-
-
google football 实验记录
1. gru模型和dense模型对比实验
-
实验场景:5v5(控制蓝方一名激活球员),跳4帧,即每个动作执行4次
-
实验点:
-
修复dense奖励后智能体训练效果能否符合预期
-
-
实验目的:
-
对比gru 长度为16 和 dense net作为aggrator的区别
-
-
实验效果
-
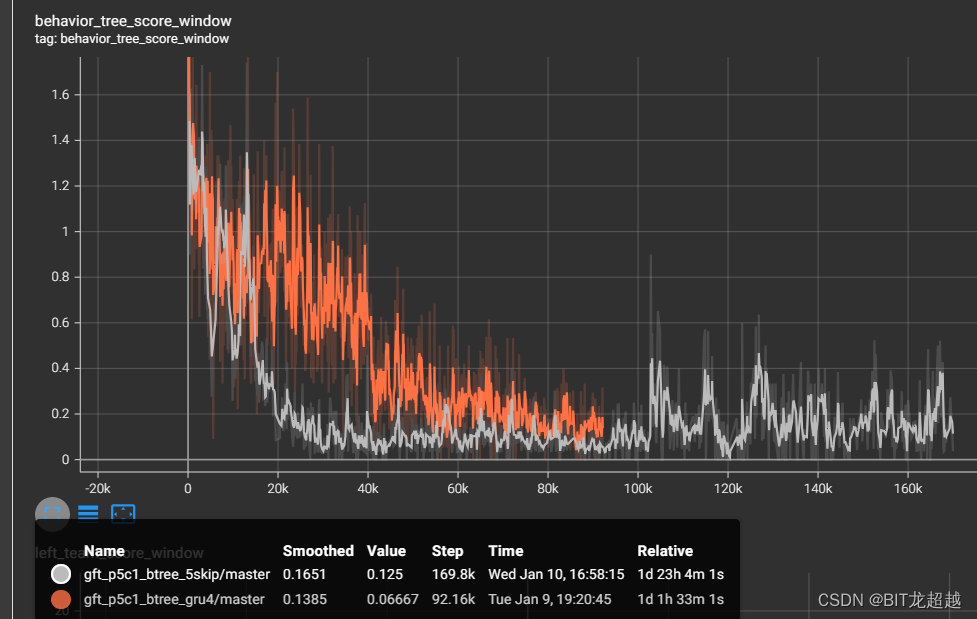
reward
-

-
敌方得分
-
-
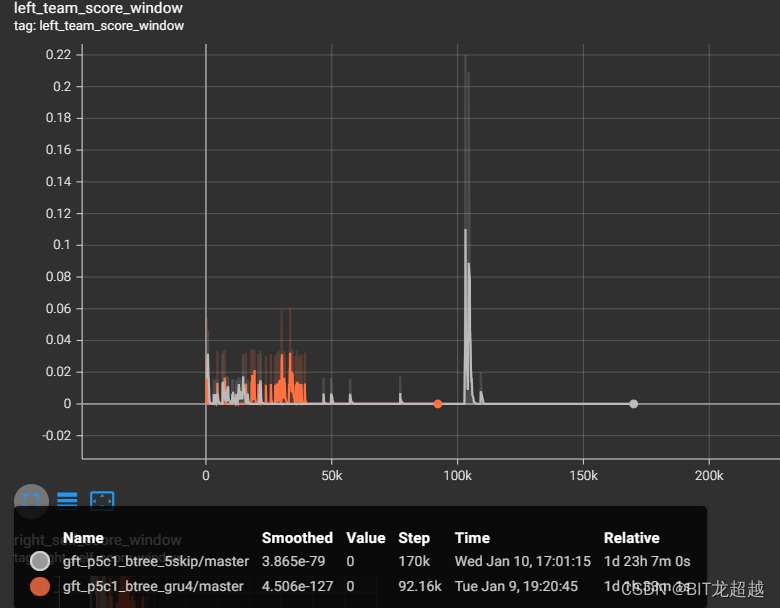
我方得分
-
-
熵
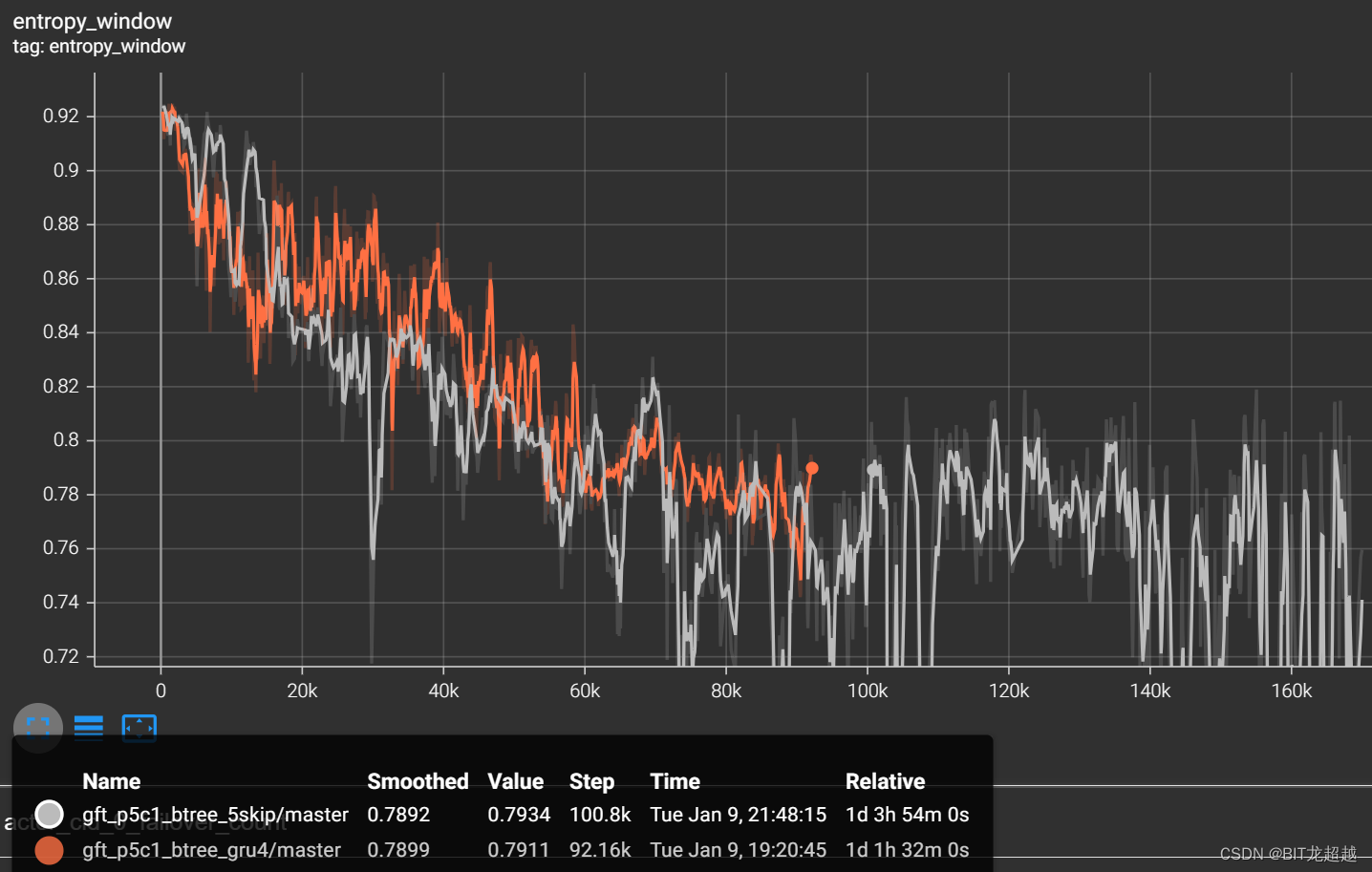
-
-
实验结论:
-
相较于长度16的gru,dense net 作 聚合器有益于快速收敛。
-
gru聚合器学到了持球奖励,所以在双方奖励初步收敛后,gru能凭借持球奖励再一步将总奖励提到0以上(另一方面说明持球奖励设置太大了)
-
两种方法都很难学会进球,进球的次数太少。
-
-
2 课程学习
2.1 禁区内
-
实验场景:5v5(控制蓝方四名非守门员成员),跳4帧,在简单课程:禁区射门,开始
-
实验目的:
-
测试简单课程能否教会智能体智能体在禁区中射门
-
-
实验效果
-
奖励

-
我方得分:

-
敌方得分:
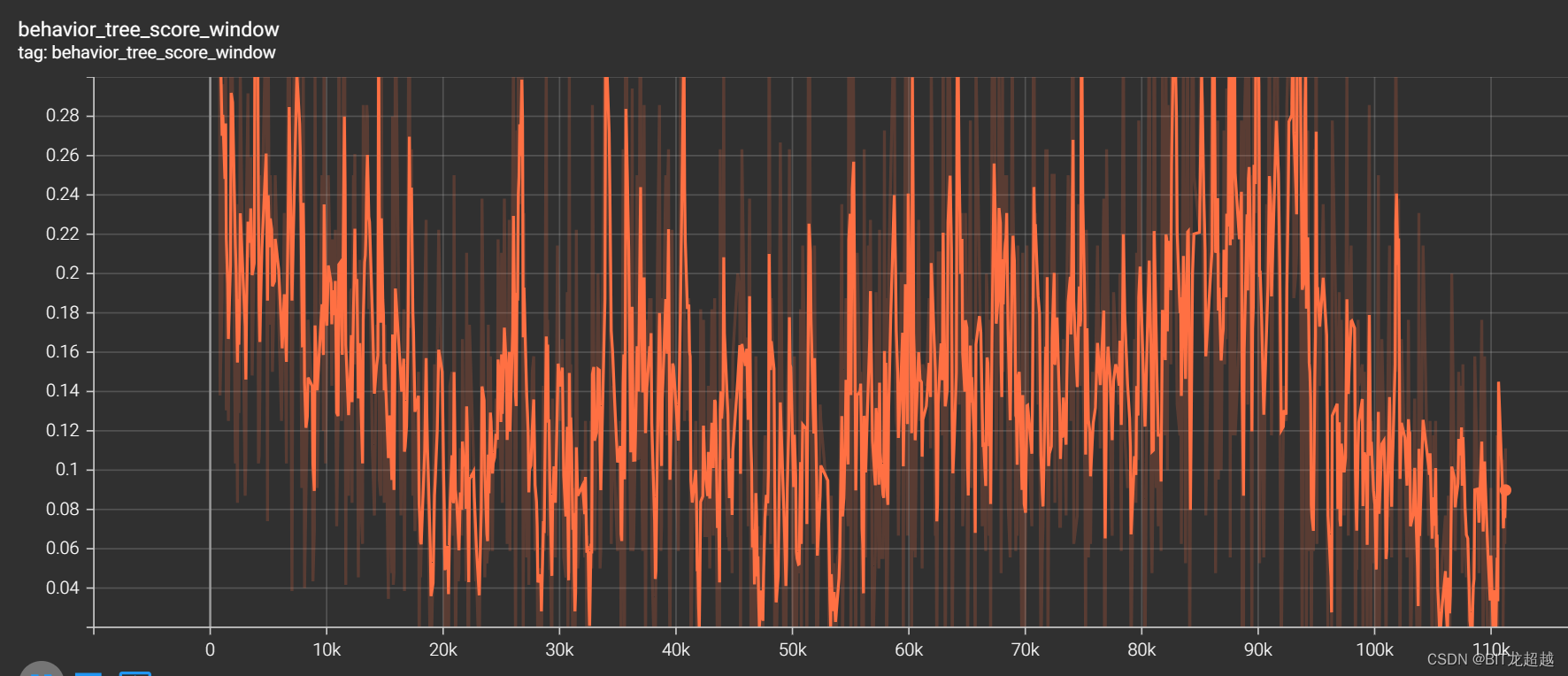
-
熵
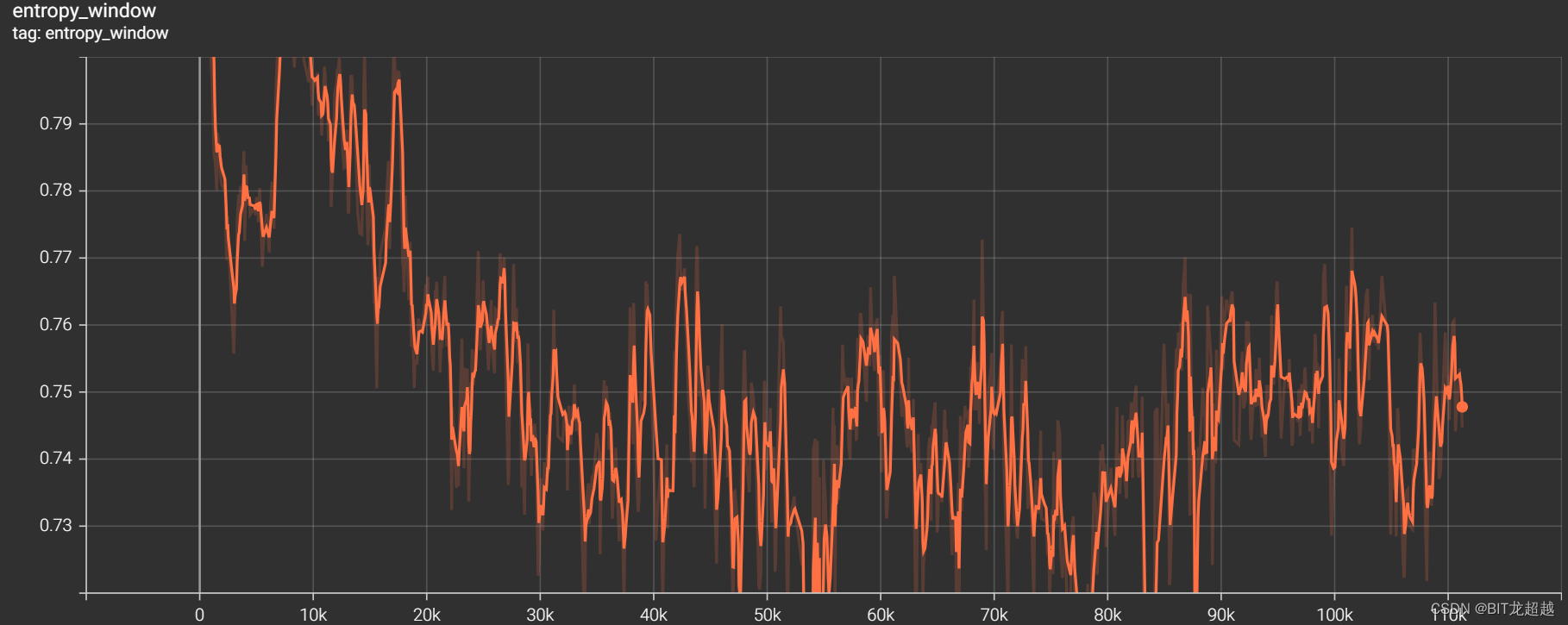
-
实验结论
-
课程学习中,将我方球员和足球放置于禁区内,有助于智能体学会在禁区内射门动作
-
只进行这一种课程学习无法教会智能体从后场带球突破前场然后射门的策略,所以进球数始终无限接近于一(禁区内射门)而无法超过一
-
2.2前场禁区外-对战简单规则
-
实验场景:5v5(控制蓝方四名非守门员成员),跳4帧,在进阶课程:我方全部球员处于敌方禁区外的前场,敌方所有球员处于我方的后场,足球位于我方球员附近。敌方体力0.05,我方体力1.00
-
实验配置:加载经过简单禁区内射门课程学习智能体的模型
-
实验目的:试验进阶课程能否教会智能体从后场带球突破至前场禁区然后射门的策略
-
实验效果:
-
奖励:
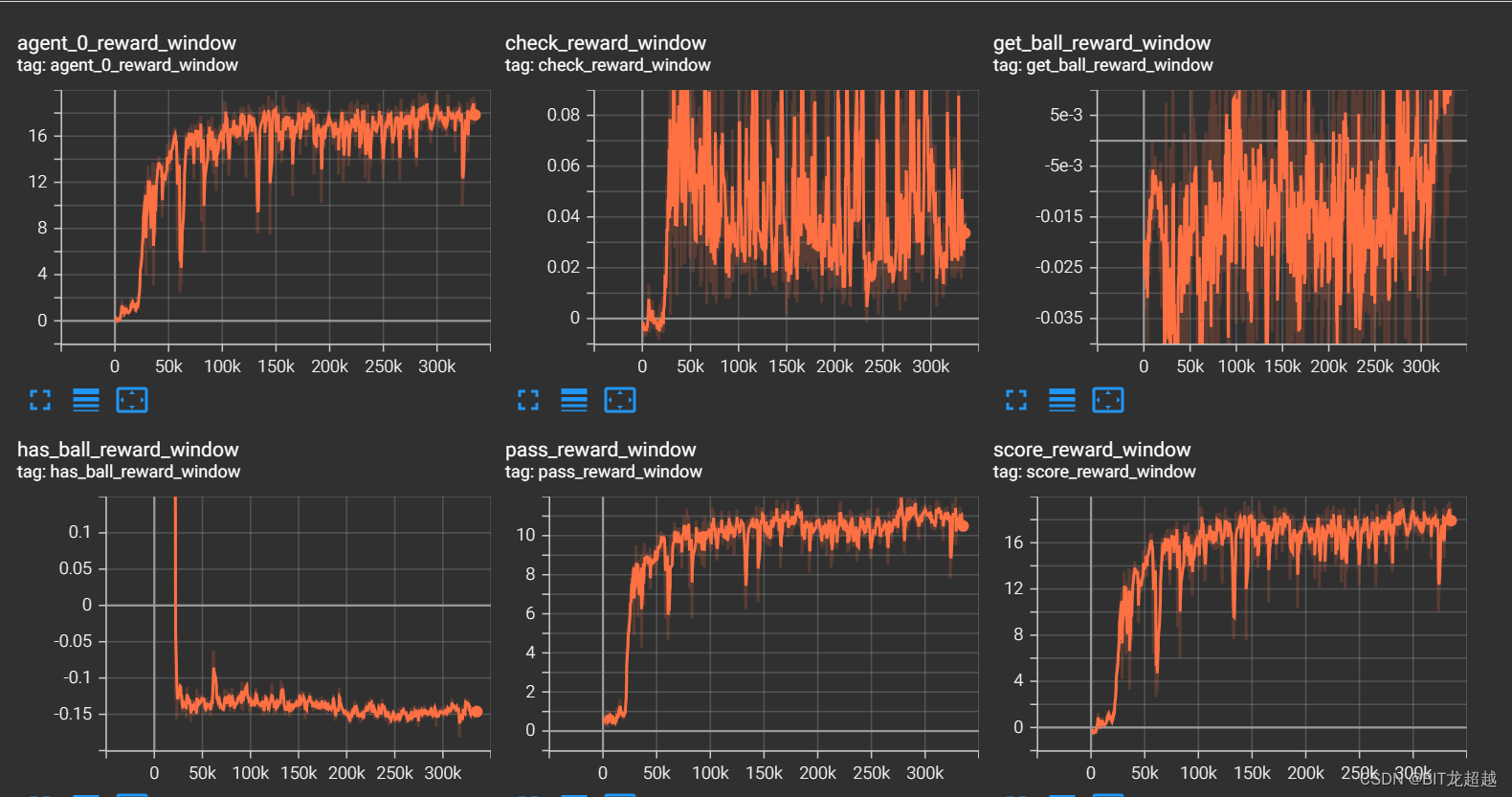
-
得分

-
胜率

-
熵
-
-
实验结论
-
进阶课程学习中,将我方球员和足球放置于前场,有助于智能体学会突破防守,进入禁区,然后射门,在敌方体力0.05,我方体力1.00的设置下每场净进球最高为8,胜率接近1
-
进阶课程中,由于我方全部处于越位位置,传球会导致越位,使得训练后智能体在突破过程中倾向于单刀直入,很少有传球动作。并且进攻路线比较单一,总是从中路的一条直线突破。在敌方持球阶段,防御能力很弱。
-
-
-
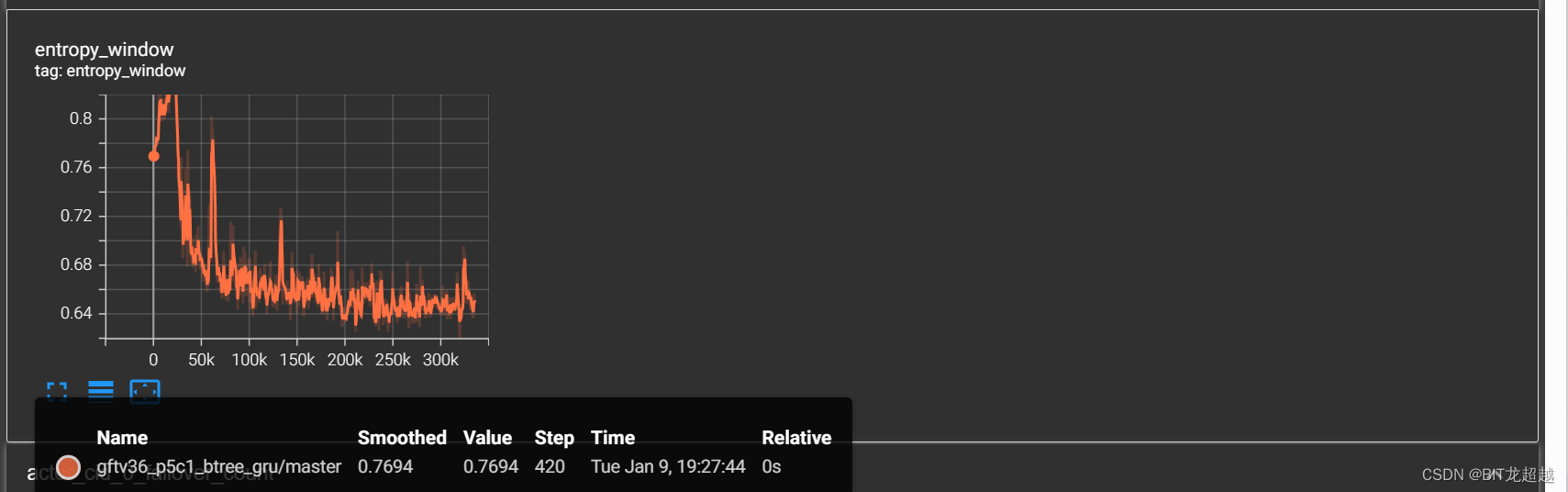
2.3前场禁区外-对战困难规则
-
实验场景:5v5(控制蓝方四名非守门员成员),跳4帧,在进阶课程3.7中:敌我双方球员均处于各自半场,我方球员更接近球场中心,足球位于球场中心。敌方体力1.00,我方体力1.00;在进阶课程4.8中:敌我双方球员均处于对称位置,足球位于球场中心。敌方体力1.00,我方体力0.11
-
实验配置:加载经过简单禁区内射门课程学习智能体的模型
-
实验目的:试验进阶课程能否教会智能体从后场带球突破至前场禁区然后射门的策略
-
实验效果:
-
奖励:

-
得分
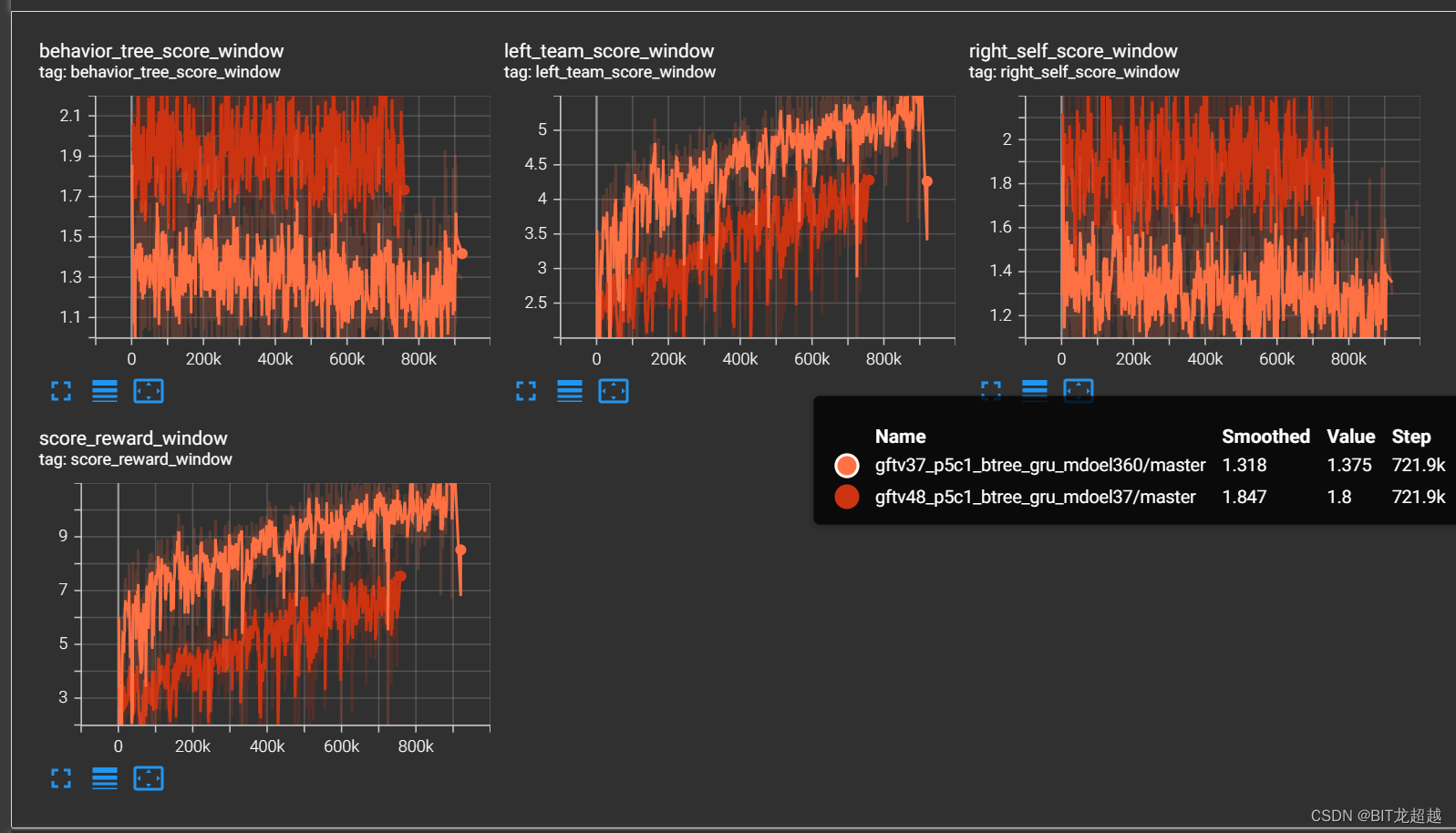
-
熵
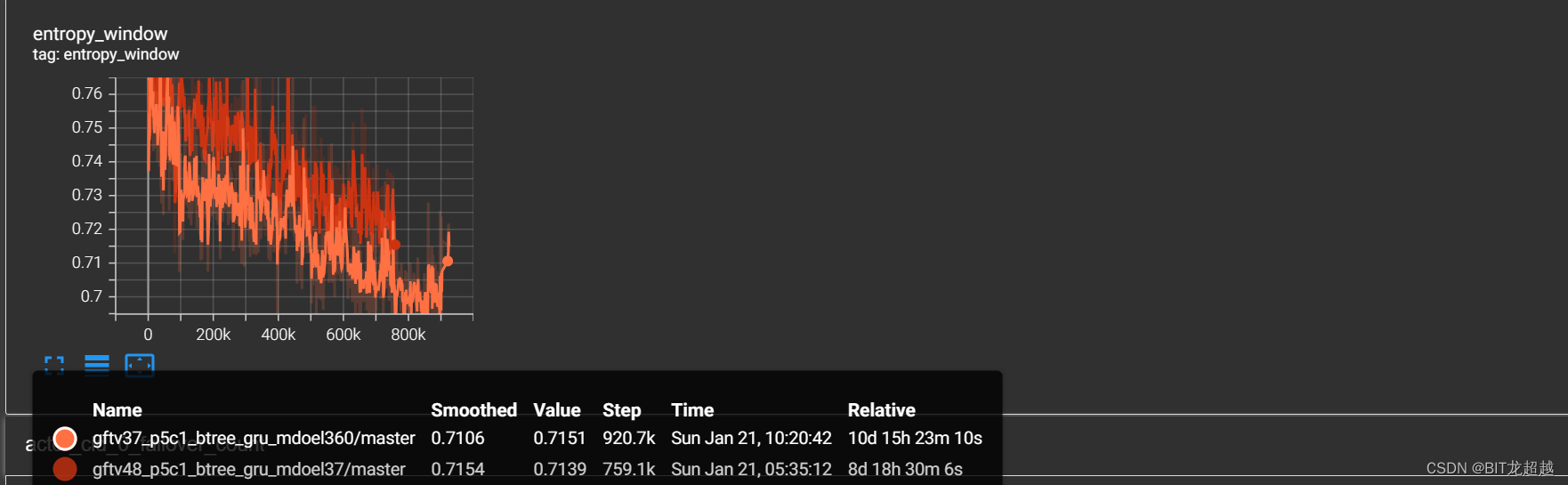
-
胜率
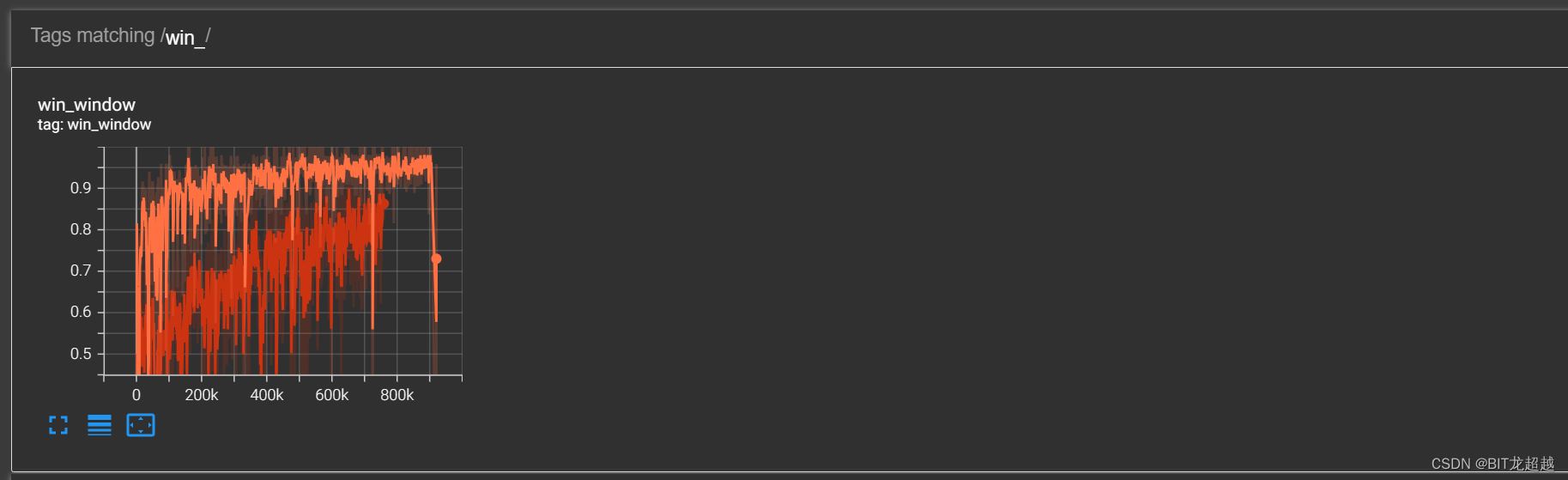
-
-
实验结论
-
通过进阶课程37-48,可以使智能体在较公平和较劣势情况下学习到战胜规则智能体的策略。
-
由于课程的设置,智能体很少有传球动作。并且进攻路线比较单一,总是从中路的一条直线突破。在敌方持球阶段,防御能力很弱。
-
Naive Selfplay
单一模型,纯selfplay
-
实验场景:5v5(控制蓝方四名非守门员成员),跳4帧,左右双方均为强化学习智能体,采用同一模型、右边队伍以0.01的概率为 规则智能体,
-
实验配置:加载经过进阶课程学习36智能体的模型
-
实验目的:测试selfplay训练方法对模型攻防性能的影响
-
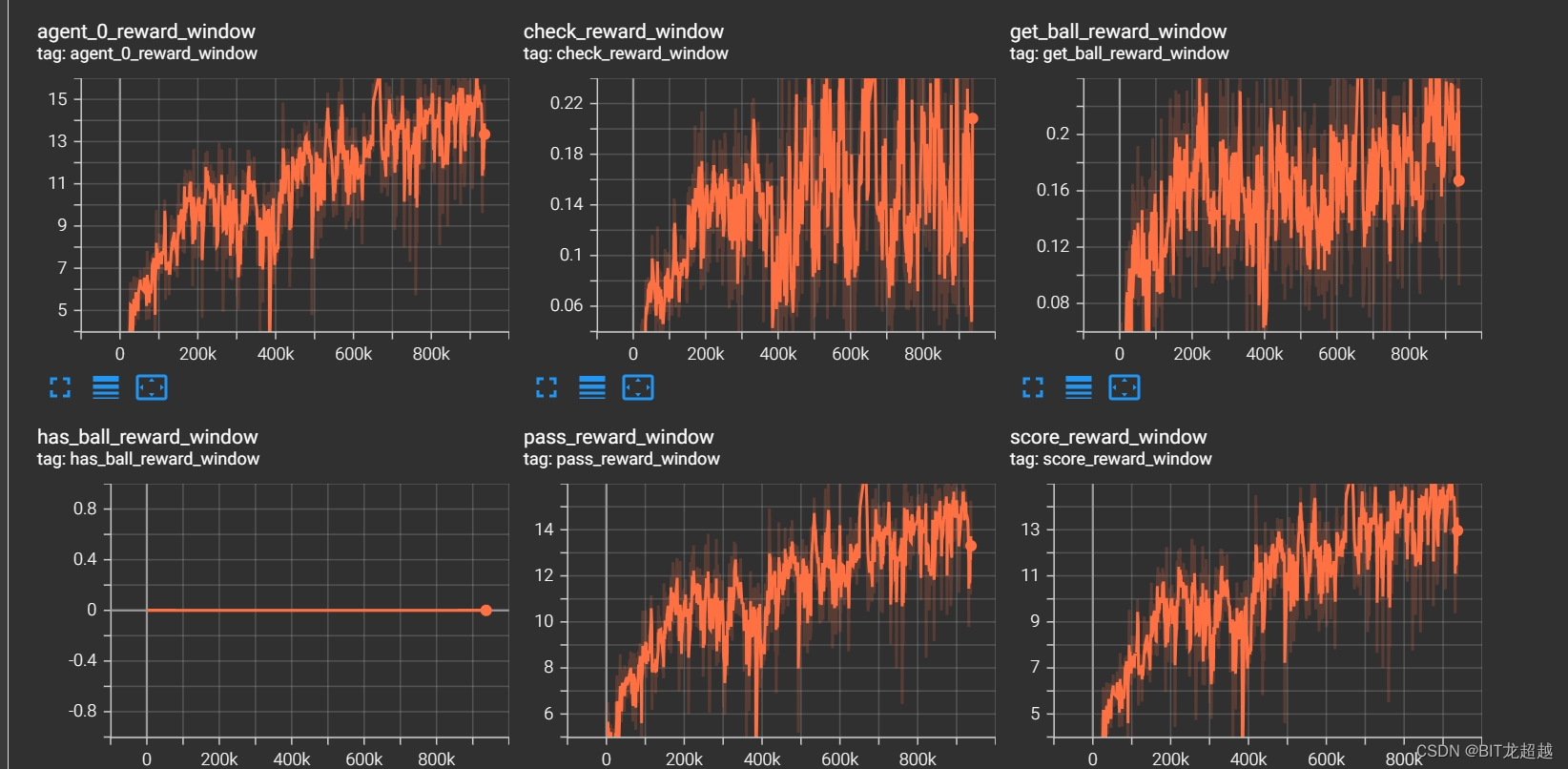
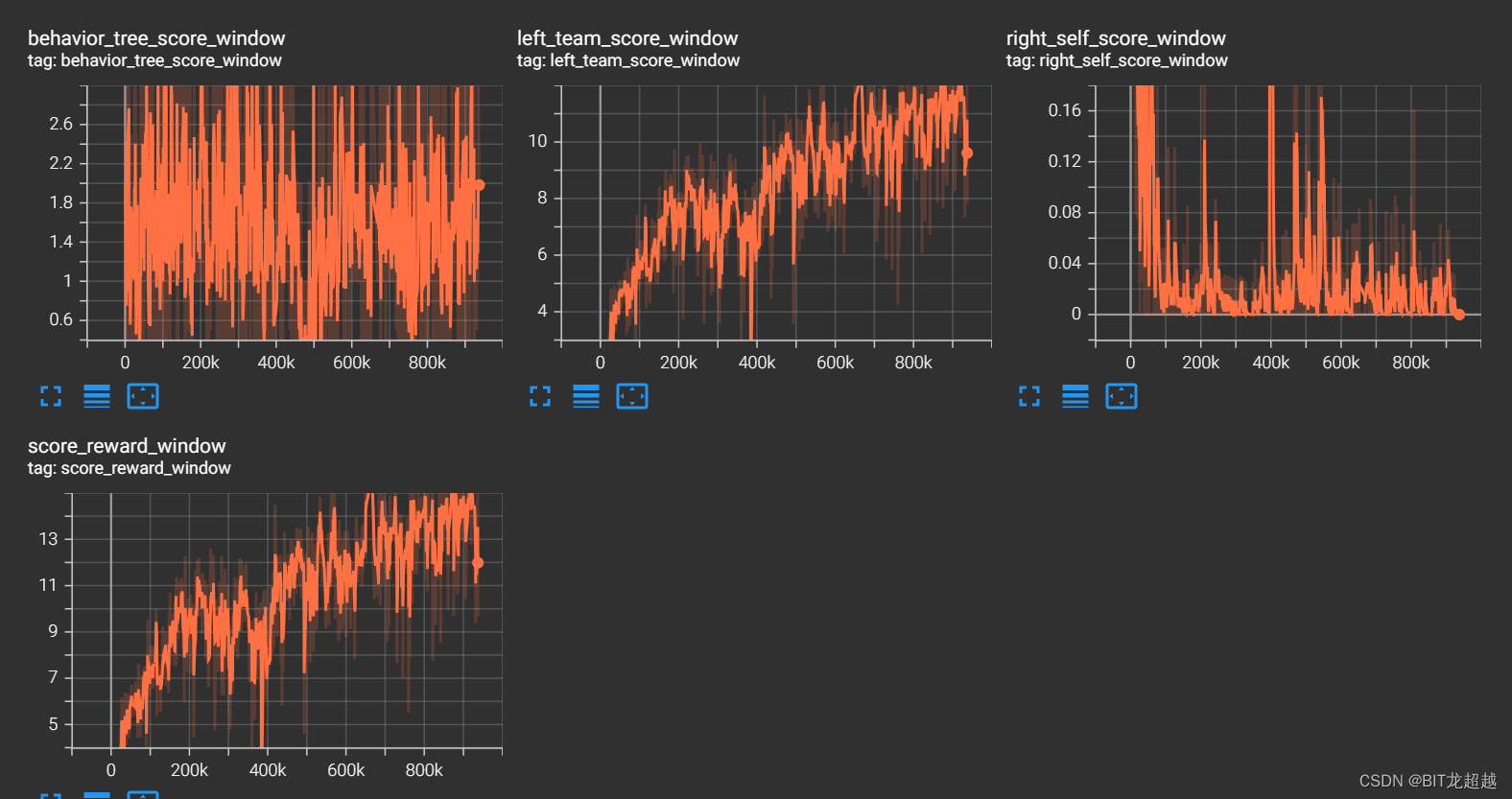
实验效果:
-
奖励:
-
得分:
-
熵

-
胜率

-
-
实验结论
-
根据对战视频,selfplay可以增加智能体进攻策略的多样性,智能体不会拘泥一种策略,而是从多个方向向禁区突破,并且具有较低水平的防守能力,偶尔会截断传球,成功铲球等
-
selfplay 后的智能体对战规则的胜率降低,不能像在课程学习中那样,降低规则的进球数,说明其对自身模型产生较大的过拟合,参考文献 Bansal, Trapit et al. “Emergent Complexity via Multi-Agent Competition.” ArXiv abs/1710.03748 (2017): n. pag. 中也有指出naive selfplay的这种过拟合现象,文章通过抽取不同时期的model缓解这种现象。
-
单一模型,selfplay和规则混合训练
-
实验场景:5v5(控制蓝方四名非守门员成员),跳4帧,左右双方均为强化学习智能体,采用同一模型、右边队伍分别以0.5、 0.75 的概率为 规则智能体,
-
实验配置:加载经过进阶课程学习36智能体的模型
-
实验目的:测试selfplay和规则混合训练方法对模型攻防性能的影响,观察不同占比的规则对手,对智能体训练会产生什么影响
-
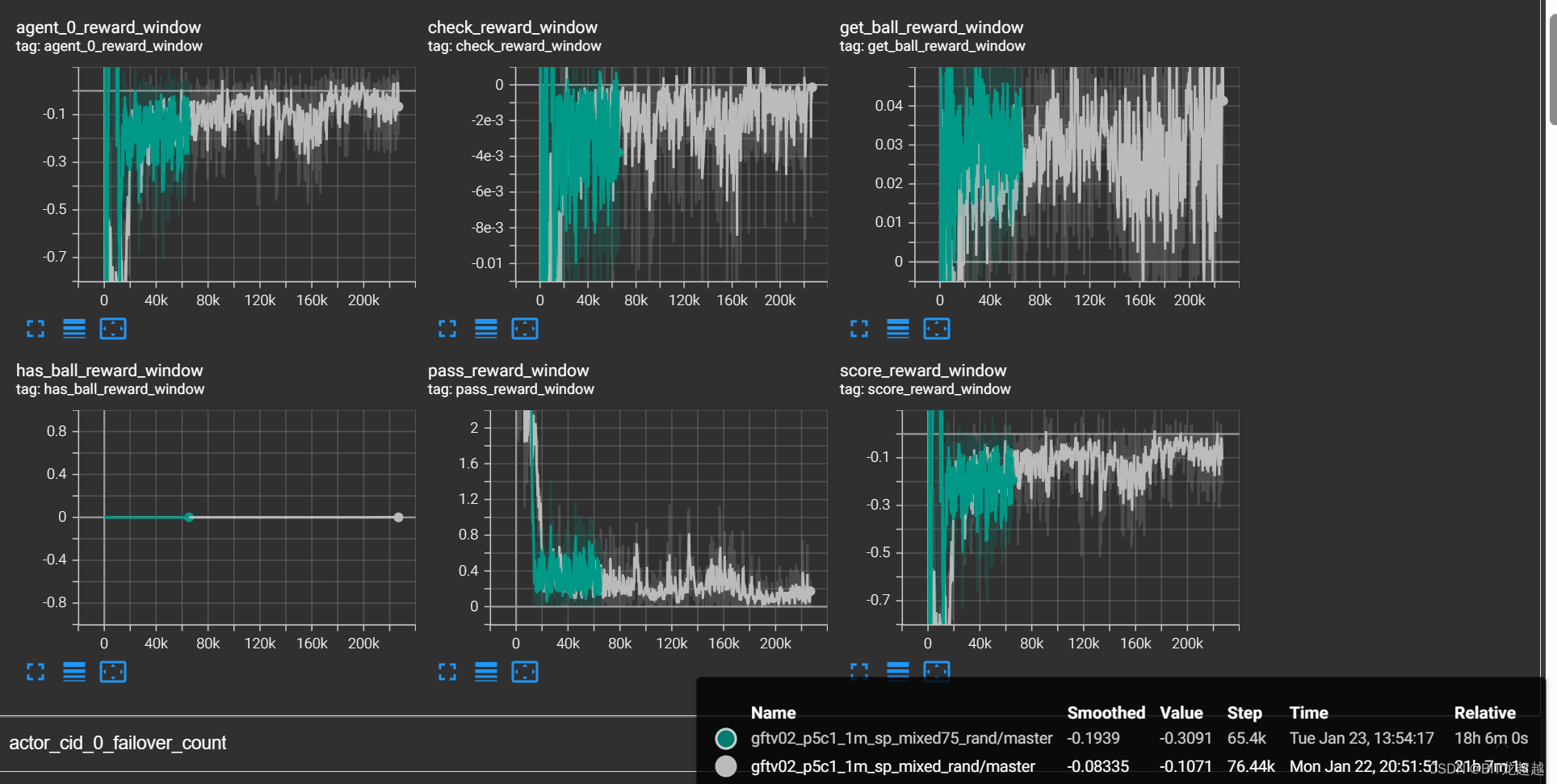
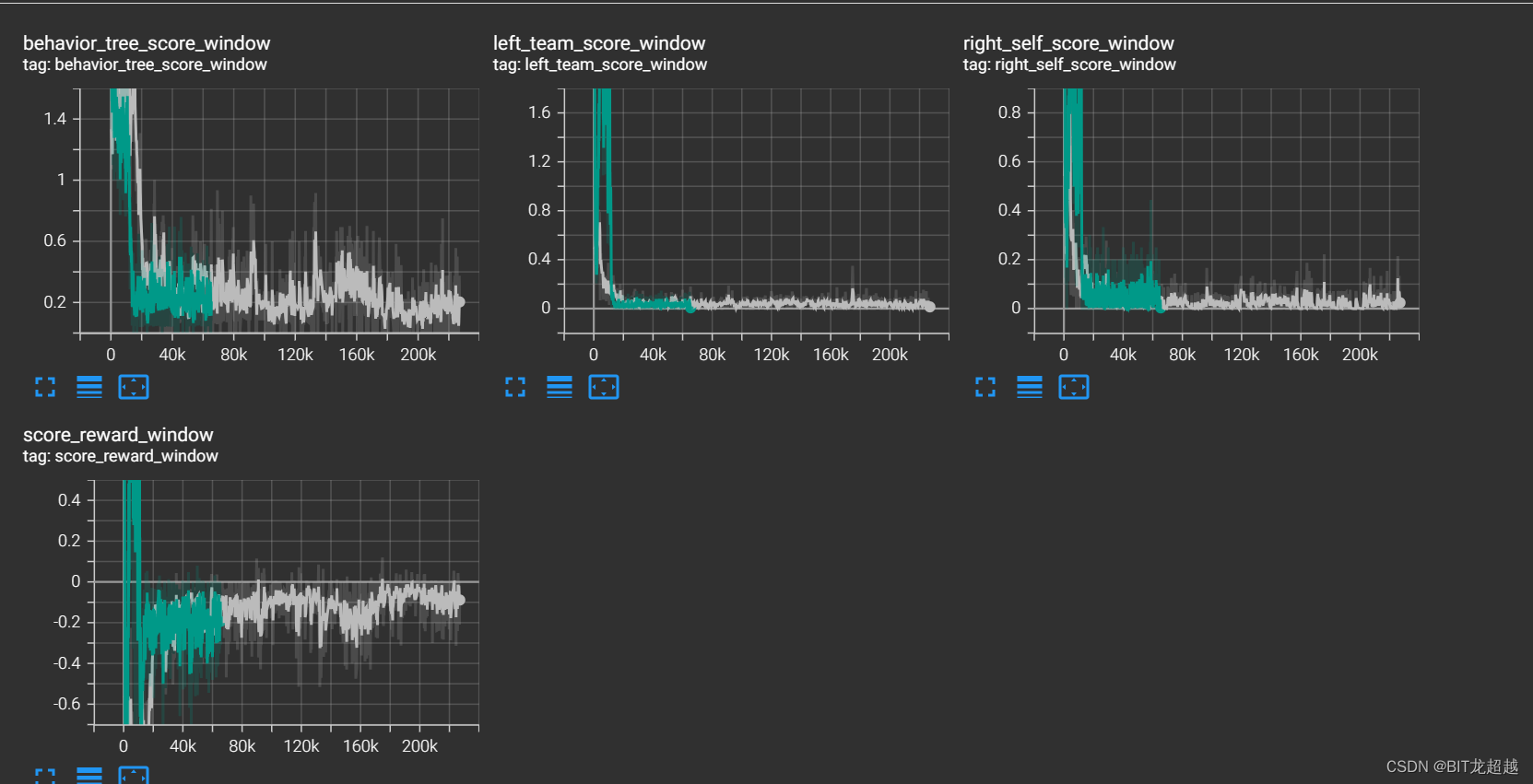
实验结果:
-
奖励:
-
得分
-
胜率

-
熵

-
value loss

-
policy loss
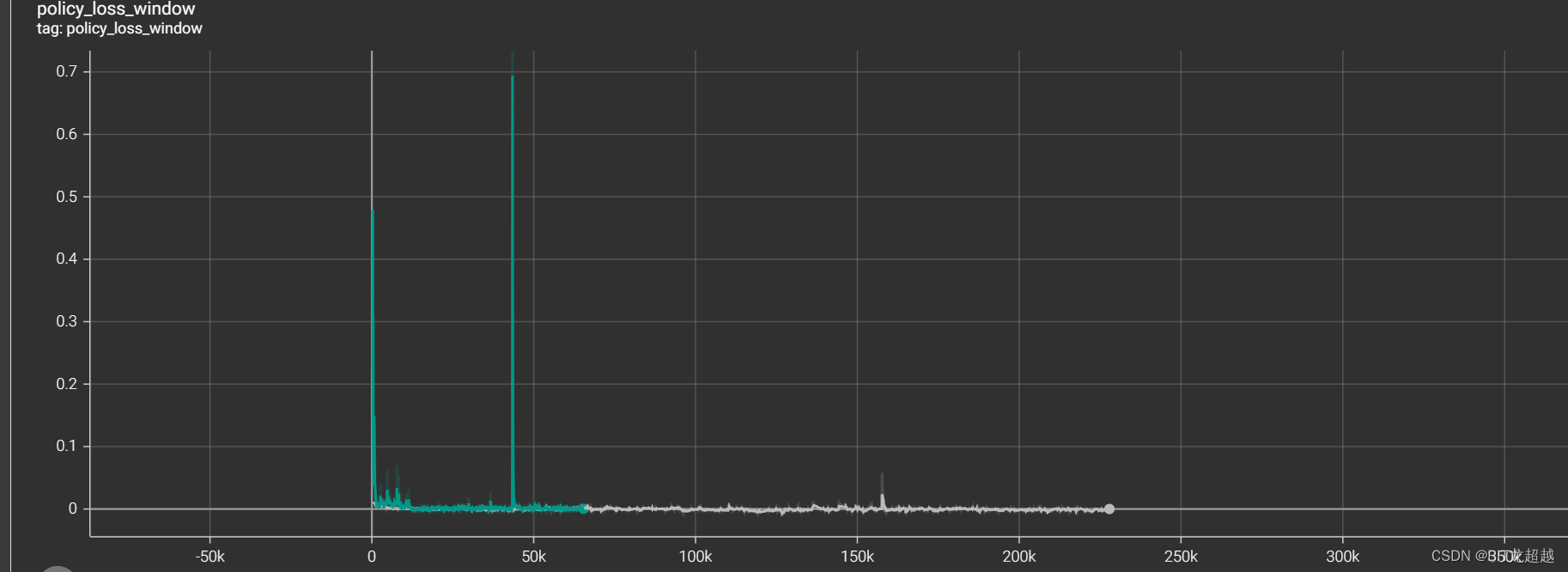
-
-
实验结论
-
面对混合对手,智能体策略迅速保守化,具体表现为自己得分下降同时让对手的得分下降,视频中效果为将球运到自己半场后不再进攻,这一现象不会因为规则占比的多少而出现明显不同。考虑造成这种现象的原因可能有以下两种:1. 由于规则和selfplay的策略差别较大,造成智能体进攻策略时,价值函数和策略函数更新过程中的方差大,因而偏向保守策略。 2. 单模型的selfplay模型更新有问题,一些右队的数据应该被抛弃的数据、影响了模型更新
-
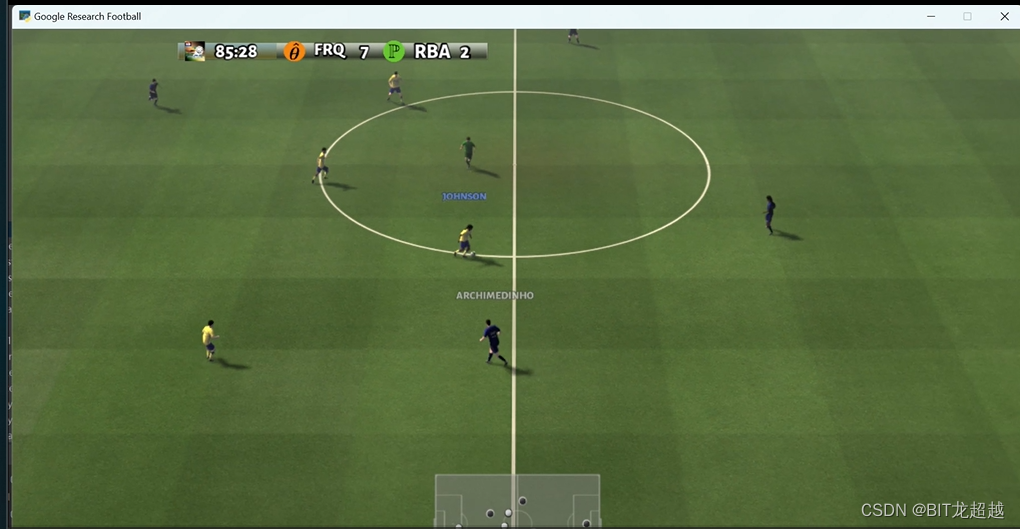
最终效果图,左队为强化学习智能体





![[嵌入式系统-4]:龙芯1B 开发学习套件-1-开发版硬件介绍](https://img-blog.csdnimg.cn/direct/bd1917b7c6484bc5b57f19f8a9ea03d3.png)