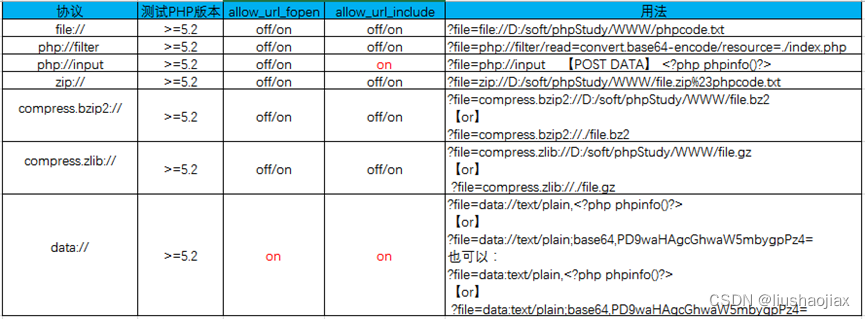
众所周知,双写机制、重做日志文件是mysql的InnoDB引擎的几个重要特性之二。其中两者的作用都是什么,很多文章都有分析,如,双写机制(Double Write)是mysql在crash后恢复的机制,而重做日志文件(Redo Log File)也是mysql崩溃恢复机制的一部分。但是,这两者是如何保证mysql能够正确恢复数据的呢?对此,我在看书查证和思考过程中,产生了很多的疑问,也有一些收获,写在下面。
一,介绍双写机制、重做日志文件
首先,我先介绍或者说概括一下双写机制,和重做日志文件。在《MySQL技术内幕 InnoDB技术引擎》[1]一书中,双写机制部分介绍原文如下:
如果说Insert Buffer带给InnoDB存储引擎的是性能上的提升,那么doublewrite(两次写)带给InnoDB存储引擎的是数据页的可靠性。
当发生数据库宕机时,可能InnoDB存储引擎正在写入某个页到表中,而这个页只写了一部分,比如16kb的页,只写了前4kb,之后就发生了宕机,这种情况被成为部分写失效(partial page write)。在InnoDB存储引擎未使用doublewrte技术前,曾经出现过因为部分写失效而导致数据丢失的情况。
有经验的DBA也许会想,如果发生写失效,可以通过重做日志进行恢复。这是一个办法,但是必须清楚的意识到,重做日志中记录的是对页的物理操作,如偏移量800,写’aaa’记录。如果这个页本身已经发生了损坏,再对其进行重做是没有意义的。这就是说,在应用(apply)重做日志之前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是doublewrite。在InnoDB存储引擎中doublewrite的体系架构如图2-5所示。
doublewrite由2部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另一部分是物理磁盘上共享表空间中连续的128个页,即2个区(extent),大小同样为2MB。在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序的写入共享表空间的物理磁盘上,然后马上调用fsync函数,同步磁盘,避免缓冲写带来的问题。在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer中的页写入各个表空间文件中,此时的写入则是离散的。
…
重做日志部分原文如下:
在默认情况下,在InnoDB存储引擎的数据目录下会有2个名为ib_logfile0和ib_logfile1的文件。在mysql官方手册中将其称为InnoDB存储引擎的日志文件,不过准确的定义应该是重做日志文件(redo log file)。为什么强调是重做日志文件呢?因为重做日志文件对于InnoDB存储引擎至关重要,它们记录了对于innoDB存储引擎的事务日志。
当实例或介质失败(media failure)时,重做日志文件就能派上用场。例如,数据库由于所在主机掉电导致实例失败,InnoDB存储引擎会使用重做日志恢复到掉电前的时刻,以此来保证数据的完整性。
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组下至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。为了得到更高的可靠性,用户可以设置多个的镜像日志组(mirrored log groups),将不同的文件组放在不同的磁盘上,以此提高重做日志的高可用性。在日志组中每个重做日志文件的大小一致,并以循环写入的方式运行。InnoDB存储引擎先写重做日志文件1,当达到文件的最后时,会切换至重做日志文件2,再当重做日志文件2也被写满时,会再切换到重做日志文件1中。
…
双写和重做日志不是单独运行的,这两者是结合起来运行的。在文章[4]中,描述了双写机制、重做日志运行的原理。
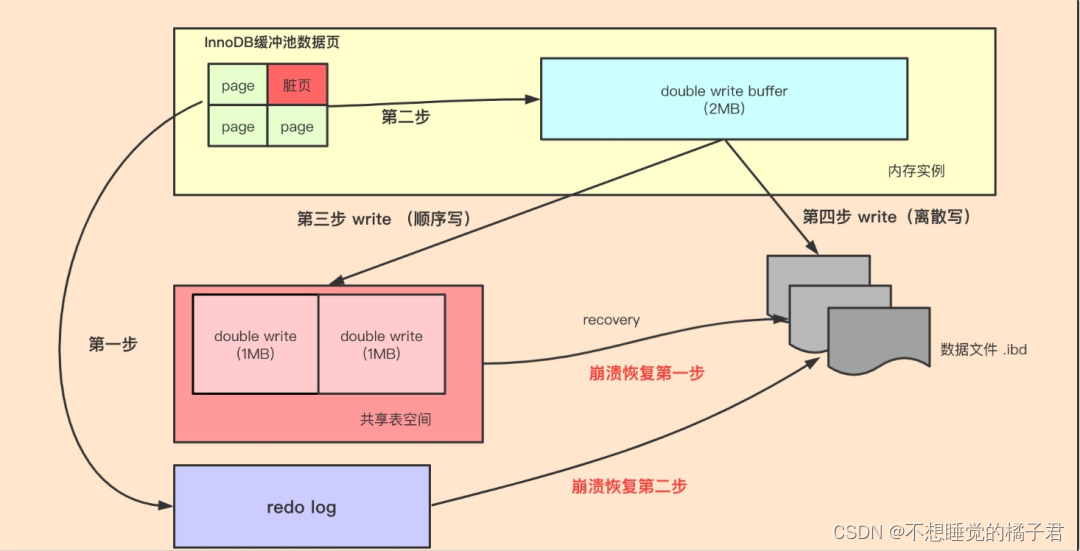
第一步,master thread会每秒将写操作的重做日志缓冲刷写到redo log中。
第二步,通过memcpy函数将脏页copy到doubewrite buffer(内存)中。
第三步,将doublewrite buffer第一次刷写fsync到磁盘(系统表空间)。
第四步,将doublewrite buffer第二次刷写fsync到磁盘(独立表空间)。
二,问题及思考结果
1,双写机制的作用是什么?
书中[1]写到,双写机制的作用是为了应对部分页写入的情况。实际上,不止是书中写的”16kb的页,只写了前4kb,就发生了宕机“这种情况。在写入的时候,怎么会完完整整的写完一个Linux的页才宕机呢?(32位linux系统支持4k的页[2])
实际上,更可能的是,假设一个16kb的脏页,写入了前4k的页,正在写入第2个4k的linux页,结果断电了。此时导致的必然结果就是第二个页的格式错误。
这种部分页写入的情况,会导致数据的格式错误,无法通过mysql的自检,进而需要双写机制来恢复数据。
因此,你看到书中[1]举的栗子中,mysql在使用双写机制恢复的时候,Info信息是:
InnoDB: Crash recovery may have failed for some .ibd files!
InnoDB: Restoring possible half-written data pages from the doublewrite
也就是说,双写机制的作用,是恢复因为部分页写入导致发生数据格式错误的页。
2,双写机制也需要写入系统表空间的磁盘中,同样的数据,也要第二次写入数据所在的独立表空间的磁盘空间,那有没有可能,在双写机制向系统表空间中写入(第一次写)的时候crash断电呢?
书中[1]写到:
doublewrite由2部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另一部分是物理磁盘上共享表空间中连续的128个页,即2个区(extent),大小同样是2MB。在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,然后马上调用fsync函数,同步磁盘,避免缓冲写带来的问题。在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer中的页写入各个表空间文件中,此时的写入是离散的。
首先,我们需要知道,随机IO和顺序IO在性能上的区别。在《高性能mysql》[3]中,进行了随机IO和顺序IO的对比,在举例中描述”相比之下顺序读可以每秒读500000行——是随机读的5000“倍。这是3个数量级的差别,即使栗子中的情况和实际机器的性能、实际读写的情况有差别,也不会差太多。也就是说,随机IO和顺序IO是有大约三四个数量级上的速度差别的。
双写机制的2次写是连续的,总共为2MB。mysql每秒最多刷新100个脏页到独立表空间中。100个脏页为1600kb,即1.6MB,因此可以说双写机制提供的2MB是够用的。但是问题是这100个脏页可能是随机IO。
假设master thread的写入压力比较大,每秒刷新100个脏页,会第一步先向redo log磁盘文件中写入、第二步将脏页memcpy到内存中的双写buffer中,第三步是将双写buffer fsync到系统表空间的双写文件中,最后,将这100个脏页刷写到独立表空间的磁盘文件中。2MB的数据,第1、3步都是顺序IO,磁盘寻址一次定位到文件后,会顺序写入2MB数据即可,第2步是内存中的复制,只有第4步,是要将100个mysql页随机IO写入磁盘,而一个32位linux系统支持4kb的页,意味着系统需要在磁盘中寻址100*(16 / 4)= 400次。(怕读者们混乱,linux系统的页举例使用了《MySQL技术内幕》中举例的4kb大小的页,而不是64位系统的8kb页[2])
总之,不难发现,仅以双写机制第一次写入:将数据写入系统表空间,和第二次写入:将数据写入磁盘的独立表空间而言,第一次写入仅需寻址1次,顺序写入2MB数据;而第二次写入,需要最多400次寻址。意味着第一次写入占用的时间仅占总寻址时间的1/(400+1)。因此双写机制在第一次写入时crash的几率是非常小的。(数据的写入时间这里不作讨论,随机IO主要时间在磁盘寻址上)。
至于mysql有没有可能在第一次写入的时候崩溃呢,当然有啦。我很喜欢周sang的那句话,中间件的设计中,很多都是balance,做权衡。InnoDB设计的双写机制,以写入磁盘的1/400寻址时间的性能开销,以及这段时间内crash数据无法正确恢复的微小可能,换来可以保证crash崩溃断电这种极端情况发生时,数据错误时能够恢复到正确的格式,以及配合redo log,InnoDB可以异步写入而不担心数据丢失,无疑是值得的。
3,类似问题2,redo log会不会也在写入的时候crash呢?
有可能,但是可能性很小。
我们看《MySQL技术内幕》[1]中讲述到,
(InnoDB)每秒一次的操作包括:
日志缓冲刷新到磁盘,即使这个事务还没有提交(总是)
合并插入缓冲(可能)
至多刷新100个InnoDB的缓冲池中的脏页到磁盘(可能)
如果当前没有用户活动,则切换到background loop(可能)
日志缓冲指的就是重做日志缓冲(redo log buffer)。此外,引擎会在事务提交时也将日志缓冲刷新到磁盘。
综上可以看出,其实重做日志缓冲会非常勤奋的刷新到redo log中,这样可以保证不会将一次事务的所有刷新磁盘的压力都堆积到一次刷新中。
其次,redo log是顺序IO,会在默认的两个redo log中循环写,一个文件写满了就在另一个文件中写(脏数据写入磁盘后会从redo log中删除)。从问题2中我们讲了,顺序IO就是要比同数据量的随机IO快。
最后[1],InnoDB存储引擎的重做日志文件记录的是关于每个页(page)的更改的物理情况,如偏移量800,写’aaa’记录。这样就保证了每次写操作需要记录的redo log的大小很小。
综上所述,使得redo log的写入很快,远快于redo log记录的写操作在磁盘中写入的时间。
4,假设写入压力很大,mysql每秒100个脏页写入都无法把缓冲池中的脏页刷写完,那么在crash后,仅靠双写的2MB数据无法完全恢复数据,那么要怎么恢复数据呢?
首先需要明确,那个2MB大小的双写文件,不是为了恢复数据用的,它仅仅是为了保证写入时发生crash导致部分页写入,用来恢复发生部分页写入那部分页的正确格式的。至于恢复缓冲池中的脏页数据,是redo log的活儿。
《MySQL技术内幕》[1]中,写到,在InnoDB版本1.2.x之前,redo log总大小不得超过4GB,在1.2.x之后,限制扩大到512GB。
也就是说,即使mysql的写入压力很大,每秒100个脏页的写入都不够,InnoDB的缓冲池中积压了很多旧的写入请求的脏页,还有很多脏页没有写入磁盘,但是它们都已经写入redo log,最多512G,它们这些脏页都可以写入到redo log中。
而新的写入操作,也会每秒的日志缓冲刷写到磁盘的redo log中,最大限度的保存脏页数据。
三,写在最后
其实从这里我个人觉得,双写机制和重做日志文件,是InnoDB引擎能够实现异步IO的关键,它们结合起来最大限度的保证了即使是异步IO,内存中的脏页数据最后也可以落盘,即事务的持久性,并且崩溃不会导致部分页写入。而异步IO,无疑很大的提升了InnoDB的写入性能。
或者更抽象的说,InnoDB在做了一定程度的design and balance后,以微小的性能开销和很小的数据丢失风险,保证了InnoDB的异步IO和、页数据的持久性以及crash时的数据正确性。
在谈双写机制时,离不开重做日志保证数据完整性,在谈重做日志文件时,离不开双写机制保证数据最后写的页不发生部分页写入。
参考文章:
[1],MySQL技术内幕 InnoDB技术引擎, 作者:姜承尧
[2],Linux内核设计与实现,作者:Robert Love
[3],高性能mysql,作者:Baron Scbwartz,Peter Zaitsev,Vadim Tkacbenko
[4],MySQL双写缓冲区(Doublewrite Buffer)