各位CSDN的uu们你们好呀,这段时间小雅兰的内容仍然是C++string类的使用的内容,下面,让我们进入string类的世界吧!!!
string类的常用接口说明
string - C++ Reference
string类的常用接口说明
string类对象的修改操作
insert
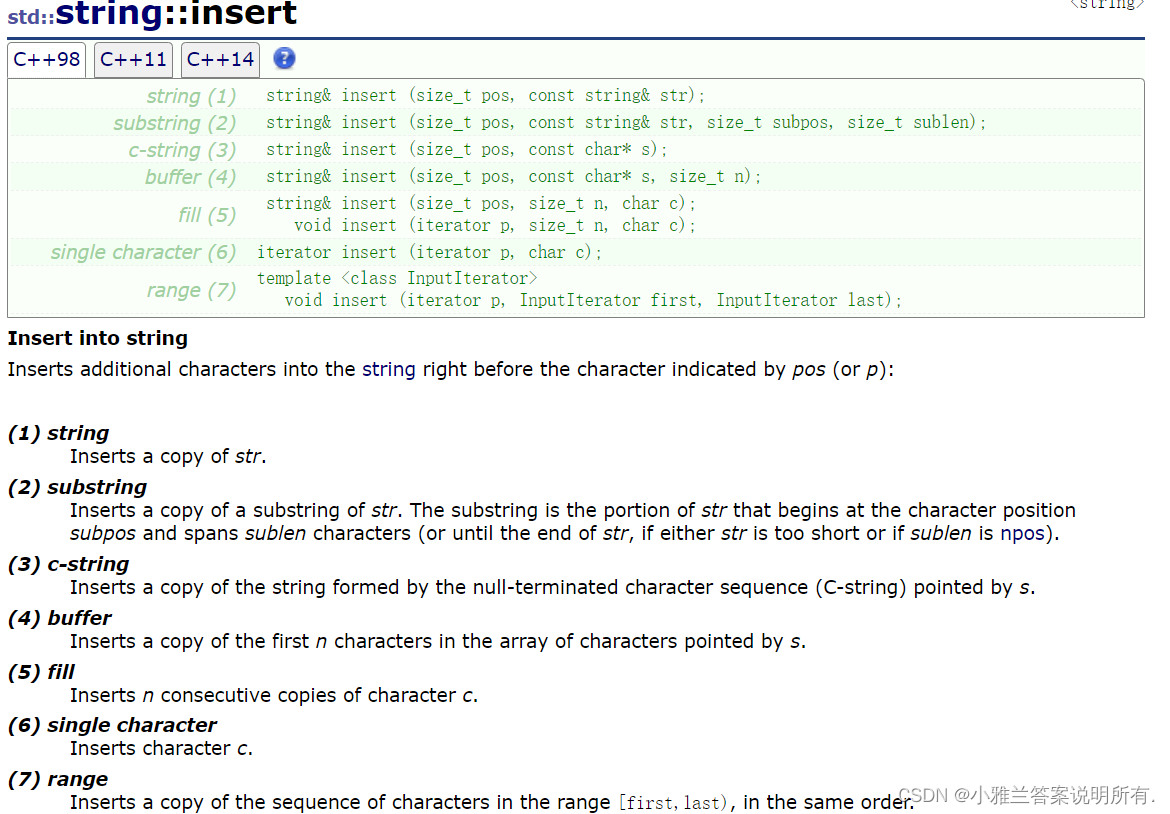

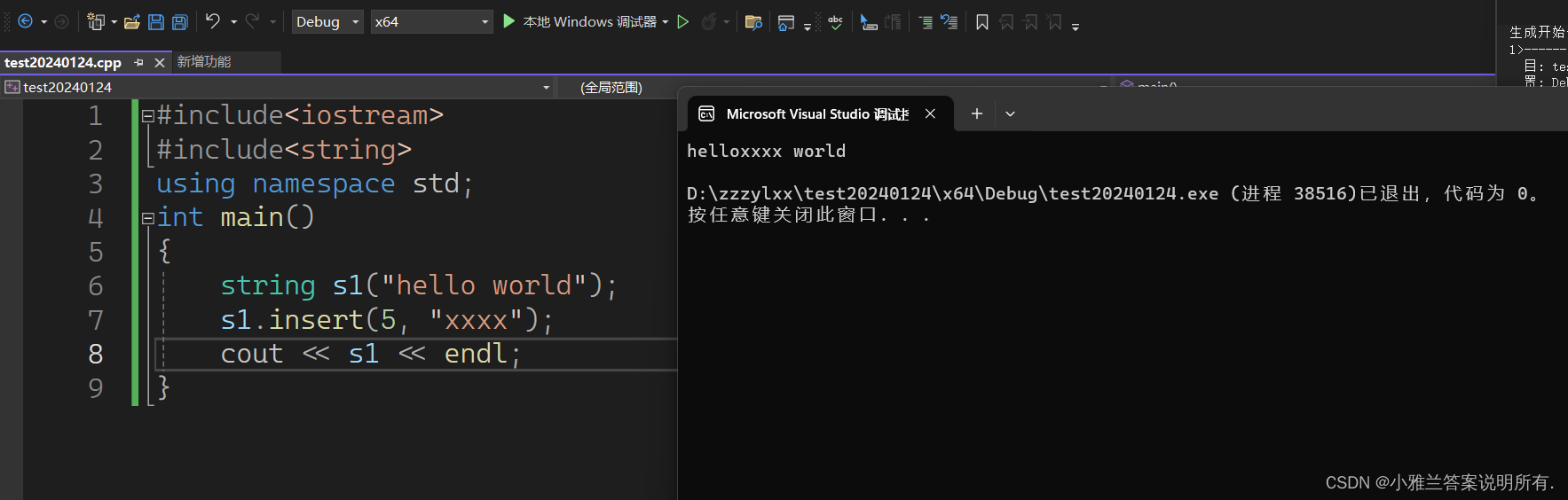
这是在第五个位置插入xxxx这个字符串!
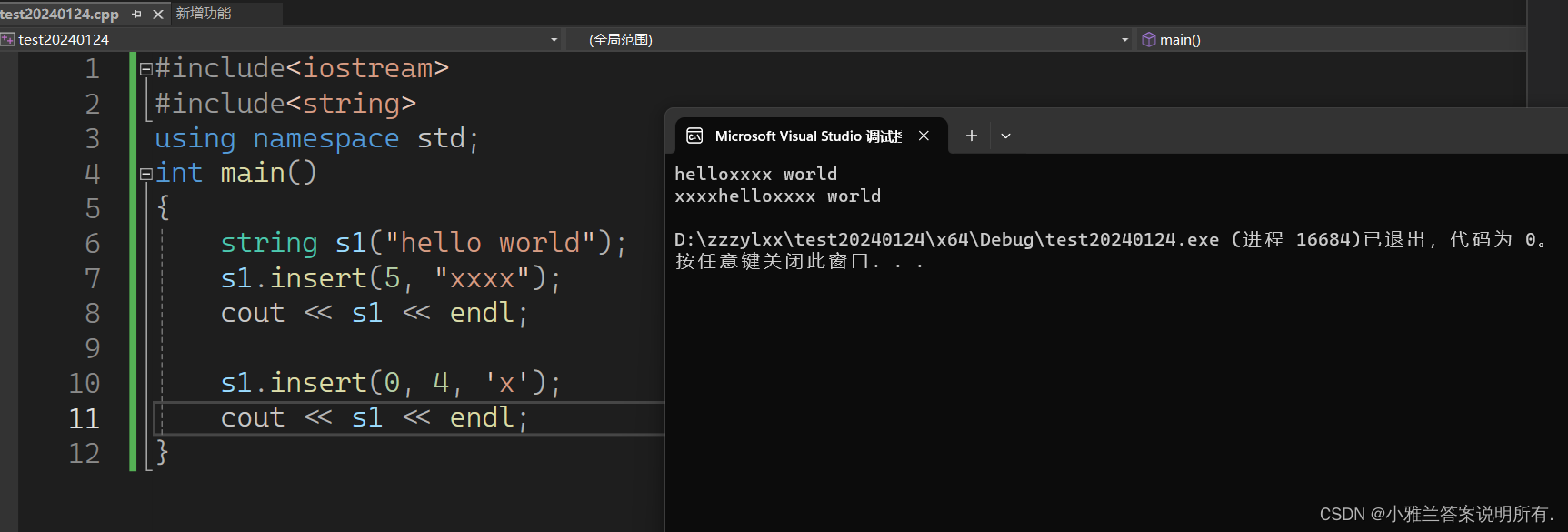
下面的代码的意思是头插4个x字符!
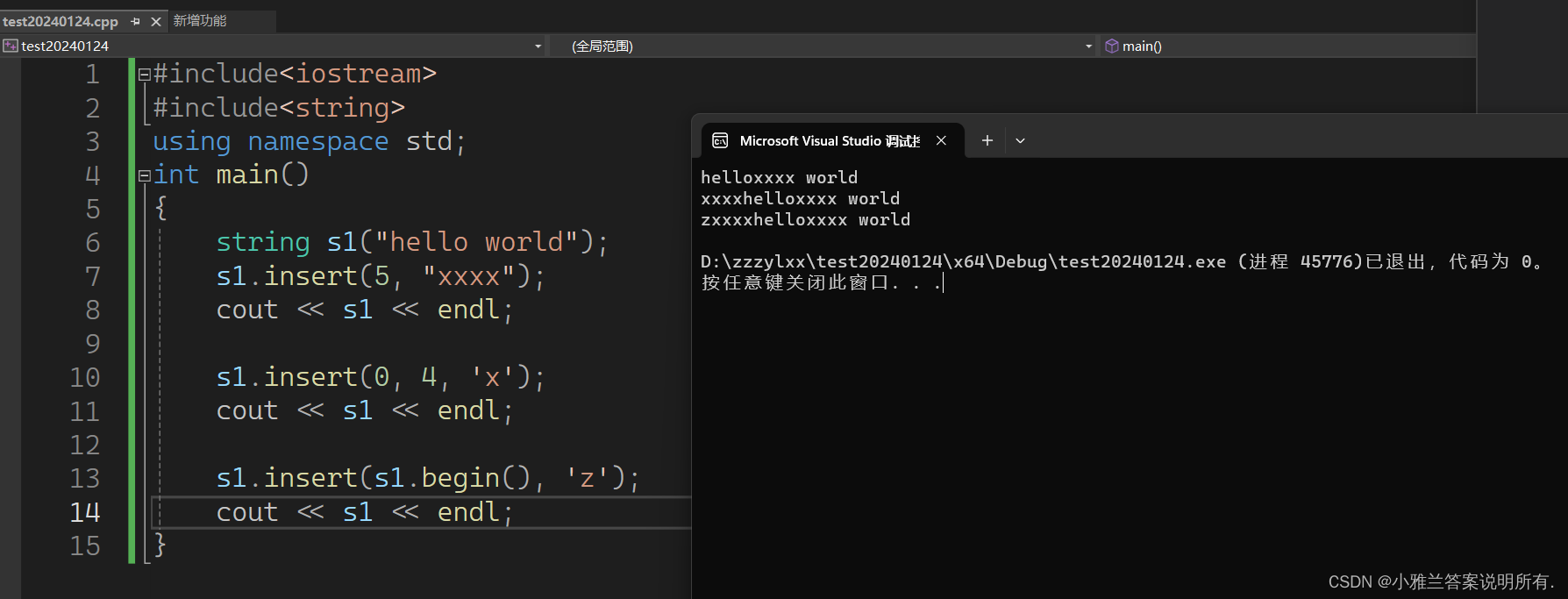 头插还可以这么写,用迭代器的方式!
头插还可以这么写,用迭代器的方式!
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("hello world");
s1.insert(5, "xxxx");
cout << s1 << endl;
s1.insert(0, 4, 'x');
cout << s1 << endl;
s1.insert(s1.begin(), 'z');
cout << s1 << endl;
return 0;
}insert最常见的用法还是插入字符和插入字符串!
严格来说,对于string类,insert是能少用就少用!
erase
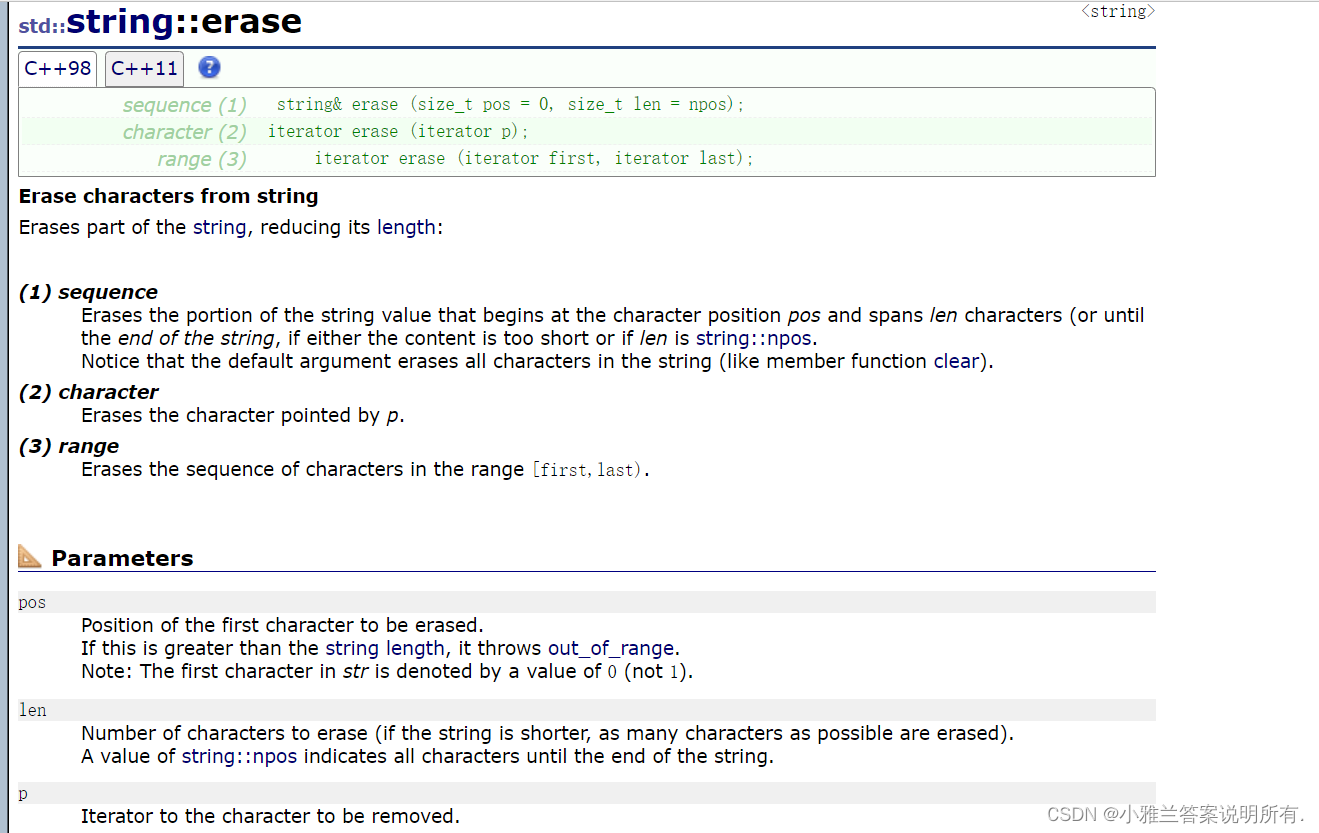
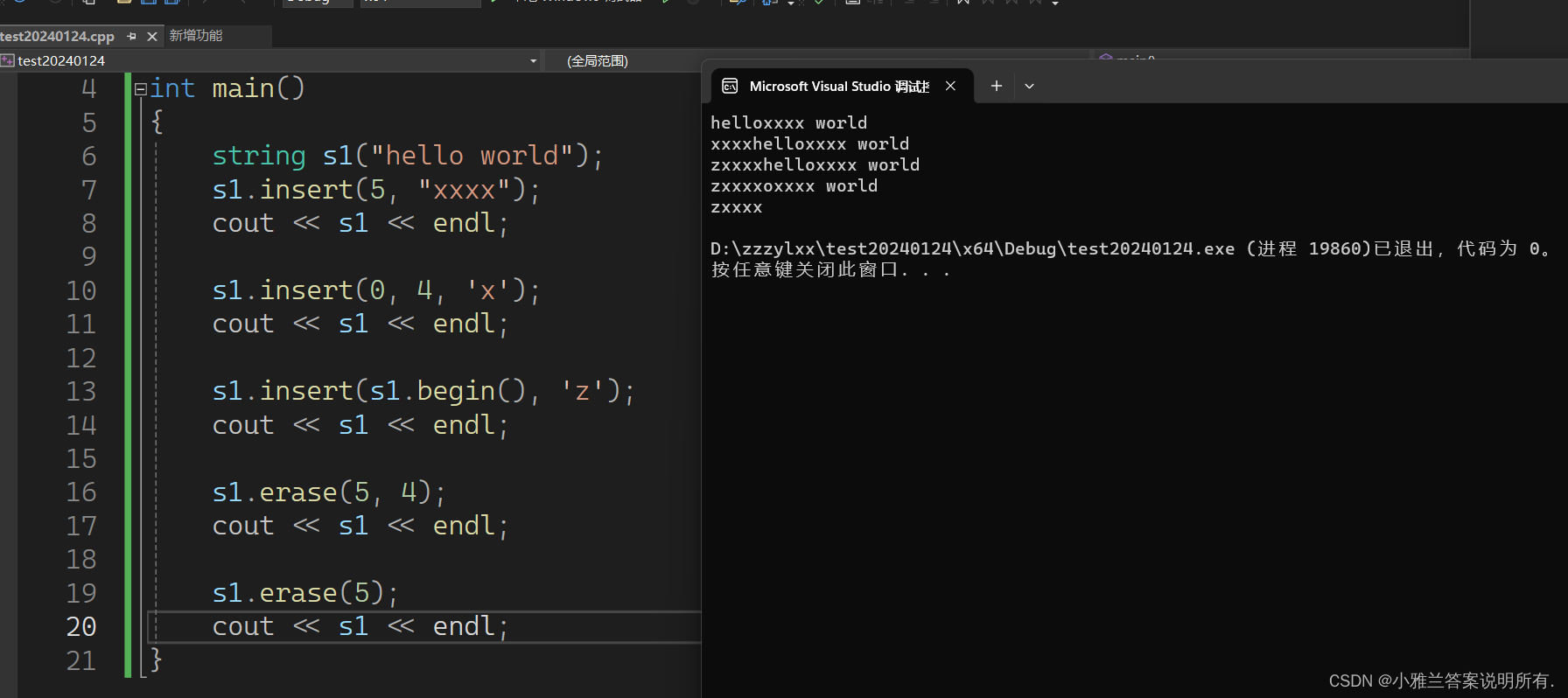 下面两段代码的意思是:从第五个位置开始,删除四个字符
下面两段代码的意思是:从第五个位置开始,删除四个字符
从第五个位置开始,后面有多少个字符就删多少个字符!
assign
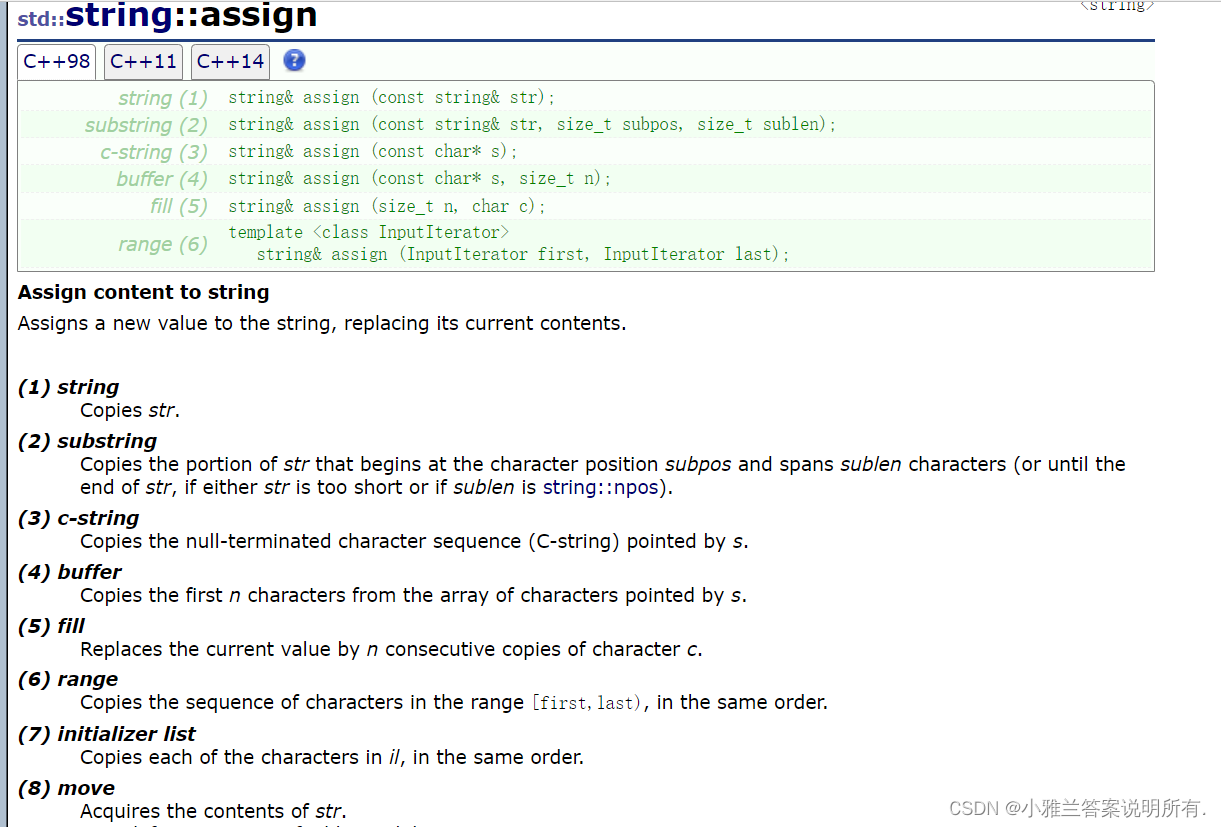

#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("hello world");
s1.assign(s1);
cout << s1 << endl;
s1.assign(s1, 4, 7);
cout << s1 << endl;
s1.assign("pangrams are cool", 8);
cout << s1 << endl;
s1.assign("C-string");
cout << s1 << endl;
return 0;
} 
replace
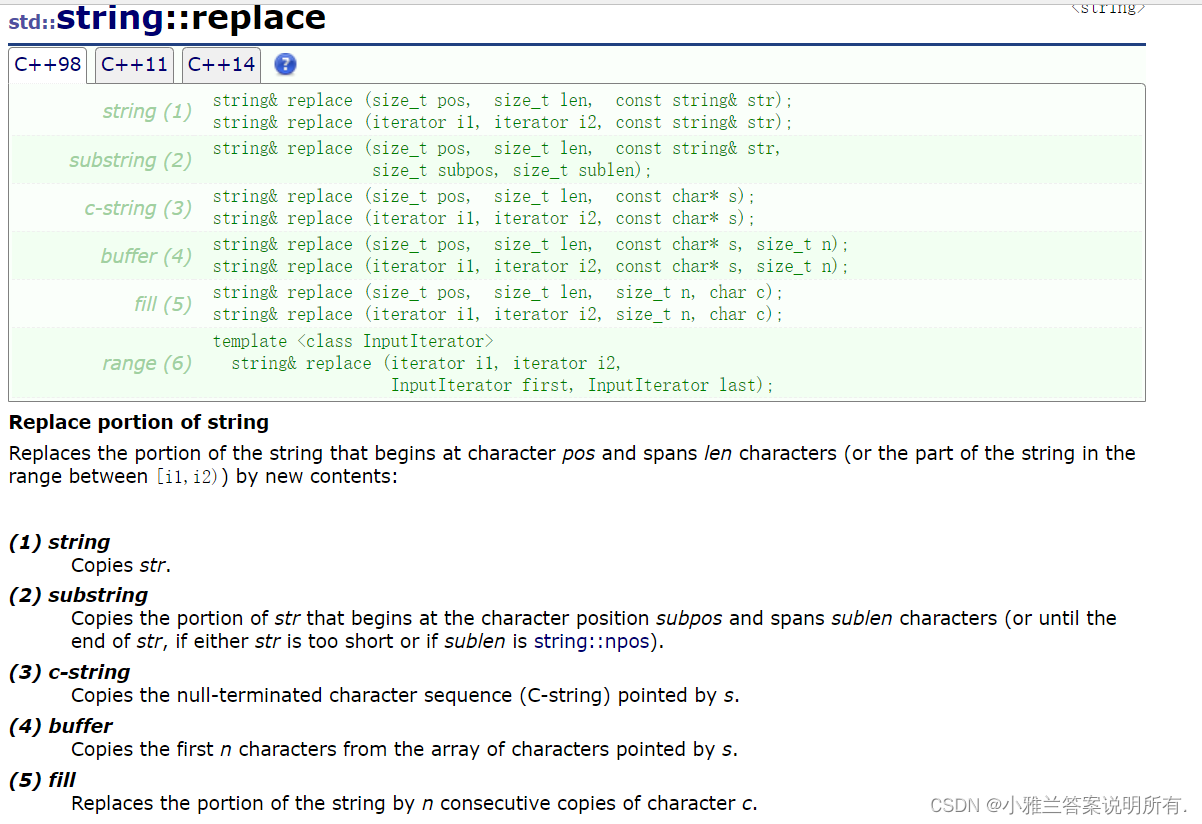
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1("hello world hello lsy");
cout << s1 << endl;
//所有的空格替换成%20
size_t pos = s1.find(' ');
while (pos != string::npos)
{
s1.replace(pos, 1, "%20");
pos = s1.find(' ');
}
cout << s1 << endl;
return 0;
}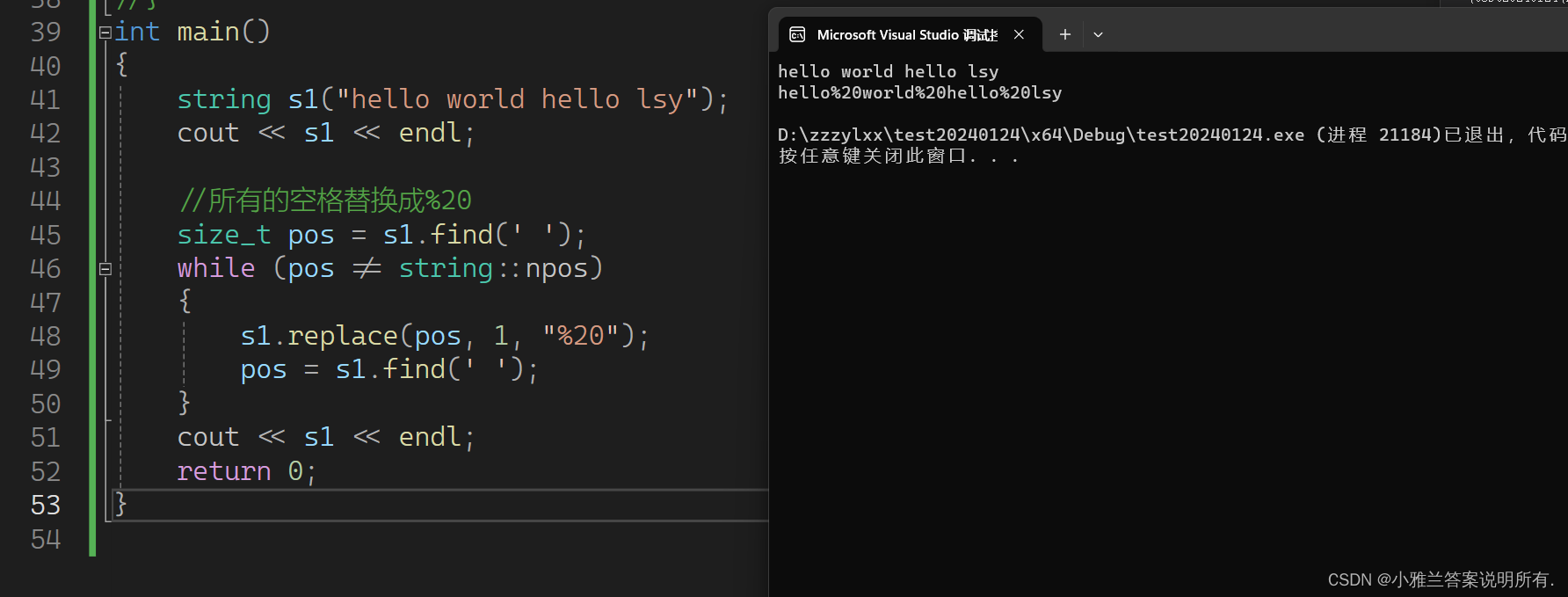
以前在学习C语言的时候,就写过程序实现这个功能,只是那时候还颇为复杂,学习了C++的string类之后,就简单多了,但是,这个程序写得还是不够好!
真正的问题是:每次find都要从头开始find,这样显然是没有必要的!
 这样写就好多了!
这样写就好多了!
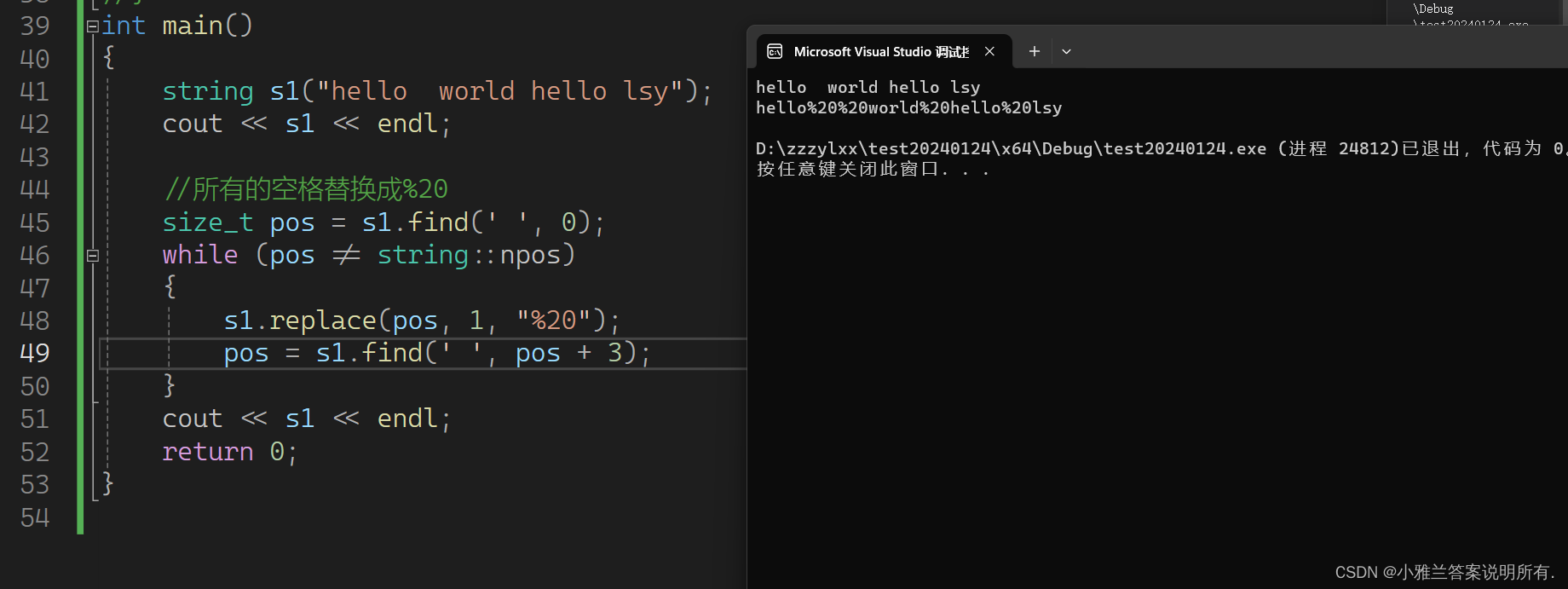
int main()
{
string s1("hello world hello lsy");
cout << s1 << endl;//所有的空格替换成%20
size_t pos = s1.find(' ', 0);
while (pos != string::npos)
{
s1.replace(pos, 1, "%20");
pos = s1.find(' ', pos + 3);
}
cout << s1 << endl;
return 0;
}
但是实际上,这个程序还是不会这样写,因为replace要挪动数据,效率是很低的!
下面,小雅兰就给大家介绍一种高效率的写法:
int main()
{
string s1("hello world hello lsy");
cout << s1 << endl;
//所有的空格替换成%20
size_t pos = s1.find(' ', 0);
while (pos != string::npos)
{
s1.replace(pos, 1, "%20");
//效率很低,能不用就不要用了
pos = s1.find(' ', pos + 3);
}
cout << s1 << endl;
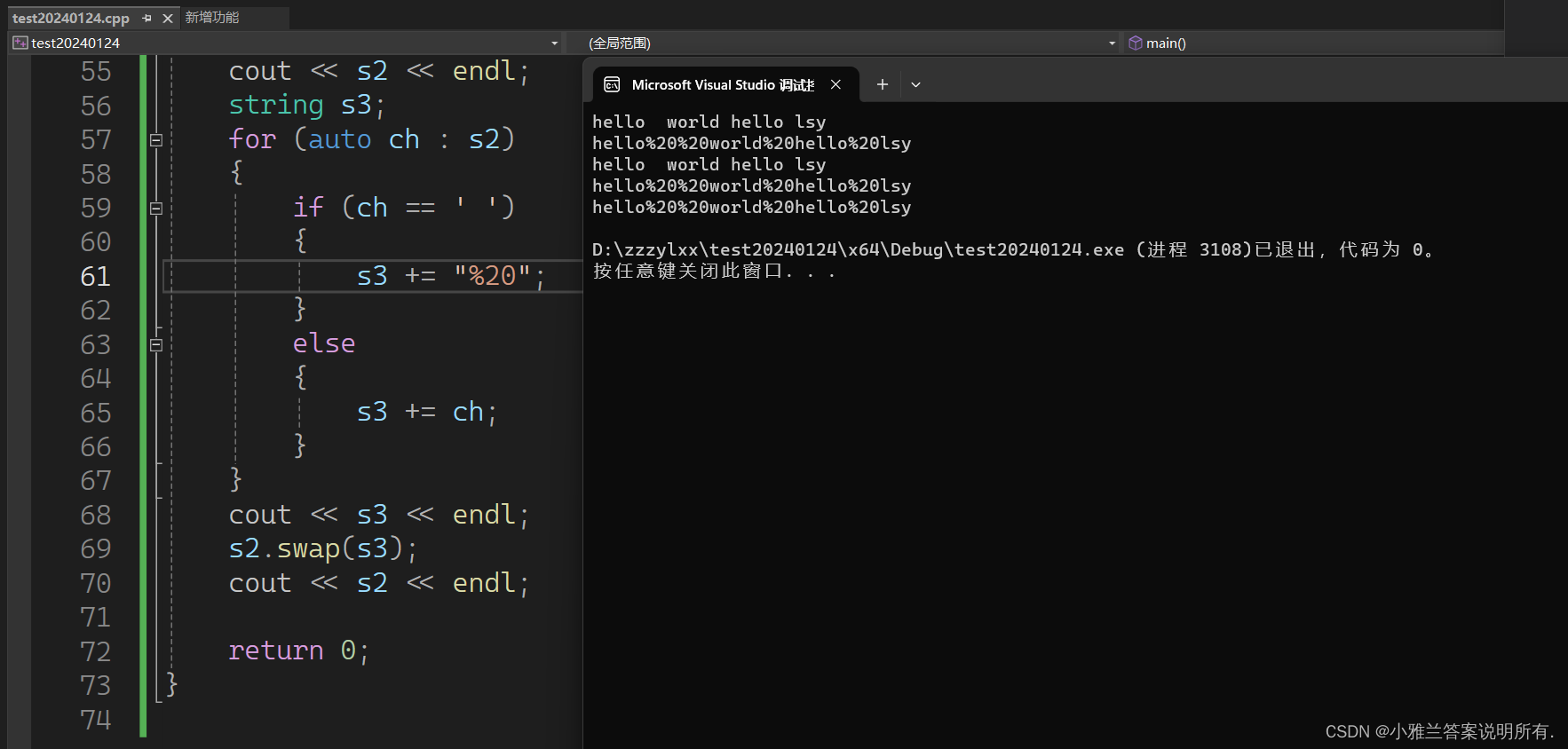
string s2("hello world hello lsy");
cout << s2 << endl;
string s3;
for (auto ch : s2)
{
if (ch == ' ')
{
s3 += "%20";
}
else
{
s3 += ch;
}
}
cout << s3 << endl;
s2.swap(s3);
cout << s2 << endl;
return 0;
}
swap
 不过,swap是不一样的!
不过,swap是不一样的!
第一个swap会产生临时对象,会有拷贝,效率没那么高,第二个swap就是直接交换了指针!
第二种写法的唯一缺陷就是消耗了空间!

pop_back

c_str

#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
using namespace std;int main()
{
string filename("test20240124.cpp");
FILE* fout = fopen(filename.c_str(), "r");
char ch = fgetc(fout);
while (ch != EOF)
{
cout << ch;
ch = fgetc(fout);
}return 0;
}
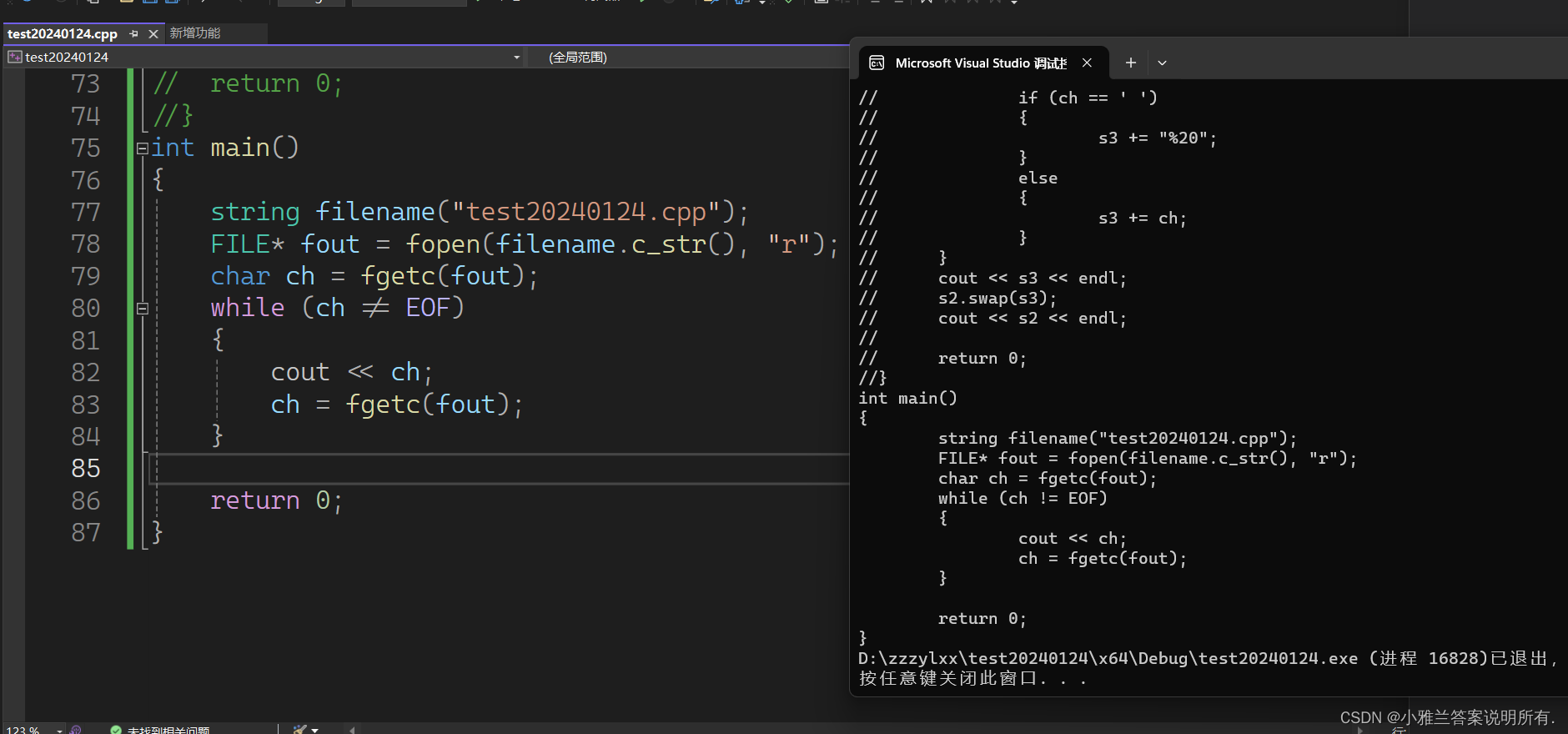 这个接口的主要目的就是兼容C!
这个接口的主要目的就是兼容C!
这个程序就把小雅兰今天在文件中写的代码全部读取到控制台啦!
find+substr

要取一个文件的后缀:
int main()
{
string s1("Test.cpp");
string s2("Test.zip");
size_t pos1 = s1.find('.');
if (pos1 != string::npos)
{
string suff = s1.substr(pos1, s1.size() - pos1);
//string suff = s1.substr(pos1);
cout << suff << endl;
}
size_t pos2 = s2.find('.');
if (pos2 != string::npos)
{
string suff = s2.substr(pos2);
cout << suff << endl;
}
return 0;
}
但是这样写有一点小问题:
int main()
{
string s1("Test.cpp");
string s2("Test.tar.zip");size_t pos1 = s1.find('.');
if (pos1 != string::npos)
{
//string suff = s1.substr(pos1, s1.size() - pos1);
string suff = s1.substr(pos1);
cout << suff << endl;
}size_t pos2 = s2.find('.');
if (pos2 != string::npos)
{
string suff = s2.substr(pos2);
cout << suff << endl;
}
return 0;
}
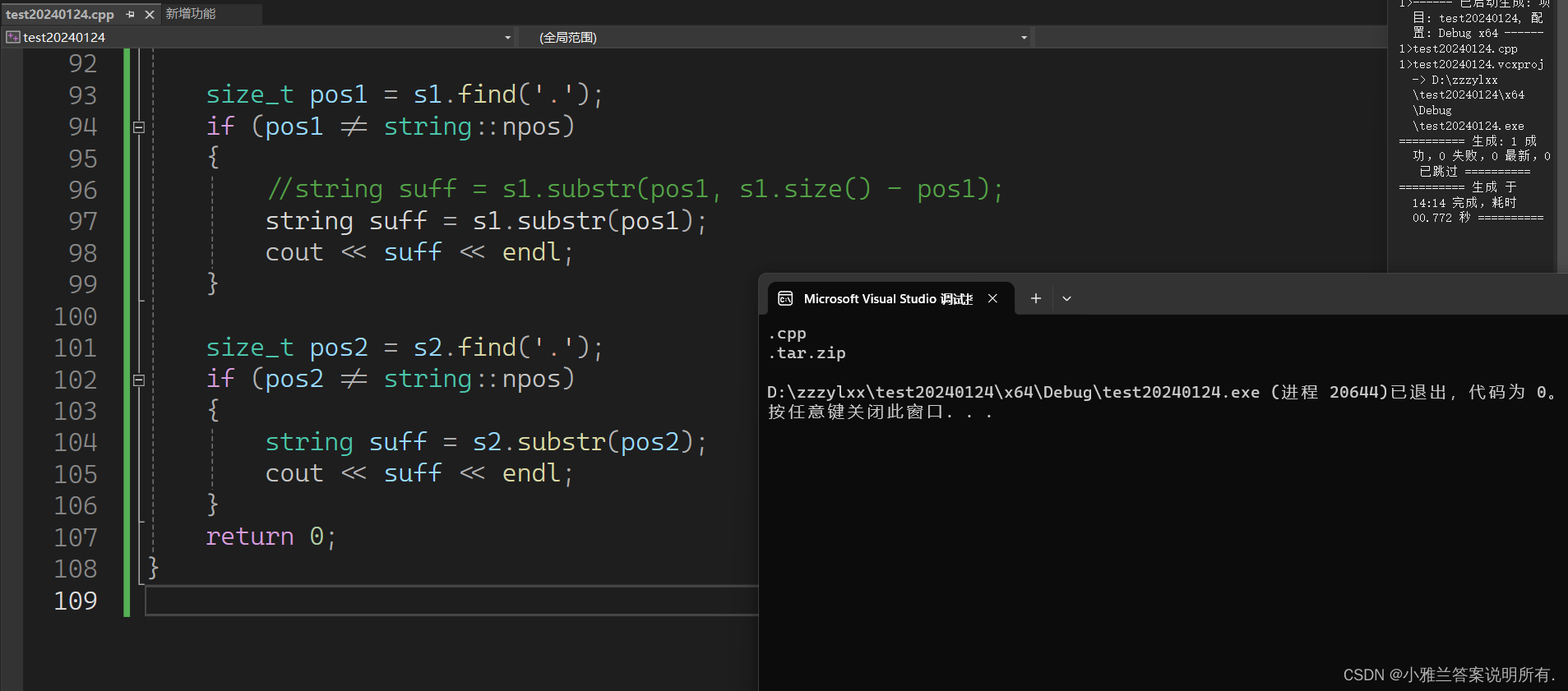 取到的不是真后缀!
取到的不是真后缀!

int main()
{
string s1("Test.cpp");
string s2("Test.tar.zip");
size_t pos1 = s1.rfind('.');
if (pos1 != string::npos)
{
//string suff = s1.substr(pos1, s1.size() - pos1);
string suff = s1.substr(pos1);
cout << suff << endl;
}
size_t pos2 = s2.rfind('.');
if (pos2 != string::npos)
{
string suff = s2.substr(pos2);
cout << suff << endl;
}
return 0;
}
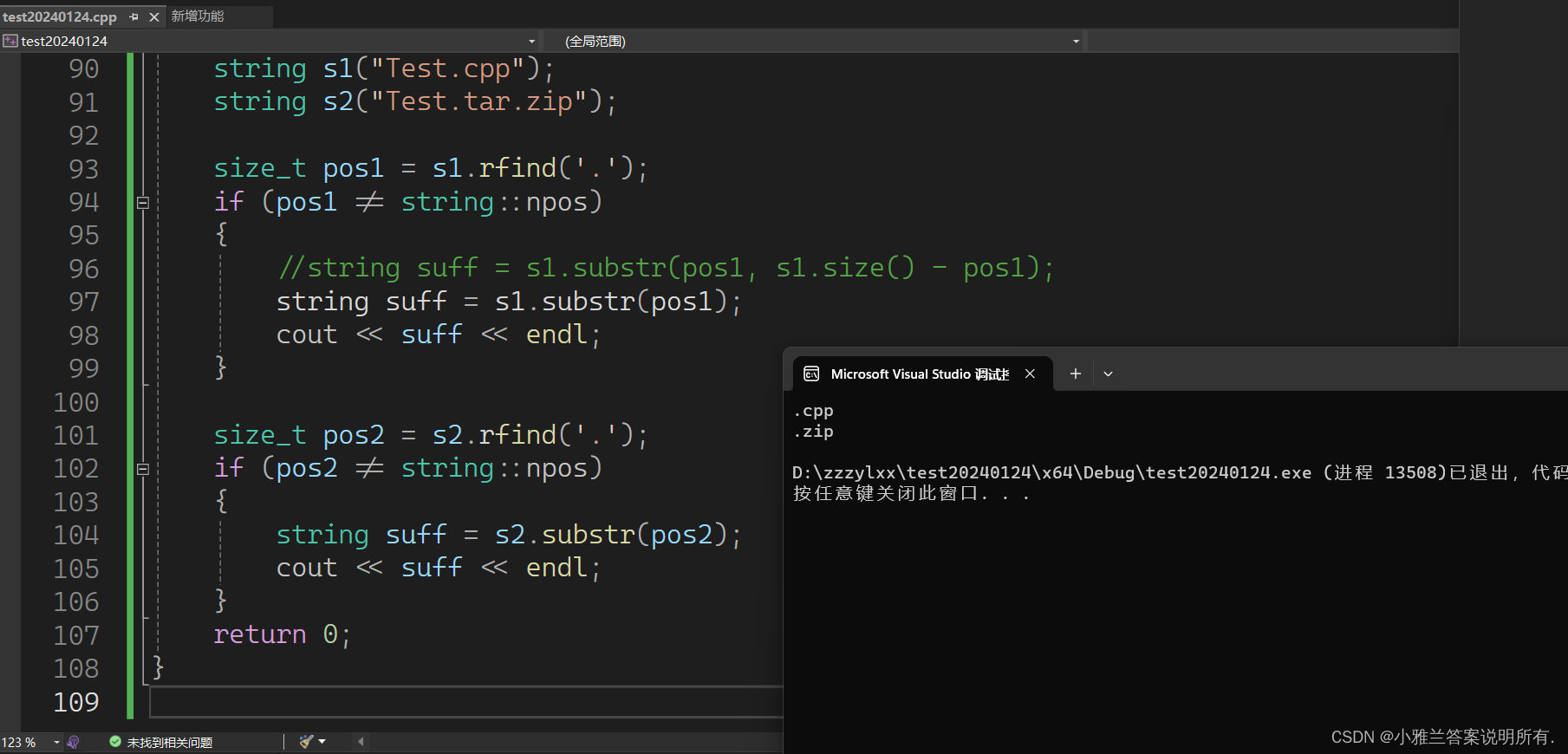
这样才是取到的正确的后缀!
接下来,来看一个更为复杂的场景:
给定一个网址,把它的三个部分分离!
string str("https://legacy.cplusplus.com/reference/string/string/substr/");
string sub1, sub2, sub3;
pos1 = str.find(':');
sub1 = str.substr(0, pos1 - 0);
cout << sub1 << endl;
pos2 = str.find('/', pos1 + 3);
sub2 = str.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << sub2 << endl;
sub3 = str.substr(pos2 + 1);
cout << sub3 << endl;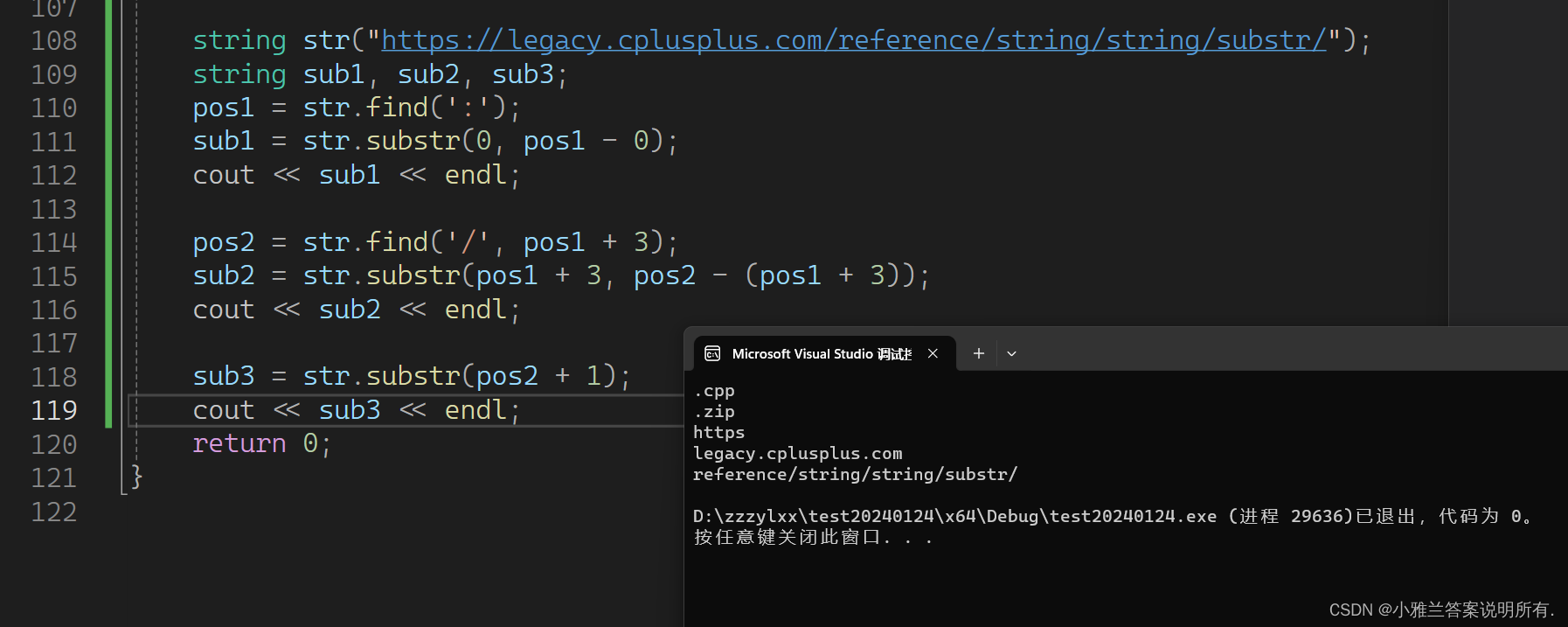
find_first_of
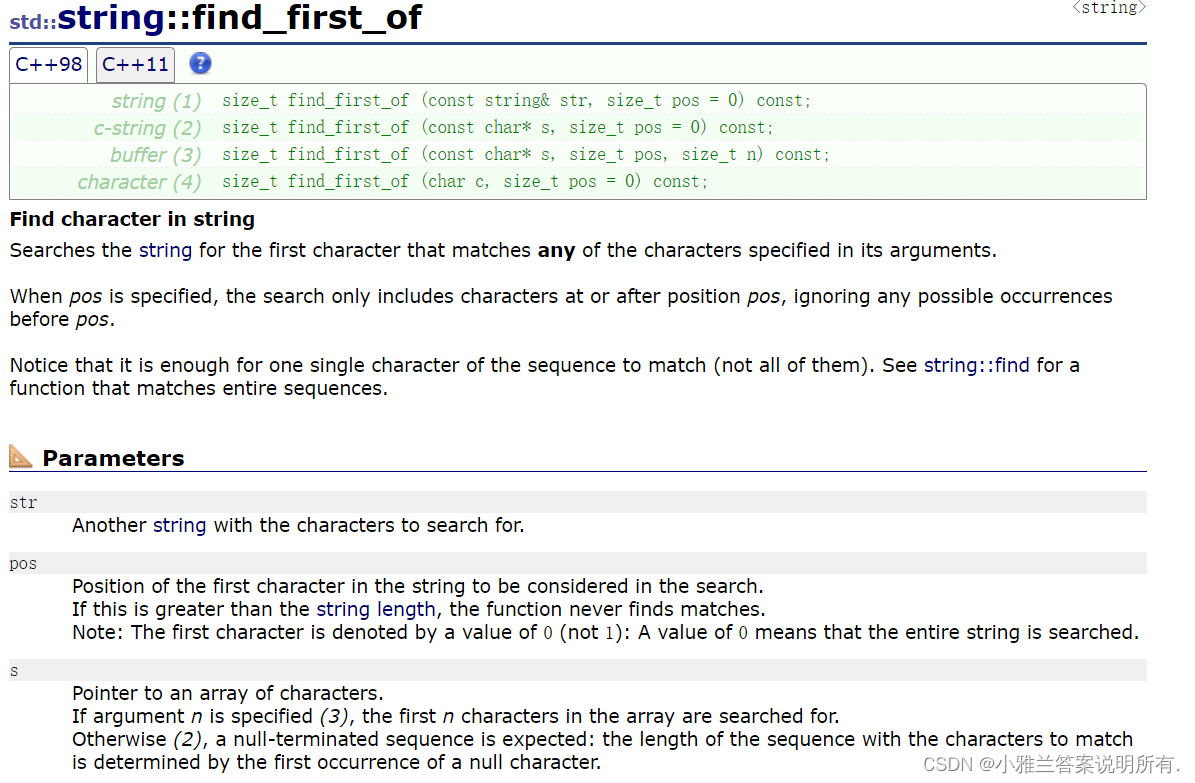
#include<iostream>
#include<string>
using namespace std;int main()
{
std::string str("Please, replace the vowels in this sentence by asterisks.");
std::size_t found = str.find_first_of("aeiou");
while (found != std::string::npos)
{
str[found] = '*';
found = str.find_first_of("aeiou", found + 1);
}std::cout << str << '\n';
return 0;
}
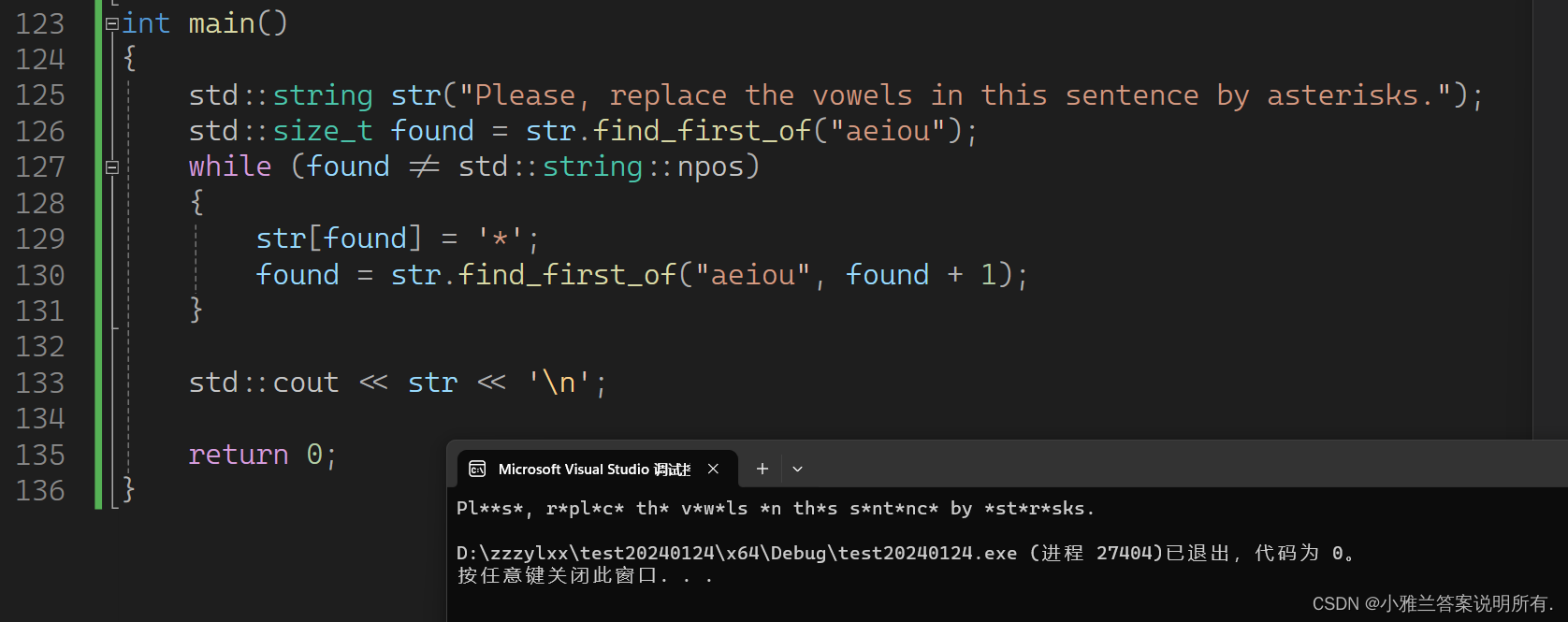
find_last_of
#include<iostream>
#include<string>
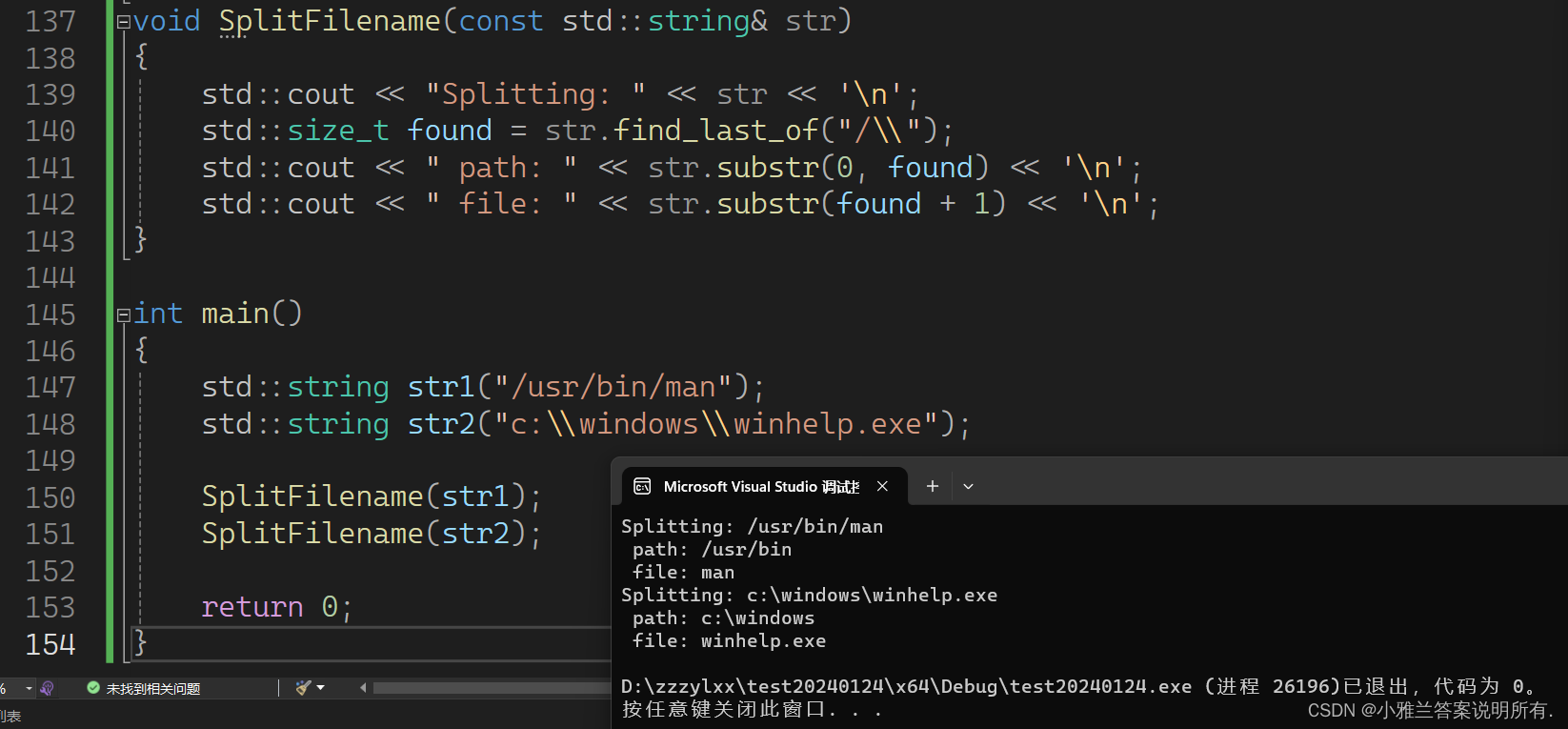
using namespace std;void SplitFilename(const std::string& str)
{
std::cout << "Splitting: " << str << '\n';
std::size_t found = str.find_last_of("/\\");
std::cout << " path: " << str.substr(0, found) << '\n';
std::cout << " file: " << str.substr(found + 1) << '\n';
}int main()
{
std::string str1("/usr/bin/man");
std::string str2("c:\\windows\\winhelp.exe");SplitFilename(str1);
SplitFilename(str2);return 0;
}
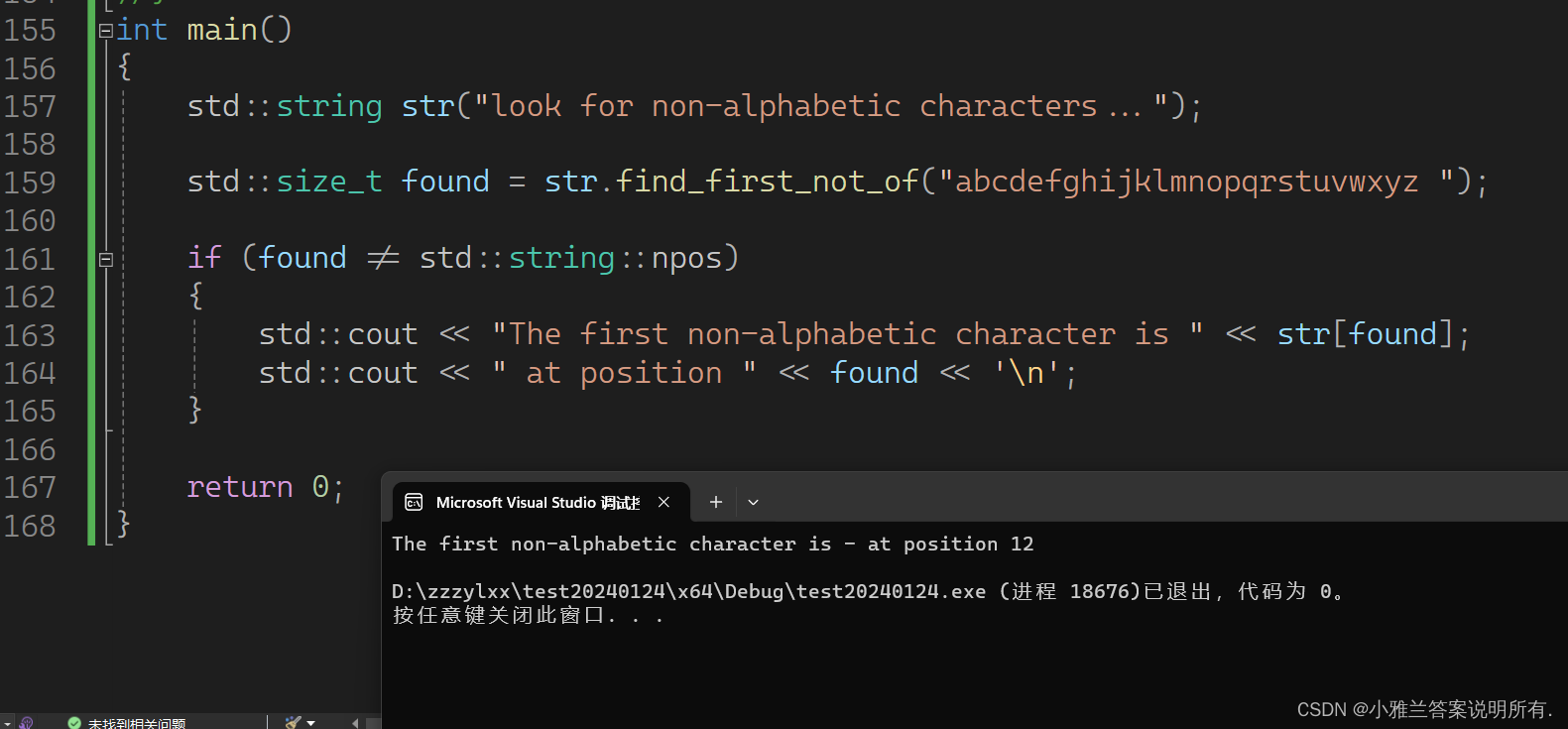
find_first_not_of
#include<iostream>
#include<string>
using namespace std;int main()
{
std::string str("look for non-alphabetic characters...");std::size_t found = str.find_first_not_of("abcdefghijklmnopqrstuvwxyz ");
if (found != std::string::npos)
{
std::cout << "The first non-alphabetic character is " << str[found];
std::cout << " at position " << found << '\n';
}return 0;
}
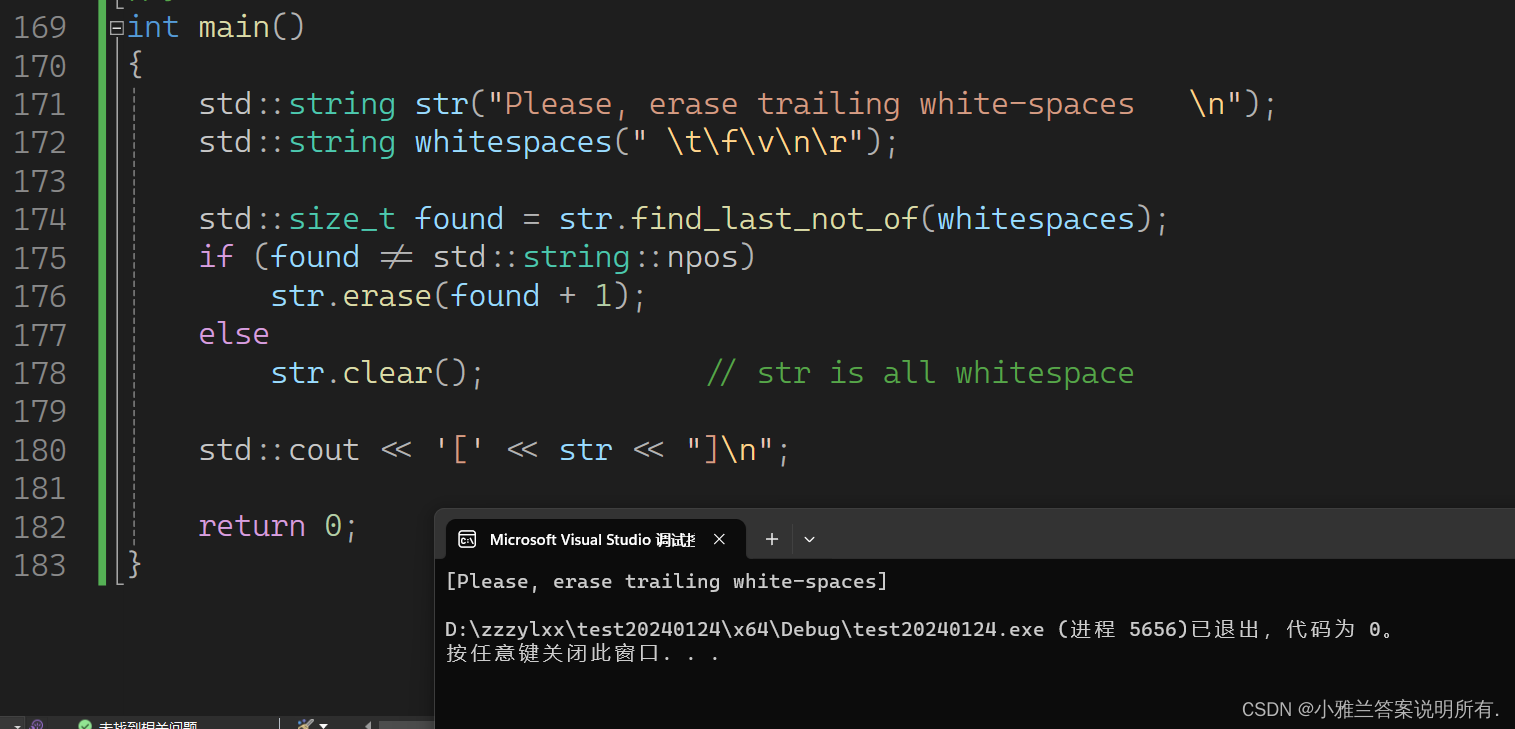
find_last_not_of
#include<iostream>
#include<string>
using namespace std;int main()
{
std::string str("Please, erase trailing white-spaces \n");
std::string whitespaces(" \t\f\v\n\r");std::size_t found = str.find_last_not_of(whitespaces);
if (found != std::string::npos)
str.erase(found + 1);
else
str.clear(); // str is all whitespacestd::cout << '[' << str << "]\n";
return 0;
}
+
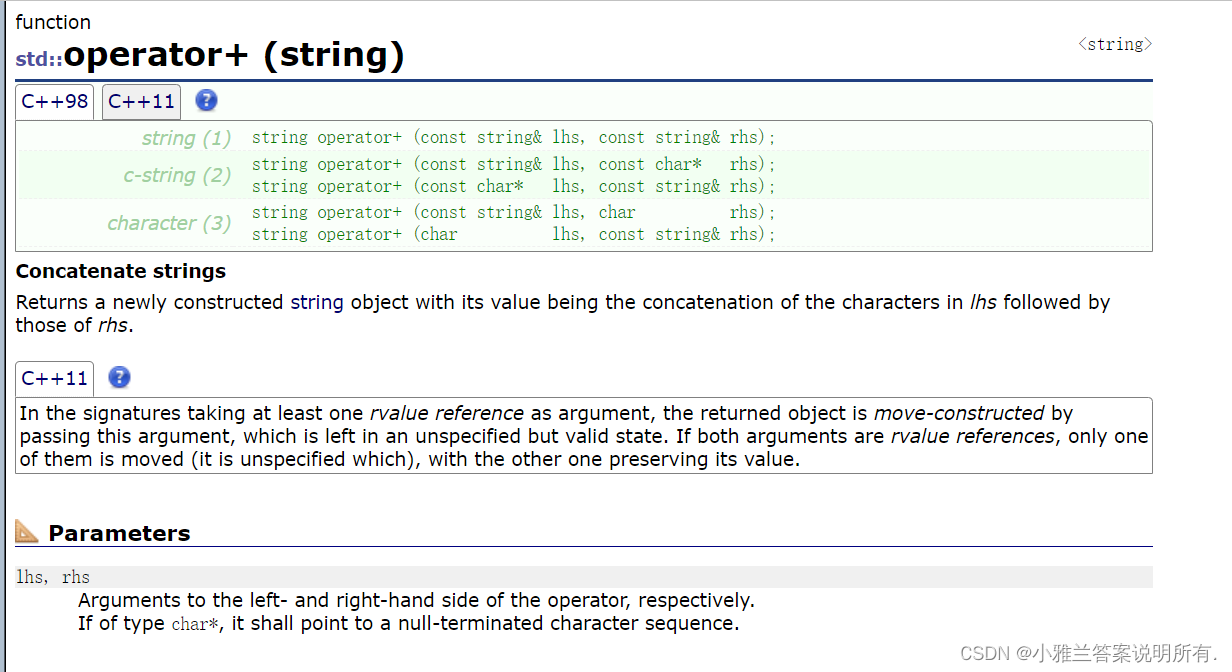
int main()
{
string s1(" hello ");
string s2("world");
string ret1 = s1 + s2;
cout << ret1 << endl;
string ret2 = s1 + "xx";
cout << ret2 << endl;
string ret3 = "xx" + s1;
cout << ret3 << endl;
return 0;
}
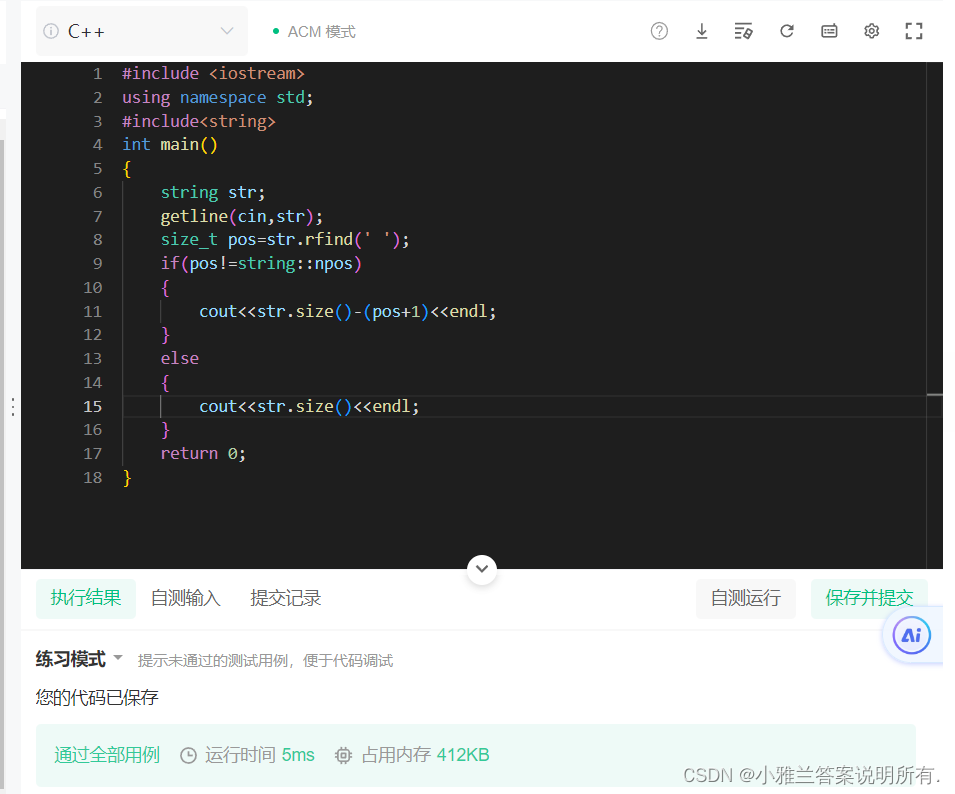
字符串最后一个单词的长度
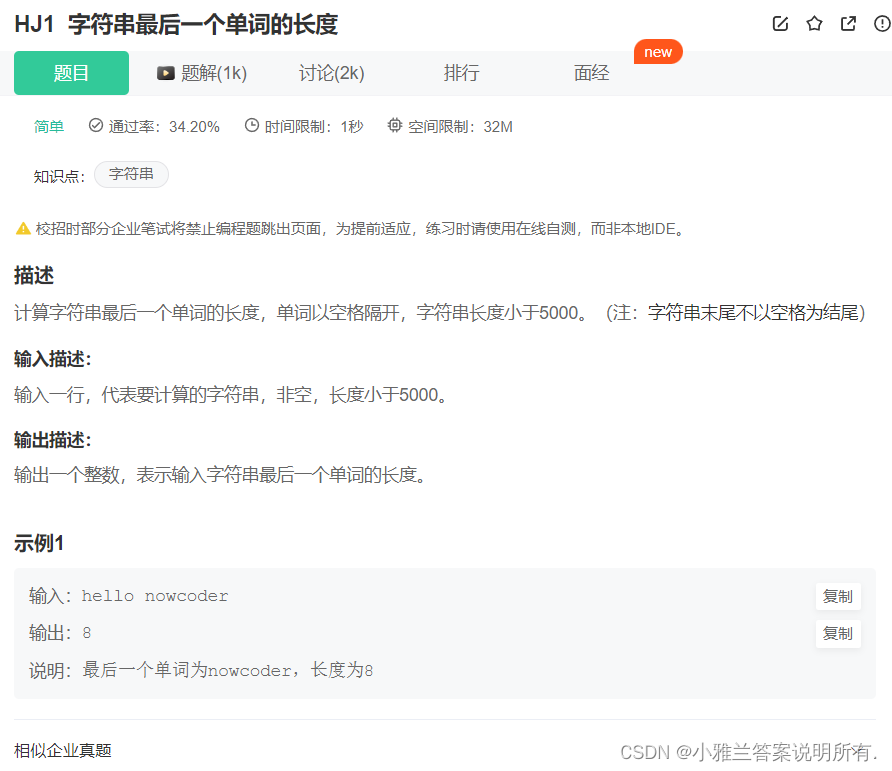
但是这个题目有一个坑,就是:不管是scanf还是cin,默认是用空格或者换行去分割!
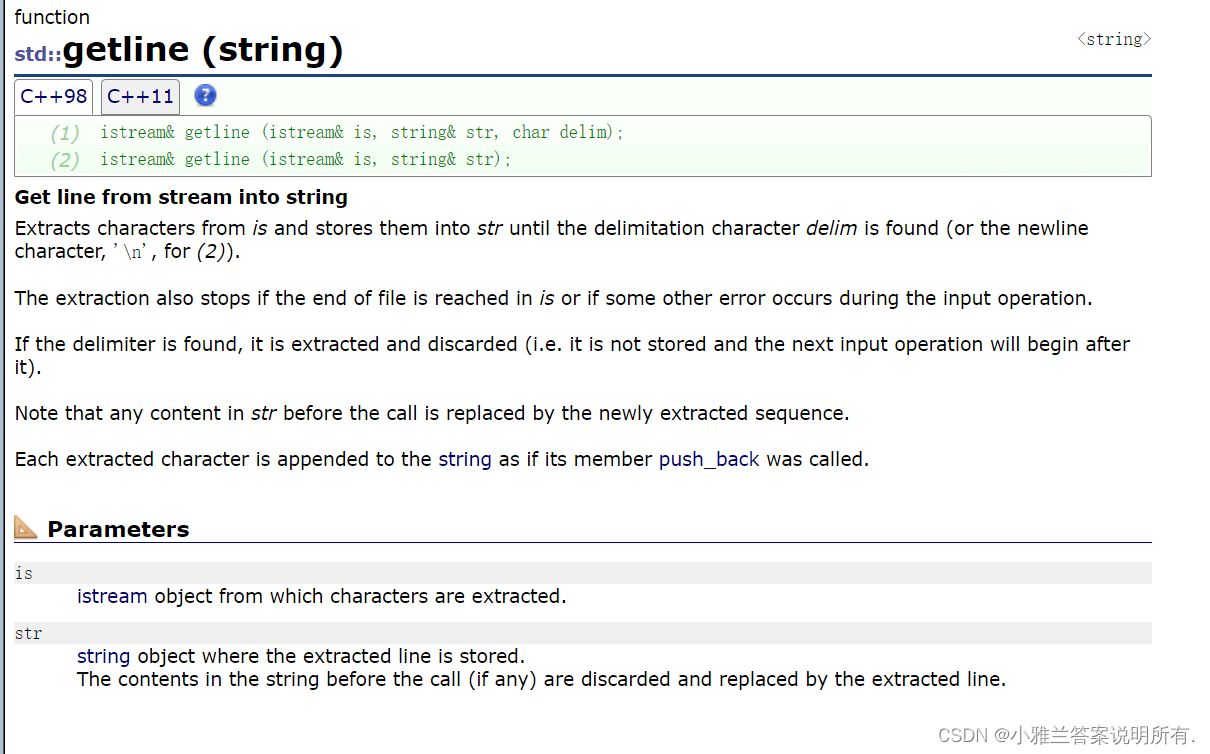
#include <iostream>
using namespace std;
#include<string>
int main()
{
string str;
getline(cin,str);
size_t pos=str.rfind(' ');
if(pos!=string::npos)
{
cout<<str.size()-(pos+1)<<endl;
}
else
{
cout<<str.size()<<endl;
}
return 0;
}
好啦,string的使用的部分到这里就结束啦,之前的文章:
https://xiaoyalan.blog.csdn.net/article/details/135110694?spm=1001.2014.3001.5502
https://xiaoyalan.blog.csdn.net/article/details/135133181?spm=1001.2014.3001.5502
还要继续加油!!!