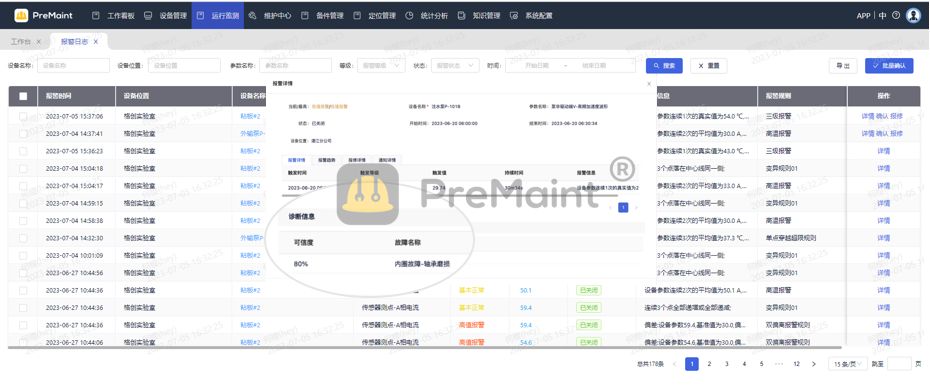
1. 引言
多模态大语言模型(Multi-modality Large Language Models,后续简称多模态大模型)能够提供强大的通用级别视觉感知/理解能力,甚至可以通过自然语言与人类进行无缝对话和互动。虽然多模态大模型的这些能力已经在多个视觉语言任务中得到了探索和验证,例如图像字幕、视觉问题回答、跨模态关联,以及传统的视觉任务,如图像分类或分割,但大多数关注点都集中在对视觉内容的高级感知和理解上。与此同时,多模态大模型在 low-level 视觉感知和理解方面的能力仍然不清楚,这在图像质量评估(IQA)以及感知视觉失真(噪音、模糊)等相关任务上发挥着重要作用,以及其他 low-level 属性(颜色、光照、构图、风格等),这些属性可能与自然照片的美学和情感以及人们对新兴计算机图形生成或 AI 生成图像的偏好有关。
这些 low-level 视觉能力与广泛的应用密切相关,例如推荐、摄像系统指导,或视觉质量增强。因此,评估目前这些通用基础模型在 low-level 视觉感知和理解方面的能力至关重要,理想情况下,可以减轻大量人力资源为每个具体的 low-level 任务提供反馈。
1.1 定义多模态大模型的三个low-level能力

1.2 多模态大模型如何模拟与low-level视觉感知和理解相关的人类能力?
简单来说,答案是语言,这是多模态大模型的基本属性。具体而言,我们定义多模态大模型在low-level视觉方面的两种新兴语言能力如下:
能力1(A1):low-level 属性的感知。如图 1(a)所示,像人类一样,多模态大模型应该能够准确地回答与 low-level 属性相关的简单问题,例如在查询“这张图像清晰吗?”时回答“不清晰”。
能力2(A2):通过自然语言进行描述。如图1(b)所示,像人类一样,多模态大模型应该能够用自然语言描述图像的质量和其他low-level信息。这些描述应该既完整又准确。
能力3(A3):与人类意见一致的精确评估。如图 1©所示,多模态大模型应该能够为图像预测可量化的质量分数,这些分数可以与人类对 low-level 视觉外观的均值意见分数(MOS)一致。
本文主要贡献
- 我们建立了一个关于多模态大模型 low-level 感知能力的基准。为了实现这一目标,我们构建了首个平衡且综合的 LLVisionQA数据集,其中包含 2,990 张图像,每张图像都配有一个与 low-level相关的问题和答案。LLVisionQA
包括三种问题类型和四个 low-level 关注领域,以确保多样性。 - 我们定义了一个基准流程,用于评估多模态大模型的 low-level 描述能力,其中包括一个包含 499 张图像的LLDescription 数据集,其中包含由专家标注的长篇的黄金质量描述,以及通过 GPT辅助评估多模态大模型描述的完整性、准确性和相关性,与黄金描述进行比较。
- 为了评估精确的质量评估能力,我们提出了一种统一的基于 softmax
的质量预测策略,适用于所有多模态大模型,基于它们的概率输出。通过我们的实验验证了该策略的有效性,该策略为通用多模态大模型与传统 IQA
任务之间建立了桥梁,使它们可以输出可量化的图片质量分数。
2. 基准建构
2.1 感知能力

图2
在感知能力任务中,我们设计了一系列的判断题和选择题来对多模态大模型进行考察。问题的设计首先遵循 low-level 视觉关注领域的四象限原则:
第一个轴:失真vs其他 low-level 属性。
主要轴区分了两类 low-level 感知属性:
1)技术失真被视为直接降低图像质量的低 low-level 特征。
2)与审美相关的其他 low-level 属性,这些属性可被人类感知并引发不同的情感。
第二个轴:全局感知vs局部上下文感知。
在最近的 low-level 视觉研究中,观察到人类对 low-level 视觉的感知经常与更高级的上下文理解交织在一起。例如,晴朗的天空可能缺乏复杂的纹理,但其实是有很好的清晰度。鉴于这些差异,我们策划了局部上下文感知问题,要求多模态大模型正确把握内容的上下文或其他相关的上下文,以便正确回答问题,而其他问题则归于全局感知。
在 LLVisionQA 数据集中,我们策划了三种问题类型,即 Yes-or-No(是不是)、What(是什么)和 How(怎么样),以模拟真实人类的多种提问形式。
2.2 描述能力

图3
在描述任务中,我们评估多模态大 low-level 信息的语言描述能力。这个任务是 image captioning 的姊妹任务,用自然语言描述图像内容,特别关注图像的 low-level 外观。为了自动评估这种能力,我们首先创建了一个黄金 low-level 描述数据集,称为 LLDescribe,包括 499 张图像中的每张图像都由专家提供的一个长篇(平均40个字)黄金描述。有了这些黄金文本描述,我们能够使用单模态的 GPT 来衡量多模态大模型输出的 low-level 描述在三个维度上的质量:完整性、准确性以及相关性。
2.3 评估能力

图4
在 Q-Bench 中,我们旨在公平地比较不同多模态大模型在多样化的 low-level 外观上的评估能力。因此,我们的原则是为所有多模态大模型在所有 IQA 数据集上定义一个统一、最简单的指导原则。我们提出了一个基于 Softmax 的评估策略,将多模态大模型输出形容词的概率提取出来利用 softmax 来量化为质量分数。
我们也提供了一个简单的伪代码实现,仅9行,可适用于各种多模态大模型。
3. 实验展示
3.1 感知能力

图5
为了全面评估多模态大模型的感知能力,我们评估了多模态大模型在 LLVision 数据集的不同子类别上的多选正确性。我们很高兴看到大多数多模态大模型在所有子类别上都明显优于随机猜测。考虑到所有参与的大模型都没有接受任何关于 low-level 视觉属性的明确训练,这些结果表明了这些通用模型在进一步与相应的 low-level 数据集进行精细调整时具有强大的潜力。在所有方法中,基于 Flan-T5 的 InstructBLIP 在这个问答任务上达到了最高的准确性(比其 Vicuna-based 对应版本好5%)。另一个关键观察结果是,几乎所有方法在失真方面的感知能力都不如其他 low-level 属性。唯一的例外是 LLaMA-Adapter-V2,它是唯一采用多尺度特征作为视觉输入的多模态大模型。
3.2 描述能力

图6
就描述能力而言,mPLUG-Owl 是最平衡的,能够在所有三个维度上排名前三;Kosmos-2 获得了最高的总分,但相对较强的幻觉(低准确度)影响了它的综合能力。此外,我们注意到多模态大模型在不同维度上的能力差异很大。在完整性和准确性维度上,即使在所有多模态大模型中,最好的也无法获得很高的分数;相反,几乎所有大模型都达到了可接受的标准(0.8/2.0)。就相关性维度而言,一些大模型可以获得非常好的能力(Kosmos-2、Otter-v1),但另一方面,这些相关性最高的模型仍然在准确性方面表现不佳。总的来说,就提供 low-level 视觉描述而言,目前所有多模态大模型只具有相对有限的能力。
3.3 评估能力

图7
为了衡量评估能力,我们在 7 个 IQA 数据集上评估了 10 个多模态大模型的性能,这些数据集至少包含 1,000 张图像和每张图像 15 个人类评分(itu,2000)。主要地,我们注意到大多数大模型在非自然环境(CGI,AIGC,人工失真)下比 NIQE 更具鲁棒性,显示出它们在更广泛的 low-level 外观上具有通用评估器的潜力。此外,一些方法(例如,mPLUG-Owl)在没有在训练过程中明确与人类意见对齐的情况下,已经可以达到比大多数多模态大模型的视觉骨干 CLIP-ViT-Large-14 更好或类似的结果。然而,当前的多模态大模型在视觉质量评估任务中仍然不够稳定(例如,在LIVE-itw上的Otter-v1),且在细粒度的情况下(LIVE-FB,CGIQA-6K)表现较弱,这在未来可能会得到改善。
4. 结论
在这项研究中,我们构建了 Q-Bench,这是一个用于检验多模态大模型在 low-level 视觉能力方面的进展的基准。我们期望这些大型基础模型可以成为通用智能,最终能够减轻人类的努力,因此我们提出多模态大模型应该具备三种重要且不同的能力:对 low-level 视觉属性的准确感知、对 low-level 视觉信息的精确和完整的语言描述,以及对图像质量的定量评估。为了评估这些能力,我们收集了两个多模态的 low-level 视觉基准数据集,并提出了一个基于 Softmax 的统一的多模态大模型定量 IQA 策略。我们的评估证明,即使没有任何针对 low-level 的具体训练,一些杰出的多模态大模型仍然具有不错的 low-level 能力。然而,这些多模态大模型要成为真正可靠的通用 low-level 视觉助手还有很长的路要走。我们衷心希望 Q-Bench 中发现的观察结果可以激发未来的大模型增强 low-level 感知和理解能力。