时间序列的第一个基础大模型
1 方法
- 最basic的Transformer架构
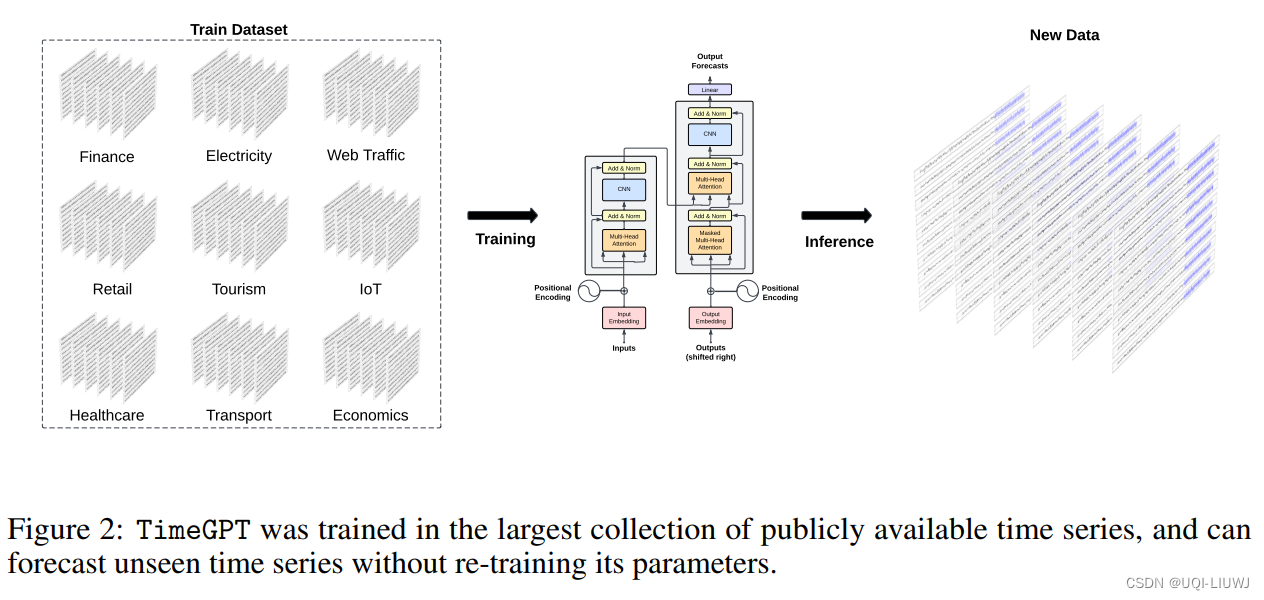
- 采用了公开可用的最大时间序列数据集进行训练,包含超过1000亿个数据点。
- 训练集涵盖了来自金融、经济、人口统计、医疗保健、天气、物联网传感器数据、能源、网络流量、销售、交通和银行业等广泛领域的时间序列
- 具有多种季节性、不同长度的周期和各种趋势类型的序列
- 还在噪声和异常值方面有所不同
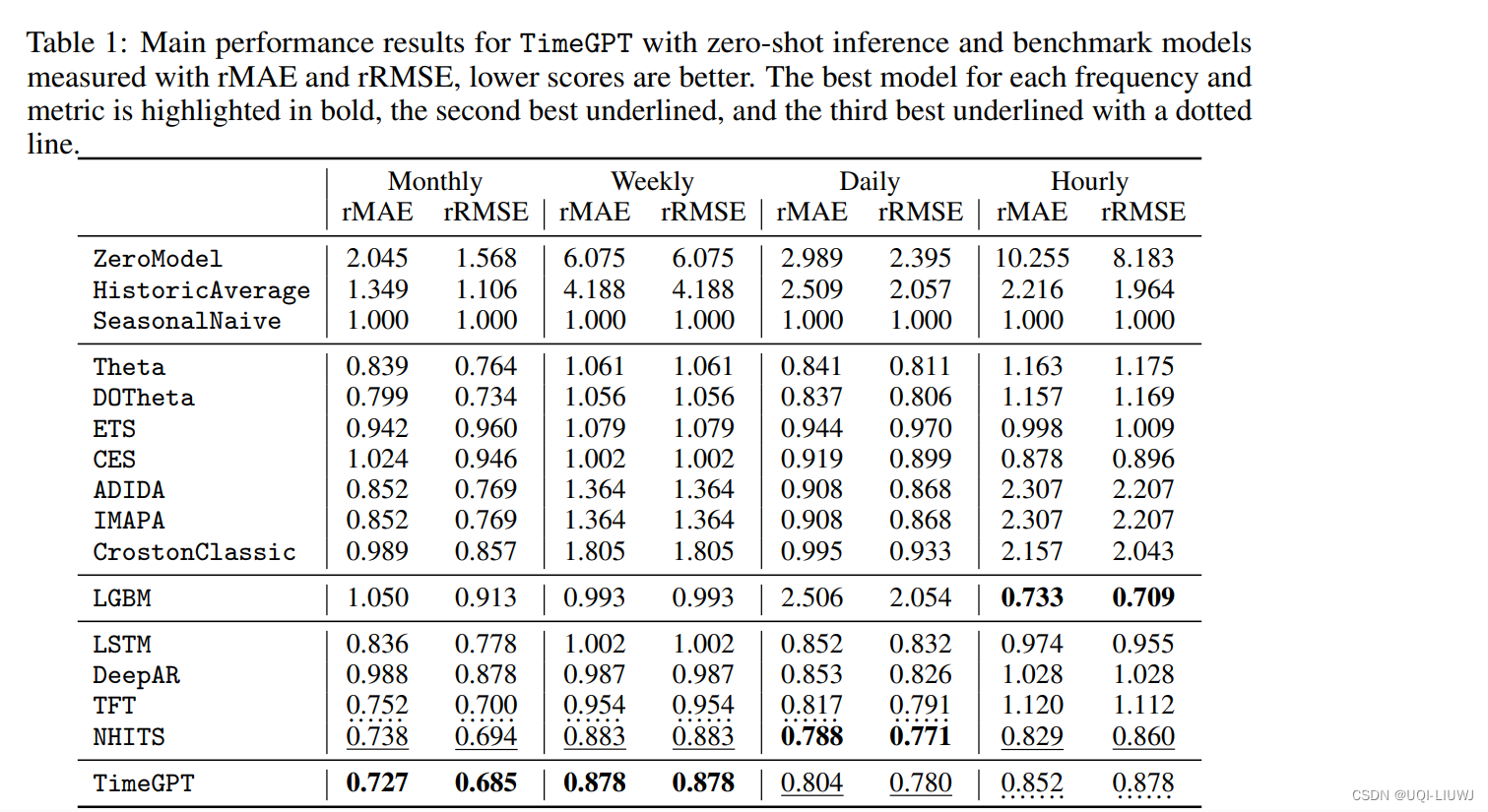
2 结果

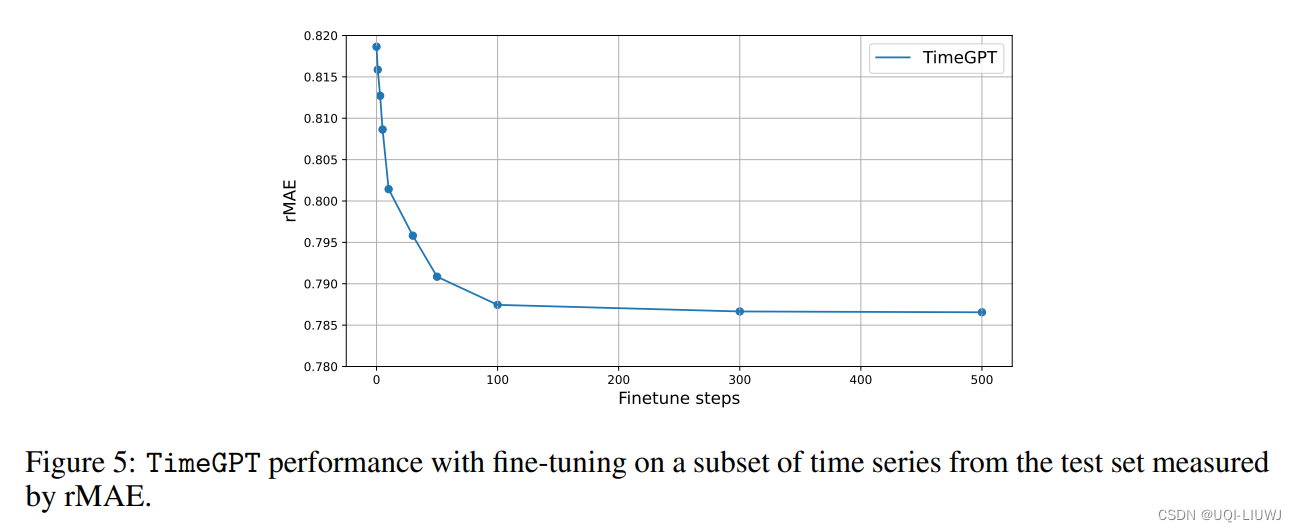
3 一点私货时间
- 论文并没有怎么说明不同时间序列在不同的数据维度、采样频率、周期性下,如何train TimeGPT,我个人其实是对时间序列大模型不太乐观的(可能没过多久就被打脸了。。。)
-
在NLP中,无论使用哪种语言,它们背后都遵循着一些普遍的、共通的语言规律(由同一个dynamics生成的各国语言)。这些规律反映了人类表达思想和交流信息的共性。因此,NLP中的大模型能够通过学习这些普遍规律来理解和生成不同语言。=
-
相比之下,时间序列数据可以来自多种不同的领域,如交通、气象、金融等,每个领域的数据都遵循着其特有的规律。这些规律可能相互之间没有太多的共性,使得模型很难通过学习一种类型的时间序列数据来理解或预测另一种类型的数据。此外,时间序列数据往往仅仅是一系列的数字,缺乏NLP中的丰富语义和上下文信息,这使得从时间序列数据中学习和提取规律更加困难。
-
- 论文比较的baseline emm,有点老。。。