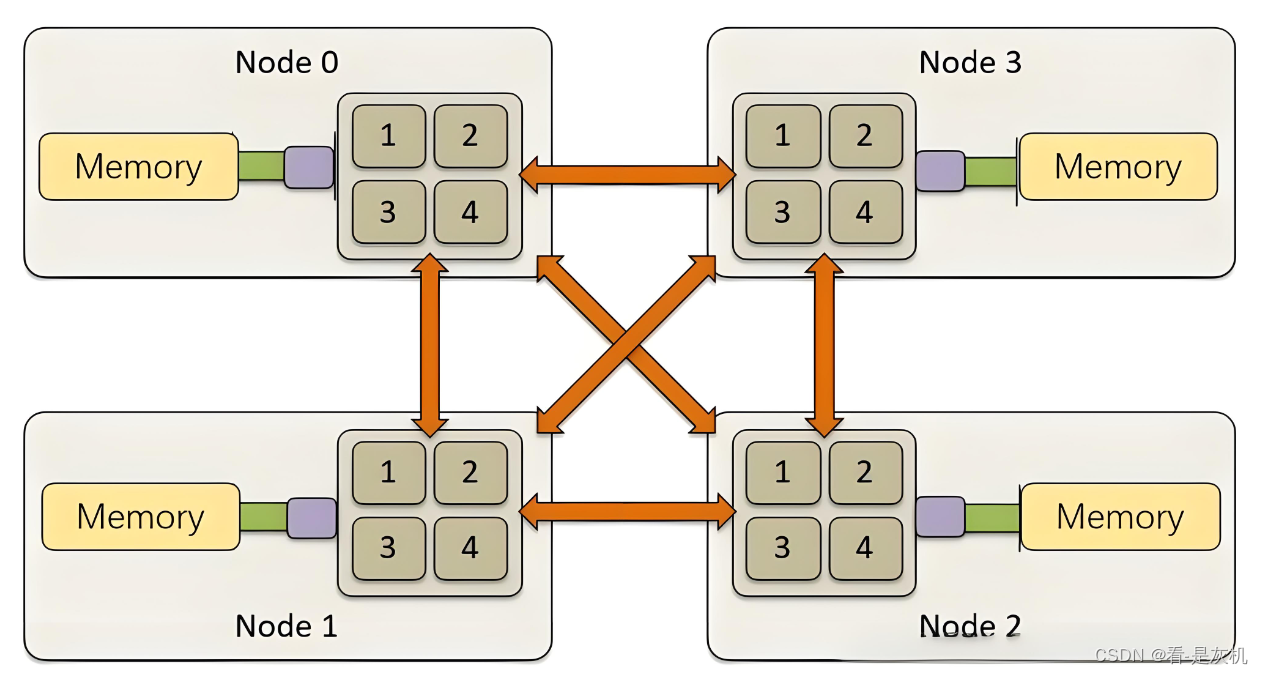
NUMA(Non-Uniform Memory Access,即非一致性内存访问),将处理器和内存划分成一个个的节点,每个Node有自己独立的内存空间和PCIE总线系统,各个CPU间通过QPI总线进行互通,处理器访问自己节点内的内存会比访问其他节点的内存快。
# 安装numactl,会默认一并安装numastat
[root@iZ8vb4294tuxbs742pmxveZ ~]# yum -y install numactl
# 没有numastat,则安装numastat
[root@iZ8vb4294tuxbs742pmxveZ ~]# yum -y install numastat
# 安装numad
[root@iZ8vb4294tuxbs742pmxveZ ~]# yum -y install numad
numastat用来查看某个进程或者这个系统的内存消耗在各个NUMA节点的分布情况。
numad是一个后台进程,也是一个可以自动管理NUMA亲和性的工具,能实时监控NUMA拓扑结构和资源使用,并动态调整。
numactl:可以在程序起来时就指定好他的NUMA节点,还可以设置共享内存、大页文件系统的内存策略,以及进程的CPU和内存的亲和性。