目录
环境
背景
探寻
元数据的加载策略
如何解决
升级版本到5.x
调大max.connections.size.per.query
max.connections.size.per.query分析
服务启动阶段相关源码
服务运行阶段相关源码
受到的影响
注意事项(重要)
其他
环境
- Spring Boot 2.2.13
- Sharding JDBC 4.1.1
背景
因项目特殊性问题,系统需要处理大量数据,有多个数据源,且因数据过多每个数据源都有分表,导致启动时加载过慢
2024-01-10 10:12:25:088[main][INFO][][c.alibaba.druid.pool.DruidDataSource.init(1009)]{dataSource-1} inited
2024-01-10 10:12:25:243[main][INFO][][ShardingSphere-metadata.loadShardingSchemaMetaData(131)]Loading 5 logic tables' meta data.
2024-01-10 10:12:25:527[main][INFO][][ShardingSphere-metadata.load(70)]Loading 4947 tables' meta data.
2024-01-10 10:13:14:312[main][INFO][][ShardingSphere-metadata.createMetaData(59)]Meta data load finished, cost 49078 milliseconds.日志信息中,可以看出其中一个数据源ShardingSphere正在加载大量的表元数据(近5000个表)。耗时接近一分钟
探寻
元数据的加载策略
ShardingSphere元数据的加载策略和优化方式
- 使用 SQL 查询替换原生 JDBC 驱动连接:在 5.0.0-beta 版本之前,采用的方式是通过原生 JDBC 驱动原生方式加载。在 5.0.0-beta 版本中,逐步采用了使用数据库方言,通过 SQL 查询的方式,多线程方式实现了元数据的加载,进一步提高了系统数据加载的速度。
- 减少元数据的加载次数:对于系统通用的资源的加载,遵循一次加载,多处使用。在这个过程中,也要权衡空间和时间,不断的进行优化,减少元数据的重复加载,提高系统整体的效率。
如何解决
升级版本到5.x
升级版本到5.x【5.x版本对元数据的加载做了优化:多线程加载,且相同分表只加载一个】
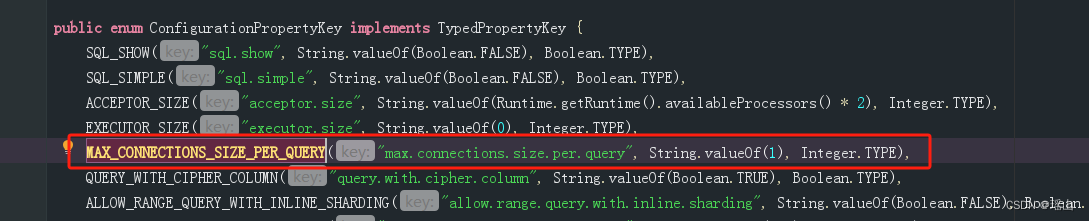
调大max.connections.size.per.query
(记得看最后注意事项)
max.connections.size.per.query是ShardingSphere中的参数,表示每个查询请求在每个分片中能够使用的最大连接数, 也就是执行sql的时候,对每一个数据库进行操作的时候的connection数量
在 application.properties 或 application.yml 文件中添加自定义配置来调整每个查询请求在每个分片中能够使用的最大连接数
spring.shardingsphere.datasource.[name].max-connections-size-per-query=20其中,[name] 是数据源名称。你可以根据实际情况调整 max-connections-size-per-query 的值。
重新启动应用程序,新的配置将生效。
如果有个性化数据源,可以这么修改
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
@Bean(name = "dataSourceSharding")
public DataSource getShardingDataSource(@Qualifier("dataSource") DataSource dataSource) throws SQLException {
// 分表规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(/** user分表规则 */);
//数据源
Map<String, DataSource> result = new HashMap<>(Numbers.INT_16);
result.put("dataSource", dataSourceBill);
Properties properties = new Properties();
properties.put(ConfigurationPropertyKey.MAX_CONNECTIONS_SIZE_PER_QUERY.getKey(), 20);
return ShardingDataSourceFactory.createDataSource(result, shardingRuleConfig, properties);
}max.connections.size.per.query分析
升级版本需要考虑的太多了, 还是分析下修改max.connections.size.per.query的影响吧
分析源代码发现,元数据的加载可以是单线程串行加载,也可以是多线程并行加载,而使用哪种策略,最终基于sharding-jdbc的一个配置:max.connections.size.per.query
max.connections.size.per.query默认值是1,此时元数据加载是单线程串行加载。而配置大于1时,会根据该配置的值,采用多线程并行加载。
修改这个参数,受影响的有启动时加载元数据和sql执行时
服务启动阶段相关源码
{@link org.apache.shardingsphere.sql.parser.binder.metadata.schema.SchemaMetaDataLoader#load}
/**
* Load schema meta data.
*
* @param dataSource data source
* @param maxConnectionCount count of max connections permitted to use for this query
* @param databaseType database type
* @return schema meta data
* @throws SQLException SQL exception
*/
public static SchemaMetaData load(final DataSource dataSource, final int maxConnectionCount, final String databaseType) throws SQLException {
List<String> tableNames;
try (Connection connection = dataSource.getConnection()) {
tableNames = loadAllTableNames(connection, databaseType);
}
log.info("Loading {} tables' meta data.", tableNames.size());
if (0 == tableNames.size()) {
return new SchemaMetaData(Collections.emptyMap());
}
List<List<String>> tableGroups = Lists.partition(tableNames, Math.max(tableNames.size() / maxConnectionCount, 1));
Map<String, TableMetaData> tableMetaDataMap = 1 == tableGroups.size()
? load(dataSource.getConnection(), tableGroups.get(0), databaseType) : asyncLoad(dataSource, maxConnectionCount, tableNames, tableGroups, databaseType);
return new SchemaMetaData(tableMetaDataMap);
}
private static Map<String, TableMetaData> load(final Connection connection, final Collection<String> tables, final String databaseType) throws SQLException {
try (Connection con = connection) {
Map<String, TableMetaData> result = new LinkedHashMap<>();
for (String each : tables) {
result.put(each, new TableMetaData(ColumnMetaDataLoader.load(con, each, databaseType), IndexMetaDataLoader.load(con, each, databaseType)));
}
return result;
}
}
maxConnectionCount对应的就是max.connections.size.per.query
服务运行阶段相关源码
假设我们的用户很多,进行了分表,分表数量10,对应的表为:user_1,user_10
当我们在查询用户,如select * from user where name='张三',这个是逻辑sql
sharding-jdbc会将逻辑sql改写成真实sql,也就是这样:
select * from user_1 where name='张三'
...
select * from user_10 where name='张三'
共10条真实sql
{@link org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSQLExecuteGroups}
{@link org.apache.shardingsphere.shardingjdbc.jdbc.adapter.AbstractConnectionAdapter#createConnections }
这两处源码涉及的max.connections.size.per.query包括两点:
- 计算需要一次性获取多少个连接去执行所有的真实sql;
- 归并方式,也就是源码中的ConnectionMode,它分为两种,一种叫内存限制模式,一种叫连接限制模式
当max.connections.size.per.query小于真实sql数量时,走的是连接限制模式(通俗理解:因为连接不够用,需要把sql执行完后,将查询结果先放到内存,然后释放连接用于查询其他sql),反之走的是内存限制模式(连接足够用,每个sql占据一个连接,查询结果不需要一次性放到内存,而是分批次拉取数据,在内存中做归并聚合)。
private List<InputGroup<StatementExecuteUnit>> getSQLExecuteGroups(final String dataSourceName,
final List<SQLUnit> sqlUnits, final SQLExecutePrepareCallback callback) throws SQLException {
List<InputGroup<StatementExecuteUnit>> result = new LinkedList<>();
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1, 1);
List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());
int count = 0;
for (List<SQLUnit> each : sqlUnitPartitions) {
result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
return result;
}受到的影响
默认情况下,max.connections.size.per.query=1
- 如果分片数据在两个数据库,默认情况下,执行引擎执行的时候,就是每个数据库都会有一个connection去查询。
- 如果是一个数据库两个表,就是串行查询的,第一次查询的全部结果会全部放在了内存里面等待第二次查询的结果然后再一起合并
配置的变更影响有三点
- 启动时加载元数据的逻辑
- sql执行时的逻辑
- 查询结果归并的逻辑
注意事项(重要)
- max.connections.size.per.query的配置不能大于datasource的最大线程数,否则一旦分表数量大,就会因为无法一次获取足够的连接而报错
- 如果代码中有很多不带分片参数的分表查询,而max.connections.size.per.query又设置的比较大,会极大的消耗数据库连接,可能导致其他业务逻辑无法获取连接而报错
- 如果代码中有不带分片参数的分表查询,而max.connections.size.per.query又设置的比较小,会走连接限制模式,所有数据会放到内存后再做聚合,如果查询结果较大,可能爆掉内存;
- 只要代码中避免掉不带分片参数的查询更新操作,适当加大max.connections.size.per.query的值,可以提升启动速度而不会对项目的运行造成任何影响。
其他
Apache ShardingSphere分表的简单使用和常见问题-CSDN博客
持续更新ing!