2.1 单行注释和多行注释
为程序添加注释可以用来解释程序某些部分的作用和功能,提高程序的可读性。除此之外,注释也是调试程序的重要方式。在某些时候,我们不希望编译、执行程序中的某些代码,这时就可以将这些代码注释掉。
Python语言允许在任何地方插入空字符或注释,但不能插入到标识符好字符串中间。
Python有两种注释方式:
(1)单行注释
(2)多行注释
python使用#表示当行注释的开始,跟在#号后面知道这行结束为止的代码都将被解释器忽略。单行注释就是在程序中注释一行代码,在python程序中将#放在需要注释的内容前面之前就可以了。
多行注释是指一次性将程序中的多行代码注释掉,在Python程序中使用三个单引号'''或三个双引号"""将注释内容括起来。
#print("Hello World!")
'''
这里面的内容位多行注释
Python语言真的很简单
'''
#print("这行代码被注释掉了,将不会被编译、执行!")
"""
这里用三个双引号括起来的多行注释
Python同样是允许的
"""
此外,添加注释也是调试程序的一个重要方法。如果觉得某段代码可能有问题,可以先把这段代码注释起来,让Python解释器忽略这段代码,再次编译、运行,如果程序可以正常运行,则可以说明错误就是由这段代码引起的,这样就缩小了错误所在范围,有利于排错;如果依然出现相同的错误,则可以说明错误不是由这段代码引起的,同样缩小了错误所在的范围。
2.2 变量
无论使用什么语言编程,总要处理数据,处理数据就需要使用变量来保存数据。
形象地看,变量就像一个个小容器,用于“盛放”程序中的数据。常量同样也用于“盛放”程序中的数据。常量和变量的区别在于:常量一旦保存某个数据之后,该数据就不能发生改变;但变量保存的数据则可以多次发生改变,只要程序对变量重新赋值即可。
Python使用等号(=)作为赋值运算符,例如a=10就是一条赋值语句,这条语句用于将10装入变量a中——这个过程就被称为赋值:将10赋值给变量a。
Python是弱类型语言,弱类型语言有两个典型的特征。
(1)变量无需声明即可直接赋值:对一个不存在的变量赋值就相当于定义一个新的变量。
(2)变量的数据类型可以动态改变:同一个变量可以一会被赋值为整数值,一会被赋值为字符串。
2.2.1 python是弱语言类型语言
>>>a=5
>>>
上面代码没有任何输出结果,只是开辟了一个变量a并赋值为5。
如果我们想看到某个变量的值,可以在交互解释器中输入该变量。
>>>a
5
>>>
从上面的交互式过程可以看到,交互解释器输出变量a的值为:5
接下来,如果改变a的值,只要将新的值赋给(装入)变量a即可。新赋的值会覆盖原来的值。
>>>a='Hello Charlie'
>>>
此时变量a的值就不是5了,而是字符串"Hello Charlie",a的类型也变成了字符串。
>>>a
'Hello Charlie'
如果此时想查看a的类型,可以使用python的type()函数。
提示:形象的说,函数就是一个有魔法的“黑盒子”,你可以向这个黑盒子提供一些数据,这个黑盒子会对这些数据进行处理,这些处理包括转换和输出结果。比如print()也是一个函数,它的作用就是输出传入的数据,此时type()函数的作用则用于输出传入数据类型。
在交互器中输入:
>>>type(a)
<class 'str'>
>>
此时可以看到a的类型是str。
将上面的交互过程转换成真正的python程序——只要将交互过程输出的每行代码放在一个文件中,并使用print()函数来输出变量(在交互解释器中只要输入变量名,交互解释器就会输出变量的值:但在Python程序中则必须使用print()函数才能输出变量),将文件保存为以.py结尾的源文件即可。上面的交互过程对应的程序如下:
#定义一个数值变量
a=5
print(a)
#重新将字符串赋值给a变量
a='Hello,Charlie'
print(a)
print(type(a))
运行上面的程序,没有任何问题,可以看到如下输出结果:

2.2.2 使用print函数输出变量
前面使用print()函数时都只输出了一个变量,但实际上print()函数完全可以同时输出多个变量,而且它具有更多丰富的功能。print()函数的详细语法格式如下:
print(value,...,sep=' ',end='\n',file=sys.stdout,flush=False)
从上面语法格式可以看出,value参数可以接受任意多个变量或值,因此print()函数完全可以输出多个值。
user_name='Charlie'
user_age=8
#同时输出多个变量和字符串
print("读者名:",uer_name,"年龄:",user_age)
运行结果:
![]()
从输入结果来看,使用print()函数输出多个变量时,print()函数默认以空格隔开多个变量,如果读者希望改变默认的分隔符,可通过sep参数进行设置。
#同时输出多个变量和字符串,指定分隔符
print("读者名:",user_name,"年龄:",user_age,sep='|')输出结果:
![]()
在默认情况下,print()函数输出后总会换行,这是因为print()函数的end参数的默认值为’\n’,这个“\n”代表了换行。如果希望print()函数输出后不会换行,则需重设end参数即可
#设置end参数,指定输出之后不会换行
print(40,'\t',end="")
print(50,'\t',end="")
print(60,'\t',end="")输出结果:
![]()
file参数指定print()函数的输出目标,file参数的默认值为sys.stdout,该默认值代表了系统标准输出,也就是屏幕,因此,print()函数默认输出到屏幕。实际上,完全可以通过改变参数让print()函数输出到特定文件中
f=open("poem.txt","w")#打开文件以便写入
print('沧海月明珠有泪',file=f)
print('蓝田日暖玉生烟',file=f)
f.close()print()函数的flush参数用于控制输出缓存,该参数一般保持为FALSE即可,这样可以获得较好的性能。
2.2.3变量的命名规则
python需要使用标识符给变量命名,其实标识符就是用于给程序中变量、类、方法命名的符号(简单来说,标识符就是合法的名字)。python语言的标识符必须以字母、下划线(_)开头,后面可以更任何数目的字母、数字、下划线(_)。
使用标识符时,需要注意如下规则:
- 标识符可以有字母、数字、下划线组成,其中数字不能为开头
- 标识符不能为Python的关键字,但可以包含关键字
- 标识符不能含有空格
2.2.4 python的关键字和内置函数
python还包含一系列关键字和内置函数,一般也不建议使用它们作为变量名。
如果开发者尝试使用关键字作为变量名,python解释器会报错
如果开发者使用内置函数的名字作为变量名,python解释器倒不会报错,只是该内置函数就被这个变量覆盖了,该内置函数就不能使用了。
#导入keyword模块
import keyword
#显示所有关键字
keyword.kwlist
上面这些关键字都不能作为变量名。


2.3 数值类型
数值类型是计算机程序最常用的一种类型,既可以用于记录各种游戏的分数、游戏角色的生命值、伤害值等,也可以记录各种物品的价格、数量等,python提供了对各种数值类型的支持,如支持整型、浮点型和复数。
2.3.1 整型
不管是小的整数值还是大的整数值,python都能够轻松处理。
#定义变量a,赋值为56
a=56
print(a)
#为a赋值与一个大整数
a=999999999999999999999999
print(a)
#type()函数用于返回变量的类型
print(type(a))运行结果:

上面程序中将9999999999999999999大整数赋值给变量a,python也不会发生溢出等问题,程序运行一样正常——这就是python的魅力:别乱搞那些乱七八糟的底层细节,非专业人士也不关心什么字节之类的细节。
从上面的输出结果可以看出,此时a的类型依旧是int。
python的整型支持None值(空值)。
a=None
print(a)python的整型数值有4中表示形式
- 十进制形式:最普通的整数就是十进制形式的整数
- 二进制整数:以0b或0B开头的整数就是二进制形式的整数
- 八进制形式:以0o或0O开头的整数就是八进制形式的整数(第二个字母是大写或小写的O)
- 十六进制形式:以0x或0X开头的整数就是十六进制形式的整数,其中10~15分别以a~f(此处也可用大写)来表示
为了提高数值(包括浮点型)的可读性,允许为数值(包括浮点型)增加下划线作为分隔符。这些分隔符并不会影响数值本身。
one_million=1_000_000
print(one_million)![]()
2.3.2浮点型
浮点型数值用于保存带小数点的数值,python的浮点数有两种表示形式。
- 十进制形式:这种形式就是平常简单的浮点数。浮点数必须包含一个小数点,否则会被当成整数类型处理。
- 科学计数形式:例如2.12e2(即2.12×102)。
必须指出的是,只有浮点型数值才可以用科学计数形式表示。
python是不允许除以0.不管是整型值还是浮点型,python都不允许除以0。
af1=5.23456
#输出af1的值
print("af1的值为:",af1)
af2=25.2345
print("af2的类型为:",type(af2))
f1=5.12e2
print("f1的值为:",f1)
f2=5e2
print("f2的值为:",f2)
print("f2的类型为:",type(f2))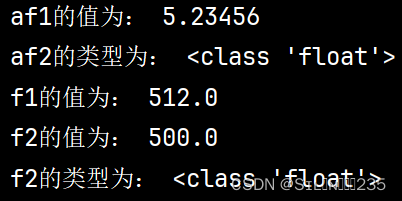
2.3.3 复数
python甚至可以支持复数,复数的虚部用j或J来表示。
如果需要在程序中对复数进行计算,可导入python的cmath模块(c代表complex),在该模块下包含了各种复数运算的函数。
提示:模块就是一个python程序,python正是通过模块提高了自身的可扩展性;python本身内置了大量模块,此外还有大量第三方模块,导入这些模块即可直接使用这些程序中定义的函数。
ac1=3+0.2j
print(ac1)
print(type(ac1))#输出复数类型
ac2=4-0.1j
print(ac2)
#复数运行
print(ac1+ac2)#输出两个复数相加
#导入cmath模块
import cmath
#sqrt()是cmath模块下的函数,用于计算平方根
ac3=cmath.sqrt(-1)
print(ac3)
2.4 字符串入门
2.4.1 字符串和转义字符
字符串的内容几乎包括任何字符,英文字符也行,中文字符也行。
字符串既可以用单引号括起来,也可以用双引号括起来,这没有任何区别。
str1='Charlie'
str2="qwer"
print(str1)
print(str2)但需要说明,python有时候没有我们期望的那么聪明——如果字符串内容本身包含了单引号或双引号,此时需要进行特殊处理。
- 使用不同的引号将字符串括起来。
- 对引号进行转义
先看第一种处理。假如字符串内容中包含了单引号,则可以用双引号将字符串括起来:
str3='I'm a cooder'由于上面字符串中包含了单引号,此时python会将字符串中的双引号与第一个双引号配对,这样就会把’I’当成字符串,而后面的m a cooder’就会变成多余的内容,从而导致语法错误。
为了避免这种问题,可以将上面代码改为如下形式:
str3="I'am a cooder"上面代码使用双引号将字符串括起来,此时python就会把字符串中的单引号当成字符串内容,而不是和字符串开始的引号配对。
假如字符串内容本身包含双引号,即可使用单引号将字符串括起来,例如:
str4='"Spring is here,let us jam!", said woodchuck.'接下来看第二种处理方式:使用转义字符。python允许使用反斜线(\)将字符串中的特殊字符进行转义。假如字符串既包含单引号,又包含双引号,此时必须使用转义字符,如:
str5='"we are scared,Let\'s hide in the shade",says the bird'2.4.2 拼接字符串
如果直接将两个字符串紧挨着写在一起,python就会自动拼接他 ,如:
s1 = "Hello,"'Charlie'
print(s1)运行结果:
![]()
上面这种写法只是书写字符串的一种特殊方法,并不能真正用于拼接字符串。python使用加号(+)作为字符串的拼接运算。
s2="python "
s3="is Funny"
s4=s2+s3
print(s4)2.4.3 repr和字符串
有时候,我们需要将字符串与数值进行拼接,而python不允许直接拼接数值和字符串,程序必须先将数值转换乘字符串。
为了将数值转换成字符串,可以使用str()或repr()函数
s1="这本书的价格是:"
p=99.8
#字符串直接拼接数值,程序报错
#print(s1+p)
#使用str()函数将数值转换成字符串
print(s1+str(p))
#使用repr()函数将数值转换成字符串
print(s1+repr(p))str()和repr()函数都可以将数值转换成字符串,其中str本身是python内置的类型(和int、float一样),而repr()则只是一个函数。此外repr还有一个功能,它会以python表达式的形式来表示值。
st="I will play my fife"
print(st)
print(repr(st))上面代码st本身就是一个字符串,但程序依然使用了repr()对字符串进行转换。
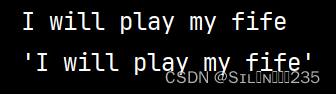
通过输出结果可以看出,如果直接使用print()函数输出字符串,将只能看到字符串的内容,没有引号:但如果先使用repr()函数对字符串进行处理,然后再使用print()函数执行输出,将可以看到带引号的字符串——这就是字符串的python的表达式形式。
提示:在交互解释器中输入一个变量或表达式时,python会自动使用repr()函数处理该变量或表达式。
2.2.4 使用input和raw_input获取用户输入
input()函数用于向用户生成一条提示,然后获取用户输入的内容。由于input()函数总会将用户输入的内容放入字符串中,因此用户可以输入任何内容,input()函数总会返回一个字符串。
msg=input("请输入你的值:")
print(type(msg))
print(msg)第一次运行该程序,输入一个整数:
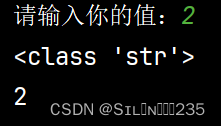
第二次运行该程序,我们输入一个浮点数:

第三次运行该程序,我们输入一个字符串:

从上面的运行过程可以看出,无论输入哪种内容,始终可以看到input()函数返回字符串,程序总会将用户输入的内容转换成字符串。
还有一个以前版本提供的一个raw_input()函数,和input()函数相同。
但以前的版本的input()函数就必须要格式正确,输入字符串时必须使用双引号,否则会报错。
2.4.5 长字符串
前面说多行注释提到三个双引号(单引号、双引号都可以)来包含多行注释内容。其实这是长字符串写法,只是由于在长字符串中可以放置任何内容,包括放置单引号、双引号都可以,如果所定义的长字符串没有赋值给任何变量,那么这个字符串就相当于被解释器忽略了,也就相当于被注释掉了。
实际上,使用三个引号括起来的长字符串完全可以赋值给变量。
s='''"Let's go fishing",said Mary.
"Ok,Let's go",said her brother
they walked to a lake'''
print(s)上面程序使用三个引号定义了长字符串,该字符串中既可以包含单引号,也可以包含双引号。
当程序中大段文本内容要定义成字符串时,优先推荐使用长字符串形式,因为这种形式非常强大,可以让字符串中包含任何内容,既可以包含双引号,也可以包含单引号。
此外,python还允许使用转义字符(\)对换行符进行转义,转义之后的换行符不会“中断”字符串。
s2='The quick brown fox \
jumps over the lazy'
print(s2)上面字符串s2的内容较长,故程序使用转义字符(\)对内容进行转义,这样就可以把一个字符串写成两行。
需要说明的是,python不是格式自由的语言,因此python程序的换行、缩进都有其规定的语法。所有,python的表达式不允许随便换行。如果程序需要对python表达式换行,同样需要使用转义字符(\)进行转义:
num=20+3/4+\
2*32.4.6 原始字符串
由于字符串中的反斜线都有特殊的作用,因此当字符串中包含反斜线时,就需要对其进行转义。
比如写一条Windows的路径:G:\publish\codes\02\2.4,如果在python程序中直接这样写肯定是不行的,需要写成:G:\\publish\\codes\\02\\2.4,这很烦人,此时可借助于原始字符串来解决这问题。
原始字符串以“r”开头,原始字符串不会把反斜线当成特殊字符。因此,上面的Windows路径可直接写成r’G:\publish\codes\02\2.4’。
如果原始字符串中包含引号,程序同样需要对引号进行转义(否则python同样无法对字符串的引号精确匹配),但此时用于转义的反斜线会变成字符串的一部分。
#原始字符串包含引号,同样需要转义
s2=r'"Let\'s go",said Charlie'
print(s2)运行结果:
![]()
由于原始字符串中的反斜线会对引号进行转义,因此原始字符串的结尾处不能是反斜线——否则字符串结尾处的引号就被转义了,这样就导致字符串不能正确结束。
如果确实要在原始字符串的结尾处包含反斜线怎么办呢?一种方式是不要使用原始字符串,而是改为使用长字符串写法(三引号字符串);另一种方式就是将反斜线单独写。
s3=r'Good Morning''\\'
print(s3)上面代码开始写了一个原始字符串r’Good morning’紧接着程序使用’\\’写了一个包含反斜线的字符串,python会自动将两个字符串连接在一起。运行结果:

2.4.7 字节串(bytes)
bytes类型是新版python新加的,用于代表字节串。字符串(str)由多个字符组成,以字符为单位进行操作;字节串(bytes)由多个字节组成,以字节为单位进行操作。
bytes和str除操作的数据单元不同之外,它们支持的所有方法都基本相同,bytes也是不变序列。
bytes对象只负责以字节(二进制格式)序列来记录数据,至于这些数据到底表示什么内容,完全由程序决定。如果采用合适的字符集,字符串可以转换成字节串;反过来,字节串也可以回复成对应的字符串。
由于bytes保存的就是原始的字节(二进制格式)数据,因此bytes对象可用于网络上传输数据,也可用于存储各种二进制格式的文件,比如图片、音乐等文件。
如果希望将一个字符串转换成bytes对象,有以下三种方式:
- 如果字符串内容都是ASCII字符,则可以通过直接在字符串之前添加b来构建字节串值。
- 调用bytes()函数(其实是bytes的构造方法)将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用UTF-8字符集。
- 调用字符串本身的encode()方法将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用UTF-8字符集。
#创建一个空的bytes
b1=bytes()
#创建一个空的bytes值
b2=b''
#通过b前缀指定hello是bytes类型的值
b3=b'hello'
print(b3)
print(b3[0])
print(b3[2:4])
#调用bytes方法将字符串转换成bytes对象
b4=bytes('我爱Python编程',encoding='utf-8')
print(b4)
#利用字符串的encode()方法编码bytes,默认使用UTF-8字符集
b5="学习python很有趣".encode('utf-8')
print(b5)b1~b5都是字节串对象,该程序示范了以不同方式来构建字节串对象。其中b2、b3都是直接在ASCII字符串前添加b前缀来得到字节串的;b4调用bytes()函数来构建字节串;而b5则调用字符串的encode方法来构建字节串。
运行结果:

上面的输出结果可以看到,字符串和字节串非常相似,只是字节串里的每个数据单元都是1字节。
提示:计算机底层有两个基本概念:位(bit)和字节(Byte),其中bit代表1位,要么是0,要么是1——就像一盏灯,要么打开,要么关闭;Byte代表1字节,1字节包含8位。
在字节串中每个数据单元都是字节,也是8位,其中4位(相当于4位二进制,最小为0,最大为15)可以用十六进制数来表示,因此每字节需要两个十六进制数来表示,所以可以看到上面输出的是:b'\xe6\x88\x91\xe7\x88\xb1Python\xe7\xbc\x96\xe7\xa8\x8b',比如\xe6就表示1字节,其中\x表示十六进制,e6就是两位的十六进制数。
如果程序获得了bytes对象,也可强调bytes对象的decode()方法将其解码成字符串
#将bytes对象解码成字符串,默认使用UTF-8进行解码
b5="学习python很有趣".encode('utf-8')
st=b5.decode('utf-8')
print(st)计算机底层并不能保存字符,但程序总是需要保存各种字符的,科学家想到一种方法:为每个字符编号,当程序要保存字符时,实际上保存的时该字符的编号;当程序读取字符时,读取的其实也是编号,接下来要去查“编号-字符对应表”(简称码表)才能得到实际的字符。因此,所谓的字符集,就是所有字符的编号组成的总和。对于同一个字符串,如果采用不同的字符集来生成bytes对象,就会得到不同的bytes对象。
2.5 深入使用字符串
2.5.1 转义字符
前面说过,在字符串中可以使用反斜线进行转义;如果字符本身包括反斜线,则需要使用“\\”表示,“\\”就是转义字符。
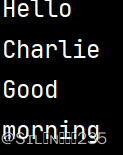
s='Hello\nCharlie\nGood\nmorning'
print(s)输出结果:
也可以使用制表符进行分隔。
s2='商品名\t\t单价\t\t数量\t\t总价'\
print(s2)2.5.2 字符串格式化
python提供了“%”对各种类型的数据进行格式化输出。
price=108
print("the book's price is %s"%price)这行代码中print函数包含三个部分,第一部分是格式化字符串(它相当于字符串模板),该格式化字符串中包含了一个“%s”占位符,它会被第三部分的变量或表达式的值代替;第二部分固定使用“%”作为分隔符。
格式化字符串中的“%s”被称为转换说明符,其作用相当于一个占位符,它会被后面的变量或表达式的值代替,“%s”指定将变量或值使用str()函数转换成字符串。
如果格式化字符串包含多个“%s”占位符,第三部分也应该对应地提供多个变量,并且使用圆括号将这些变量括起来。
user="Charlie"
age=9
#格式化字符串中有两个占位符,第三部分也应该提供两个变量
print("%s is %s years old"%(user,age))在格式化字符串中还有其他的形式。

当使用上面的转换说明符时可指定转换后的最小宽度。
num=-28
print("num is:%6i"%num)
print("num is:%6d"%num)
print("num is:%6o"%num)
print("num is:%6x"%num)
print("num is:%6X"%num)
print("num is:%6s"%num)运行结果:
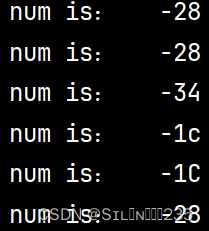
从运行结果可以看出,此时指定了字符串的最小宽度为6,因此程序转换数值时总宽度为6,程序自动在数值前面补充三个空格。
在默认情况下,转换出来的字符串总是右对齐的,不够宽度时左边补充空格。python也允许在最小宽度之前添加一个标志来该边这种行为。
(1)-:指定左对齐。
(2)+:表示数值总要带着符号(整数带“+”,负数带“-”)。
(3)0:表示不补充空格,而是补充0。
提示:这三个标志可以同时存在。
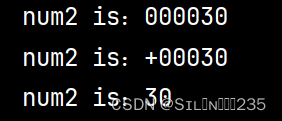
num2=30
#最小宽度为0,左边补0
print("num2 is:%06d"%num2)
#最小宽度为6,左边补0,总带上符号
print("num2 is:%+06d"%num2)
#最小宽度为6,左对齐
print("num2 is:%-6d"%num2)运行结果:

对于转换浮点数,python还允许指定小数点后的位数;如果转换的是字符串,python允许指定转换后的字符串的最大字符数。这个标志被称为精度值,该精度值放在最小宽度之后,中间用(.)隔开。
my_value=3.001415926535
#最小宽度为8,小数点后保留三位
print("my_value is:%8.3f"%my_value)
#最小宽度为8,小数点后保留3位,左边补0
print("my_value is:%08.3f"%my_value)
#最小宽度为8,小数点后保留3位,左边补0,始终带符号
print("my_value is:%+8.3f"%my_value)
the_name="Charlie"
#只保留3个字符
print("the name is:%.3s"%the_name)
#只保留两个字符,最小宽度为10
print("the name is:%10.2s"%the_name)运行结果:
2.5.3序列相关方法
字符串本质上是由多个字符组成的,因此程序允许提供索引来操作字符,比如获取指定索引处的字符,获取指定字符在字符串的位置等。
python字符串直接在方括号([])中使用索引即可获取对应的字符,字符串中第一个字符的索引为0、第二个字符的索引为1,以此类推。此外,python也允许从后面开始计算索引,最后一个字符的索引为-1,倒数第二个字符的索引为-2…依次类推。
s="crazyyit.org is very good"
#获取s中索引2的字符
print(s[2])#输出a
#获取s中从右边开始,索引为4的字符
print(s[-4])#输出g除可获取单个字符外,也可以在方括号中使用范围来获取字符串的中间“一段”(被称为字串)。
s="crazyyit.org is very good"
#获取s中索引3到索引5(不包含)的子串
print(s[3: 5])#输出zy
#获取s中索引3到倒数第5个字符的子串
print(s[3:-5])#输出zyit.org is very
#获取s中从倒数第6个字符到倒数第3个字符的子串
print(s[-6:-3])#输出y g上面用法还允许省略起始索引或结束索引。如果省略起始索引,相当于从字符串开始处开始截取;如果省略结束索引,相当于截取到字符串的结束处。
s="crazyyit.org is very good"
#判断s中从索引5到结束的子串
print(s[:5])#输出it.org is very good
#获取s中从倒数第6个字符到结束的子串
print(s[-6:])#输出y good
#获取s中从开始到索引5的子串
print(s[:5])#输出crazy
#获取s中从开始到倒数第6个字符的子串
print(s[:-6])#输出crazyit.org is ver此外,python字符串还支持用in运算符判断是否包含某个子串。
s="crazyyit.org is very good"
#判断s是否包含'very'子串
print('very' in s)#True
print('fkit' in s)#False如果要获取字符串长度,则可调用python内置的len()函数。
s="crazyyit.org is very good"
#输出s的长度
print(len(s))#24
#输出'test'的长度
print(len('test'))#4还可使用全局内置的min()和max()函数获取字符串中最小字符和最大字符
s="crazyyit.org is very good"
#输出s字符串中的最大字符
print(max(s))#z
#输出s字符串中的最小字符
print(min(s))#空格2.5.4 大小写相关方法
python字符串由内建的str类代表,python非常方便,它甚至不需要用户查询文档,python是“自带文档”的。
- dir():列出指定类或模块包含的全部内容(包含函数、方法、类、变量等)。
- help():查看某个函数或方法的帮助文档。
要查看str类包含的全部内容,可以在交互解释器中输入如下命令:
>>>dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
上面列出了str类提供的所有方法,其中以“__”开头、“__”结尾的方法被约定成私有方法,不希望被外部调用。
如果希查看某个方法的用法,则可使用help()函数。在交互解释器中输入如下命令:
>>>help(str.title)
Help on method_descriptor:
title(self, /)
Return a version of the string where each word is titlecased.
More specifically, words start with uppercased characters and all remaining
cased characters have lower case.从上面的介绍可以看出,str类的title()方法的作用是将每个单词的首字母大写,其他字母保持不变。
在str类中与大小写相关的常用方法如下:
- title():将每个单词的首字母改为大写。
- lower():将整个字符串改写成小写。
- upper():将整个字符串改写成大写。
>>>help(str.lower)
Help on method_descriptor:
lower(self, /)
Return a copy of the string converted to lowercase.a='our domain is crazyit.org'
#每个单词的首字母大写
print(a.title())
#每个字母小写
print(a.lower())
#每个字母大写
print(a.upper())Our Domain Is Crazyit.Org
our domain is crazyit.org
OUR DOMAIN IS CRAZYIT.ORG2.5.5 删除空白
str还提供了如下常用的方法来删除空白。
- strip():删除字符串前后的空白。
- lstrip():删除字符串前面(左边)的空白
- rstrip():删除字符串后面(右边)的空白。
需要说明的是,python的str是不可变的(不可变的意思是指,字符串一旦形成,它所包含的字符序列就不能发生任何改变),因此这三个方法只能返回字符串前面或者后面空白被删除之后的副本,并没有真正改变字符串本身。
如果在交互解释器中输入help(str.lstrip)来查看lstrip()方法的帮助信息,则可看到如下输出结果:
>>>help(str.lstrip)
Help on method_descriptor:
lstrip(self, chars=None, /)
Return a copy of the string with leading whitespace removed.
If chars is given and not None, remove characters in chars instead.从上面的介绍可以看出,lstrip()方法默认删除字符串左边的空白,但如果为该方法传入指定参数。则可删除该字符串左边的指定字符。
s=' this is a puppy'
#删除左边的空白
print(s.lstrip())
#删除右边的空白
print(s.rstrip())
#删除左右两边的空白
print(s.strip())
#再次输出s,将会看到s并没有改变
print(s)删除字符串前后指定字符的功能:
s2='i think it is a scarecrow'
#删除左边i、t、o、w字符
print(s2.lstrip('itow'))
#删除右边的i、t、o、w字符
print(s2.rstrip('itow'))
#删除两边的i、t、o、w字符
print(s2.strip('itow'))运行结果:
think it is a scarecrow
i think it is a scarecr
think it is a scarecr2.5.6 查找、替换相关方法
str还提供了如下常用的执行查找、替换等操作的方法。
- startswitch():判断字符串是否以指定子串开头。
- endswitch():判断字符串是否以指定子串结尾。
- find():查找指定子串在字符串中出现的位置,如果没招到指定子串,则返回-1.
- index():查找指定子串在字符串中出现的位置,如果没有找到指定的子串,则引发ValueError错误。
- replace():使用指定子串替换字符串中的目标子串。
- translate():使用指定的翻译映射表对字符串执行替换。
s='crazyit.org is a good site'
#判断s是否以crazyit开头
print(s.startswith('crazyit'))
#判断s是否以site结尾
print(s.endswith('site'))
#查找s中'org'出现的位置
print(s.find('org'))
#查找s中'org'出现的位置
print(s.index('org'))
#从索引9开始处查找'org'出现的位置
print(s.find('org',9))#-1
#从索引9处开始查找'org'出现的位置
print(s.index('org',9))#引发错误
s='crazyit.org is a good site'
#判断s是否以crazyit开头
print(s.startswith('crazyit'))
#判断s是否以site结尾
print(s.endswith('site'))
#查找s中'org'出现的位置
print(s.find('org'))
#查找s中'org'出现的位置
print(s.index('org'))
#从索引9开始处查找'org'出现的位置
print(s.find('org',9))#-1
#从索引9处开始查找'org'出现的位置
print(s.index('org',9))#引发错误
#将字符串中的所有it替换成xxxx
print(s.replace('it','xxxx'))
#将字符串中1个it替换成xxxx
print(s.replace('it','xxxx',1))
#定义翻译映射表:97(a)->945(α),98(b)->945(β),116(t)->964(γ)
table={97:945,98:946,116:964}
print(s.translate(table))#将字符串中的所有it替换成xxxx
print(s.replace('it','xxxx'))
#将字符串中1个it替换成xxxx
print(s.replace('it','xxxx',1))
#定义翻译映射表:97(a)->945(α),98(b)->945(β),116(t)->964(γ)
table={97:945,98:946,116:964}
print(s.translate(table))从上面程序可以看出,str的translate()方法需要根据翻译映射表中对字符串进行查找、替换。在上面程序中我们定义了一个翻译映射表,这种方式需要开发者能记住所有字符的编码,这显然不太可能。为此,python为str类提供一个maketrans()方法,通过该方法可以非常方便地创建翻译映射表。
假如定义a->α、b->β、c->γ的映射,程序只要将需要映射的所有字符作为maketrans()方法的第一个参数,将所有映射的目标字符作为maketrans()方法的第二个参数即可。在交互解释器中。
>>>table=str.maketrans('abt','αβγ')
>>>table
{97: 945, 98: 946, 116: 947}
>>>table=str.maketrans('abt','123')
>>>table
{97: 49, 98: 50, 116: 51}从上面的执行过程可以看到,不管是自己定义的翻译映射表,还是使用maketrans()方法创建的翻译映射表,其实都是为了定义字符与字符之间的对应关系,只不过该翻译映射表不能直接使用字符本身,必须使用字符的编码而已。
2.5.7 分割、连接方法
python还为str提供了分割和连接的方法:
- split():将字符串按指定分割符分割成多个短语。
- join():将多个短语连接成字符串。
s='crazyit.org is a good site'
#使用空白对字符串进行分割
print(s.split())#输出['crazyit.org','is','a','good','site']
#使用空白对字符串进行分割,最多只分割前两个单词
print(s.split(None,2))#输出['crazyit.org','is','a good site']
#使用点进行分割
print(s.split('.'))#['crazyit','org is a good ite']
mylist=s.split()
#使用'/'作为分割符,将mylist连成字符串
print('/'.join(mylist))#输出crazyit.org/is/a/good/site
#使用','作为分割符,将mylist连成字符串
print(','.join(mylist))#输出crazyit.org,is,a,good,site
#输出结果
'''
['crazyit.org', 'is', 'a', 'good', 'site']
['crazyit.org', 'is', 'a good site']
['crazyit', 'org is a good site']
crazyit.org/is/a/good/site
crazyit.org,is,a,good,site
'''从上面的运行结果可以看出,str的split()和join()方法互为逆操作——split()方法用于将字符串分割成多个短语;而join()方法则用于将多个短语连接成字符串。
2.6 运算符
运算符是一种特殊的符号,用来表示数据的运算、赋值和比较等。python语言使用运算符将一个或多个操作数连接成可执行语句,用来实现特定功能。
python语言中的运算符可分为几种:
- 赋值运算符
- 算术运算符
- 位运算符
- 索引运算符
- 比较运算符
- 逻辑运算符
2.6.1 赋值运算符
赋值运算符用于为变量或常量指定值,python使用“=”作为赋值运算符。通常,使用赋值运算符将表达式的值赋给另一个变量。
#为变量st赋值为Python
st='Python'
#为变量pi赋值为3.14
pi=3.14
#为变量visited赋值为True
visited=True除此之外,也可以使用赋值运算符将一个变量的值赋给另一个变量。
#将变量st的值赋给st2
st2=st
print(s2)值得指出的是,python的赋值表达式是有值的,赋值表达式的值就是被赋的值,因此python支持连续赋值。
a=b=c=20上面程序将c=20这个表达式的值赋给变量b,由于赋值表达式本身也有值,就是被赋的值。因此c=20这个表达式就是20,故b也被赋值为20;依次类推,变量a也被赋值为20.
赋值运算符还可用于将表达式的值赋给变量。
d1=12.34
#将表达式的值赋给d2
d2=d1+5
#输出d2的值
print("d2的值为:%g"%d2)#17.34python的赋值运算符也支持同时对多个变量赋多个值。赋值运算符与其他运算符结合后,扩展成功能更加强大的运算符。
2.6.2算术运算符
python支持所有的基本算数运算符,这些算数运算符用于执行基本的数学运算,如:加、减、乘、除、求余等,下面是7中基本运算符的介绍:
+:加法运算符。
a=5.2
b=3.1
the_num=a+b
#sum的值为8.3
print(the_num)除此之外,“+”还可以作为字符串的连接运算符。
s1='Hello, '
s2='Charlie'
#使用+连接两个字符串
print(s1+s2)#Hello, Charlie-法运算符。
c=5.2
b=3.1
sub=c-b
#sub的值为2.1
print(sub)除此之外,“-”也可作为求负的运算符。
#定义变量x,其值为-5.0
x=-5.0
#对x求负,其值为5.0
x=-x
print(x)但单目运算符“+”则不对操作数做任何改变。
#定义变量y,其值为-5.0
y=-5.0
#y的值依然是-5.0
y=+y
print(y)*:乘法运算符。
e=5.2
f=2.1
multiply=e*f
#multiply的值为16.12
print(multiply)此外,“*”还可以作为字符串的连续运算符,表示将n个字符串连接起来。
s3='crazyit '
#使用*将五个字符串连接起来
print(s3*5)#crazyit crazyit crazyit crazyit crazyit /或//:除法运算符。python的除法运算符有两个:“/”表示普通除法,使用它除出来的结果平常数学计算的结果是相同的(除不尽的时候,会产生小数部分);而“//”表示除法,使用它除出来的结果只有整数部分,小数部分将会被舍弃。
print(19/4)#4.75
print(19//4)#4
aa=5.2
bb=3.1
#aa/bb的值为1.6774193548387097
print(aa/bb)
#aa//bb的值为1.0
print(aa//bb)此外。python不允许0作为除数,否则会引发Zero DivisionError错误。
提示:在有些编程语言中,0作为除数会得到无穷大,包括正无穷大或负无穷大。
%:求余运算符。python不要求求余运算符的两个操作都为整数,python的求余运算符完全支持浮点数求余。求余运算的结果不一定总是整数,它使用第一个操作数来除第二个操作数,得到一个整除的结果后剩下的值就是余数。
由于求余运算符也需要进行除法运算,因此求余运算的第二个操作数不能为0,否则程序会报出ZeroDivisionError错误。
print(5%3)#2
print(5.2%3.1)#2.1
print(-5.2%-3.1)#-2.1
print(5.2%-2.9)#-0.6
print(5.2%-1.5)#-0.8
print(-5.2%1.5)#0.8
#print(5.0%0.0)#导致错误
"""
#输出结果
2
2.1
-2.1
-0.5999999999999996
-0.7999999999999998
0.7999999999999998
"""前三个算式的运行结果比较简单,它们进行的都是简单的求余运算。但5.2%-2.9的结果有点奇怪,我们预计它为-0.6,但实际输出的是-0.5999999999996.
这是由浮点数的存储机制导致的。计算机底层的浮点数的存储机制并不是精确保存每一个浮点数的值,暂时不要花太多时间去理解浮点数的存储机制,只要知道浮点数在python中可能产生精度丢失的问题。
**:乘方运算符。python支持使用“**”作为乘方运算符,这是一个使用非常方便的运算符。由于开方其实是乘方的逆运算,实际上使用“**”也可进行开方运算。
print(5**2)#25
print(4**3)#64
print(4**0.5)#2.0
print(27**(1/3))#3.02.6.3 位运算符
位运算符通常在图形、图像处理和创建设备驱动等底层开发中使用。使用位运算符可以直接操作数值和bit位,尤其是在使用自定义的协议进行通信时,使用位运算符对原始数据进行编码和解码也非常有效。
提示:初学者可跳过。
(1)&:按位与。
(2)|:按位或。
(3)^:按位异或。
(4)~:安慰取反。
(5)<<:左位移运算符。
(6)>>:右位移运算符。

按位非只需要一个操作数,这个运算符将把操作数在计算机底层的二进制码按位取反。
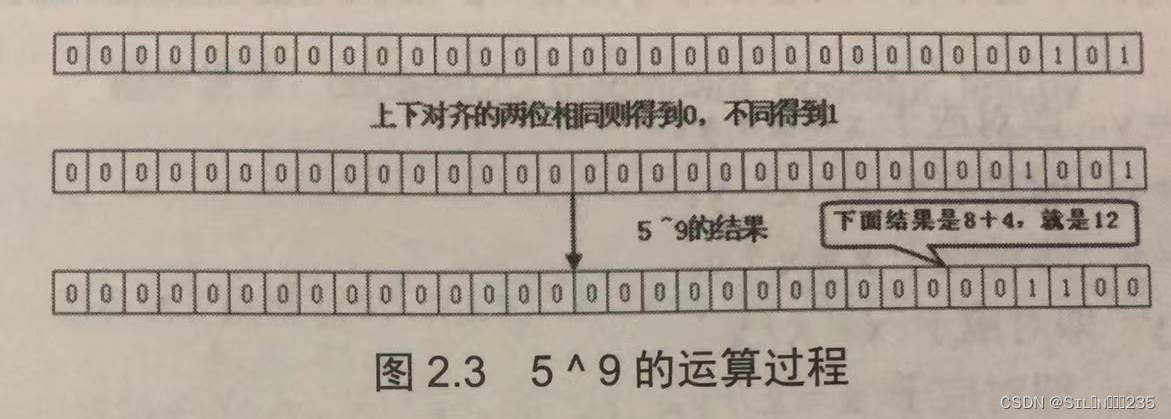
print(5&9)#1
print(5|9)#13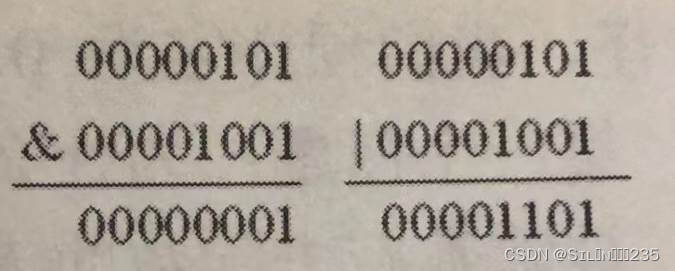
a=-5
print(~a)#输出4
print(5^9)#输出12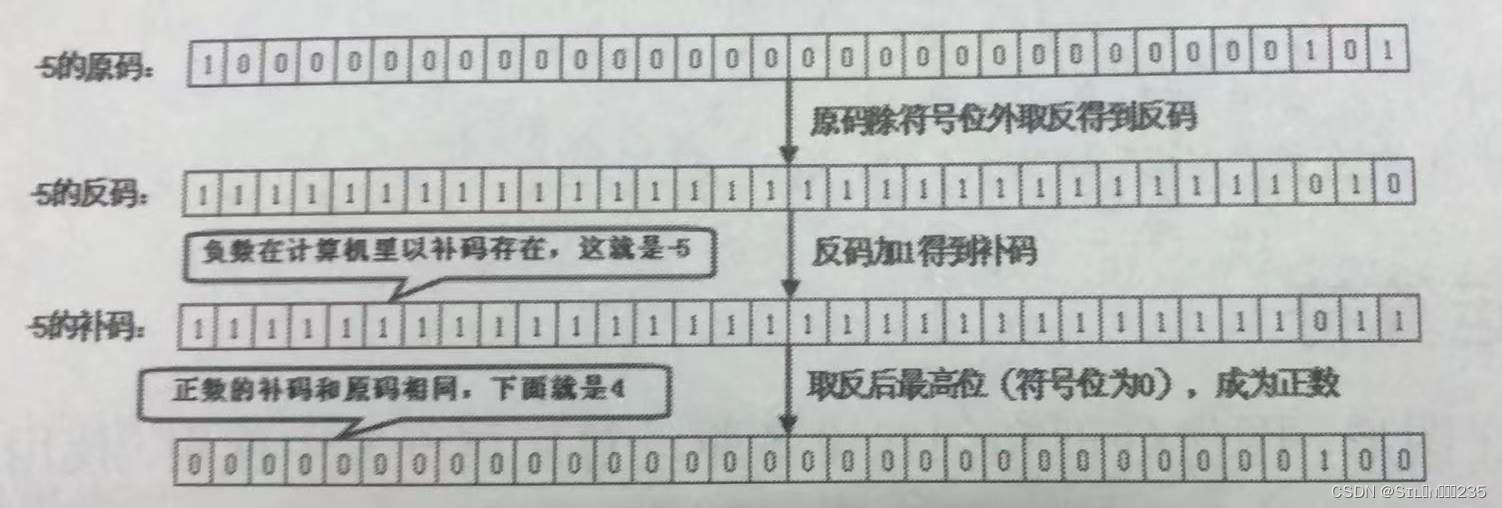
上面的运算过程涉及与计算机存储相关的内容。首先我们要明白:所有的数值在计算机底层都是以二进制形式存在的,原码直接将一个数值换算成二进制数。有符号整数的最高位是符号位,符号位为0代表正数,符号位为1代表负数。无符号整数则没有符号位,因此无符号整数只能表示0和整数。
为了方便计算,计算机底层以补码的形式保存所有的整数。补码的计算机规则是:正数的补码和原码完全相同,负数的补码是其反码加1;反码是对原码按位取反,只是最高位(符号位)保持不变。
左移运算符是将操作数的二进制码整体左移指定位数,左移后右边空出来的位以0来填充。
print(5<<2)#输出20
print(-5<<2)#输出-20
python的右移运算符为:>>。对于“>>”运算符而言,把第一个操作数的二进制右移指定位数后,左边空出来的位以原来的符号位来填充。即:如果第一个操作数原来是正数,则左侧补0,如果第一个操作数是负数,则左边补1.
b=-5
print(b>>2)#-2
注意:在进行位移运算时,左移就相当于乘以2的n次方,右移n位则相当于除以2的n次方(如果不能整除,实际返回的结果是小于除得结果数值的最大整数),不仅如此,进行位移运算只是得到一个新的运算结果,而原来的操作数本身时不会改变的。
2.6.4 扩展后的赋值运算符
赋值运算符可以与算数运算符、位运算符等结合,扩展成功能更加强大的运算符。扩展后的赋值运算符:
(1)+=:对于x+=y,即对应x=x+y
(2)-=:对于x-=y,即对应x=x-y
(3)*=:对于x*=y,即对应x=x*y
(4)/=:对于x/=y,即对应x=x/y
(5)//=:对于x//=y,即对应x=x//y
(6)%=:对于x%=y,即对应x=x%y
(7)**=:对于x**=y,即对应x=x**y
(8)&=:对于x&=y,即对应x=x&y
(9)|=:对于x|=y,即对应x=x|y
(10)^=:对于x^=y,即对应x=x^y
(11)<<=:对于x<<=y,即对应x=x<<y
(12)>>=:对于x>>=y,即对应x=x>>y
只要能使用扩展后的赋值运算符,填充都推荐使用这种赋值运算符。
2.6.5 索引运算符
索引运算符就是方括号,在方括号中既可以使用单个索引值,也可以使用索引范围。实际上,在使用索引范围时,还可以指定步长。
a='abcdefghijklmn'
#获取索引2到索引8的子串
print(a[2:8:3])#输出cf
#获取索引2到索引8的子串,步长为2
print(a[2:8:2])#输出ceg2.6.6 比较运算符和bool类型
python提供了bool类型来表示真(对)或假(错),比如常见的5>3比较算式,这个是正确的,在程序中称为真(对),python使用True来表示,假如不正确,则用False来表示,称为假(错)。
由此可见,bool类型就是用于表示某个事情的真或假,如果这个事情是正确的,用True来表示,否则用False表示。
比较运算符用于判断两个值(这两个值可以是变量,也可以是常量,还可以是表达式)之间的大小,比较运算的结果是bool值(True表示真,False表示假)。python支持的比较运算符有:
(1)>:大于,如果运算符前面的值大于后面的值,则返回True,否则返回False。
(2)>=:大于或等于,如果运算符前面的值大于或等于后面的值,则返回True,否则返回False。
(3)<:小于,如果运算符前面的值小于后面的值,则返回True,否则返回False。
(4)<=:小于等于,如果运算符前面的值小于等于后面的值,则返回True,否则返回False。
(5)==:等于,如果运算符前面的值等于后面的值,则返回True,否则返回False。
(6)!=:不等于,如果运算符前面的值不等于后面的值,则返回True,否则返回False。
(7)is:判断两个变量所引用的对象是否相同,相等则返回True。
(8)is not:判断两个变量所引用的对象是否不相同,相等则返回True。
#输出True
print(5>3)
#输出False
print(3**4>=90)
#输出True
print(20>=20.0)
#输出True
print(5.0==5)
#输出False
print(True==False)
#输出结果
True
False
True
True
Falsepython的两个bool值分别是True和False,但实际上True也可被当成整数1使用,False也可以被当成整数0使用。也就是说,True、False两个值完全可一次参与各种算术运算。
#输出True
print(1==True)
#输出True
print(0==False)
print(True+False)#输出1
print(False-True)#输出-1关于==与is看上去很相似,但实质上有区别,==只比较两个变量的值,但is要求两个变量引用同一个对象。
import time
#获取当前时间
a=time.gmtime()
b=time.gmtime()
print(a==b)#a和b两个时间相等,输出True
print(a is b)#a和b不是同一个对象,输出False上面代码中a、b两个变量都代表当前系统时间,因此a、b两个变量的时间值相等,故程序使用“==”判断返回True。但由于a和b两个变量分别引用不同的对象(每次调用gmtime()函数都返回不同的对象),因此a is b返回False。
实际上,python提供一个全局的id()函数来判断变量所引用的对象的内存地址(相当于对象在计算机内存中存储的门牌号),如果两个对象所在的内存地址相同(相当于它们住在同一个房间内,计算机同一块内存任一时刻只能存放一个对象),则说明这两个对象其实是同一个对象。由此可见,is判断其实就是要求通过id()函数计算两个对象时返回相同的地址。
print(id(a))#1823994182848每次输出都不相同
print(id(b))#1823994183104每次输出都不相同从运行结果中将会看到a、b两个变量所引用的对象的内存地址是不同的,这样通过is来判断a、b两个变量自然也就输出False。
2.6.7 逻辑运算符
逻辑运算符用于操作bool类型的变量、常量或表达式,逻辑运算返回值也是bool值。
python的逻辑运算符有三个:
- and:与,前后两个操作数必须是True才返回True,否则返回False。
- or:或,前后两个操作数中至少有一个True才返回True,两个都为False才会返回False。
- not:非,只需要一个操作数,如果操作数为True,则返回False;如果操作数为False,则返回True。
#直接对False求非运算,将返回True
print(not False)
#5>3返回True,20.0大于10 ,因此结果返回True
print(5>3 and 20.0>10)
#4>=5返回False,"c">"a",返回True,求或后返回True
print(4<=5 or "c">"a")有时候程序需要使用多个逻辑运算符来组合复杂的逻辑。
程序中组合逻辑,使用圆括号保证运算顺序非常重要。
2.6.8 三目运算符
python可通过if语句来实现三目运算符的功能,因此可以近似地把这种if语句当成三目运算符。作为三目运算符的if语句的语法格式如下:
True_statements if expression else False_statements
三目运算符的规则是:先对逻辑表达式expression求值,如果逻辑表达式返会True,则执行并返回True_statements的值;如果逻辑表达式返回False,则执行并返回False_statements的值。
a=3
b=5
st="a大于b"if a>b else "a不大于b"
print(st)#a不大于b实际上,如果只是为了在控制台输出提示信息,还可以将上面的三目运算符表达式改为如下的形式:
a=3
b=5
print("a大于b")if a>b else print("a不大于b")#a不大于bpython支持在三目运算符的True_statements或False_statements中放置多条语句。python支持两种放置方式。
- 多条语句以英文逗号隔开:每条语句都会执行,程序返回多条语句的返回值组成的元组。
- 多条语句以英文分号隔开:每条语句都会执行,程序只返回第一条语句的返回值。
a=3
b=5
st=print("crazyit"),'a大于b'if a>b else "a不大于b"
print(st)
#输出结果
crazyit
(None, 'a不大于b')上面程序中True_statements为print(“crazyit”),’a’大于’b’,这两条语句都会执行,程序将返回这两条语句的返回值组成的元组。由于print()函数没有返回值,相当于它的返回值为None。
逗号改为分号后:
a=3
b=5
st=print("crazyit");x=20 if a>b else "a不大于b"
print(st)
print(x)
#输出结果
crazyit
None
a不大于b此时虽然True——statements包含两天语句,但程序只会返回第一条语句print(“crazyit”)的返回值,该语句同样返回None,因此相当于str的返回值为None。
三目运算符支持嵌套,用嵌套的三目运算符可执行更复杂的判读。
2.6.9 in运算符
python提供in运算符,用于判断某个成员是否位于序列中。
除in运算符之外,python还提供了in的反义词:not in
s='crazyit.org'
print('it'in s)#True
print('it'not in s)#False
print('fkit'in s)#False
print('fkit'not in s)#True使用in运算符除可判断字符串是否包含特定子串之外,还可以判断序列是否包含子序列。
2.6.10 运算符的结合性和优先级
所有数学运算都是从左到右进行的,python语言中大部分运算符都是从左到右结合的,只有单目运算符、赋值运算符和三目运算符例外,它们是从右向左结合的,也就是说,它们是从右向左运算的。
乘法和加法是两个可以结合的运算符,也就是说,这两个运算符左右两边的操作数是可以互换位置而不影响结果。
运算符有不同的优先级,所谓优先级就是在表达式运算中的运算顺序。

虽然python运算符存在优先级的关系,但并不推荐过度依赖运算符的优先级,因为这会导致程序的可读性降低,因此有两个建议:
- 不要把一个表达式写得过于复杂,如果一个表达式过于复杂,则把它分成几步来写。
- 不要过多依赖运算符的优先级来控制表达式的顺序,这样可读性太差,应尽量使用“()”来控制表达式的执行顺序。