读AI3.0笔记08_自然语言
news2026/2/15 18:14:15
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1417578.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
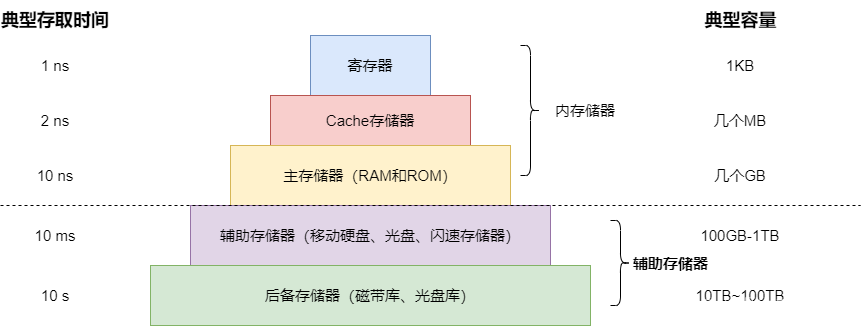
内存储器之只读存储器(ROM),随机存取存储器(RAM)和Cache详解
内存储器
计算机中的存储器分为内存和外存两大类。
内存的存取速度快而容量相对较小,它与CPU直接相连,用来存放等待CPU运行的程序和处理的数据;外存的速度较慢而容量相对很大,它与CPU并不直接连接,用于永久性地存放计…
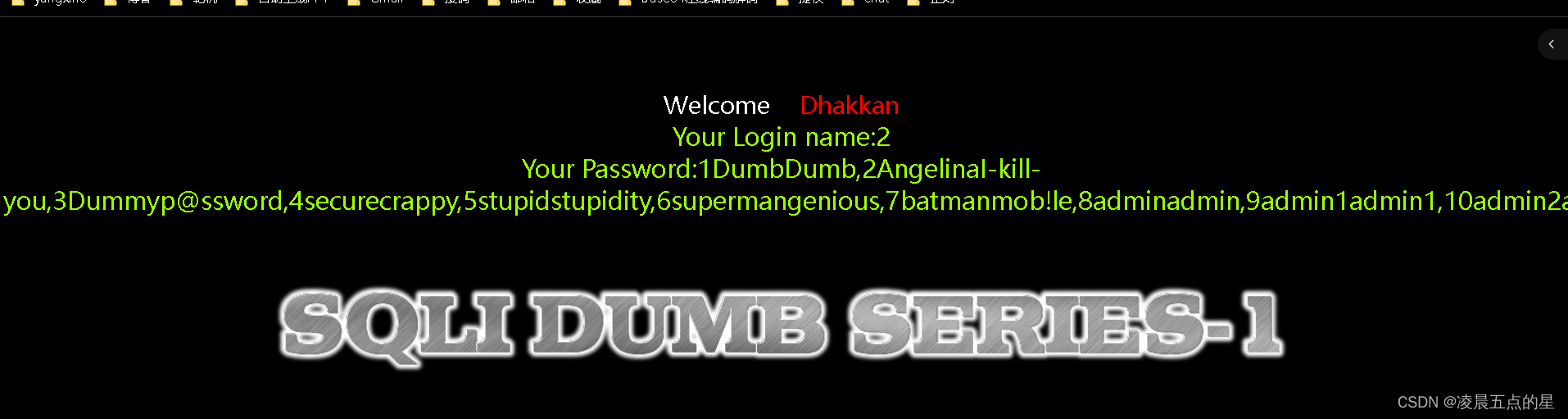
网络安全04-sql注入靶场第一关
目录 一、环境准备
1.1我们进入第一关也如图:
编辑
二、正式开始第一关讲述
2.1很明显它让我们在标签上输入一个ID,那我们就输入在链接后面加?id1
编辑 2.2链接后面加个单引号()查看返回的内容,127.0.0.1/sqli/less-1/?id1,id1
…

Unity 迭代器模式(实例详解)
文章目录 简介**实例1:遍历数组****实例2:自定义迭代器类****实例3:异步加载资源****实例4:游戏关卡序列****实例5:无限生成敌人** 简介
在Unity中,虽然不直接使用迭代器模式的原始定义(即设计…

PDF标准详解(一)——PDF文档结构
已经很久没有写博客记录自己学到的一些东西了。但是在过去一年的时间中自己确实又学到了一些东西。一直攒着没有系统化成一篇篇的文章,所以今年的博客打算也是以去年学到的一系列内容为主。通过之前Vim系列教程的启发,我发现还是写一些系列文章对自己的帮…
Springmvc-@RequestBody
SpringBoot-2.7.12
请求的body参数无法转换,服务端没有报错信息打印,而是响应的状态码是400
PostMapping("/static/user")
public User userInfo(RequestBody(required false) User user){user.setAge(19);return user;
}PostMapping("…
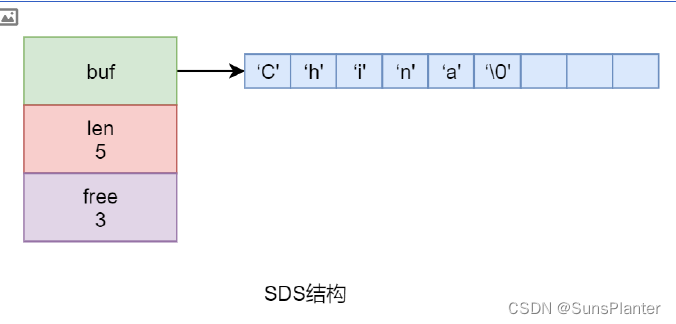
05 Redis之Benchmark+简单动态字符串SDS+集合的底层实现
3.8 Benchmark
Redis安装完毕后会自动安装一个redis-benchmark测试工具,其是一个压力测试工具,用于测试 Redis 的性能。 src目录下可找到该工具
通过 redis-benchmark –help 命令可以查看到其用法
3.8.1 测试1 3.9 简单动态字符串SDS
无论是 Redis …

【面试】测试开发面试题
帝王之气,定是你和万里江山,我都护得周全 文章目录 前言1. 网络原理get与post的区别TCP/IP各层是如何传输数据的IP头部包含哪些内容TCP头部为什么有浮动网络层协议1. 路由协议2. 路由信息3. OSPF与RIP的区别Cookie与Session,Token的区别http与…

Redis学习——高级篇①
Redis学习——高级篇① Redis7高级之单线程和多线程(一) 一、Redis单线程VS多线程1.Redis的单线程部分1.1 Redis为什么是单线程?1.2 Redis所谓的“单线程”1.3 Redis演进变化1.3.1 Redis 3.x 单线程时代性能很快的原因1.3.2…

林浩然科学趣谈:妙解麦克斯韦方程的电磁奥秘
林浩然科学趣谈:妙解麦克斯韦方程的电磁奥秘 Lin Haoran’s Scientific Banter: Playful Insights into the Electromagnetic Mysteries of Maxwell’s Equations 在科学的璀璨星河中,林浩然如同一颗热爱探索的行星,以其独特的幽默和严谨的态…
latent-diffusion model环境配置--我转载的
latent-diffusion model环境配置,这可能是你能够找到的最细的博客了_latent diffusion model 训练 autoencoder-CSDN博客 前言
最近在研究diffusion模型,并对目前最火的stable-diffusion模型很感兴趣,又因为stable-diffusion是一种latent-di…
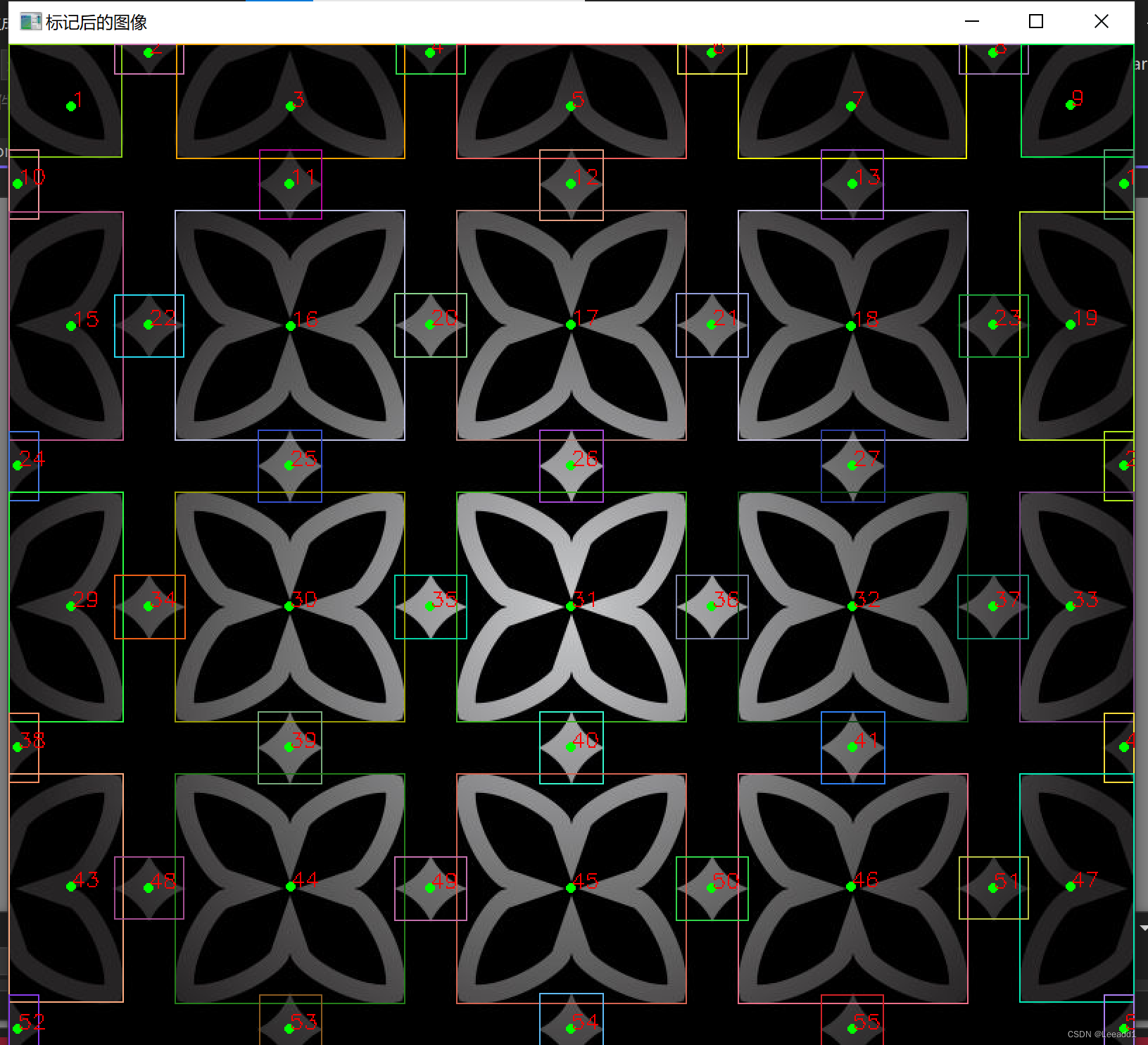
opencv#35 连通域分析
连通域分割原理
像素领域介绍: 4邻域是指中心的像素与它邻近的上下左右一共有4个像素,那么称这4个像素为中心像素的4邻域。
8邻域是以中心像素周围的8个像素分别是上下左右和对角线上的4个像素。
连通域的定义(分割)分为两种:以4邻域为相邻判定条件的连通域分割和…

C++笔记之RTTI、RAII、MVC、MVVM、SOLID在C++中的表现
C++笔记之RTTI、RAII、MVC、MVVM、SOLID在C++中的表现 —— 杭州 2024-01-28 code review! 文章目录 C++笔记之RTTI、RAII、MVC、MVVM、SOLID在C++中的表现1.RTTI、RAII、MVC、MVVM、SOLID简述2.RAII (Resource Acquisition Is Initialization)3.RTTI (Run-Time Type Informat…

steam幻兽帕鲁服务器配置费用报价,4核16G
幻兽帕鲁服务器价格多少钱?4核16G服务器Palworld官方推荐配置,阿里云4核16G服务器32元1个月、96元3个月,腾讯云换手帕服务器服务器4核16G14M带宽66元一个月、277元3个月,8核32G22M配置115元1个月、345元3个月,16核64G3…

某度Pan复活,突破限速,很强大!
软件简介:
软件【下载地址】获取方式见文末。注:推荐使用,更贴合此安装方法!
作为国内领先的云存储服务提供商之一,某度Pan为用户提供了一个便捷的文件存储和分享平台。然而,用户普遍反映某度Pan的下载速…
简盒工具箱iapp源码
一款工具箱兼做软件库。 新增远程更新功能 修复了部分失效功能
修复了偶尔会卡在启动页的情况
源码下载:https://download.csdn.net/download/m0_66047725/88776737
更多资源下载:关注我。

漏洞原理MySql注入 Windows中Sqlmap 工具的使用
漏洞原理MySql注入 SQLmap是一款开源的自动化SQL注入工具,用于检测和利用Web应用程序中的SQL注入漏洞。以下是SQLmap工具的使用总结: 安装和配置:首先需要下载并安装SQLmap工具。安装完成后,可以通过命令行界面或图形用户界面来使…
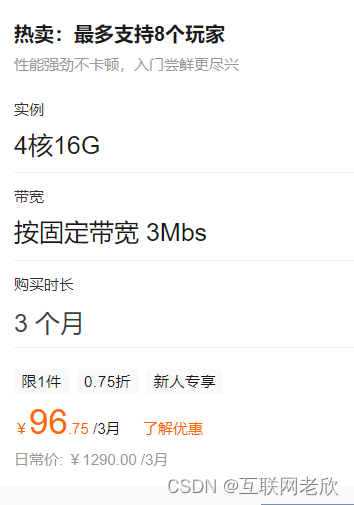
2024幻兽帕鲁服务器,阿里云配置
阿里云幻兽帕鲁服务器Palworld服务器推荐4核16G配置,可以选择通用型g7实例或通用算力型u1实例,ECS通用型g7实例4核16G配置价格是502.32元一个月,算力型u1实例4核16G是432.0元/月,经济型e实例是共享型云服务器,价格是32…
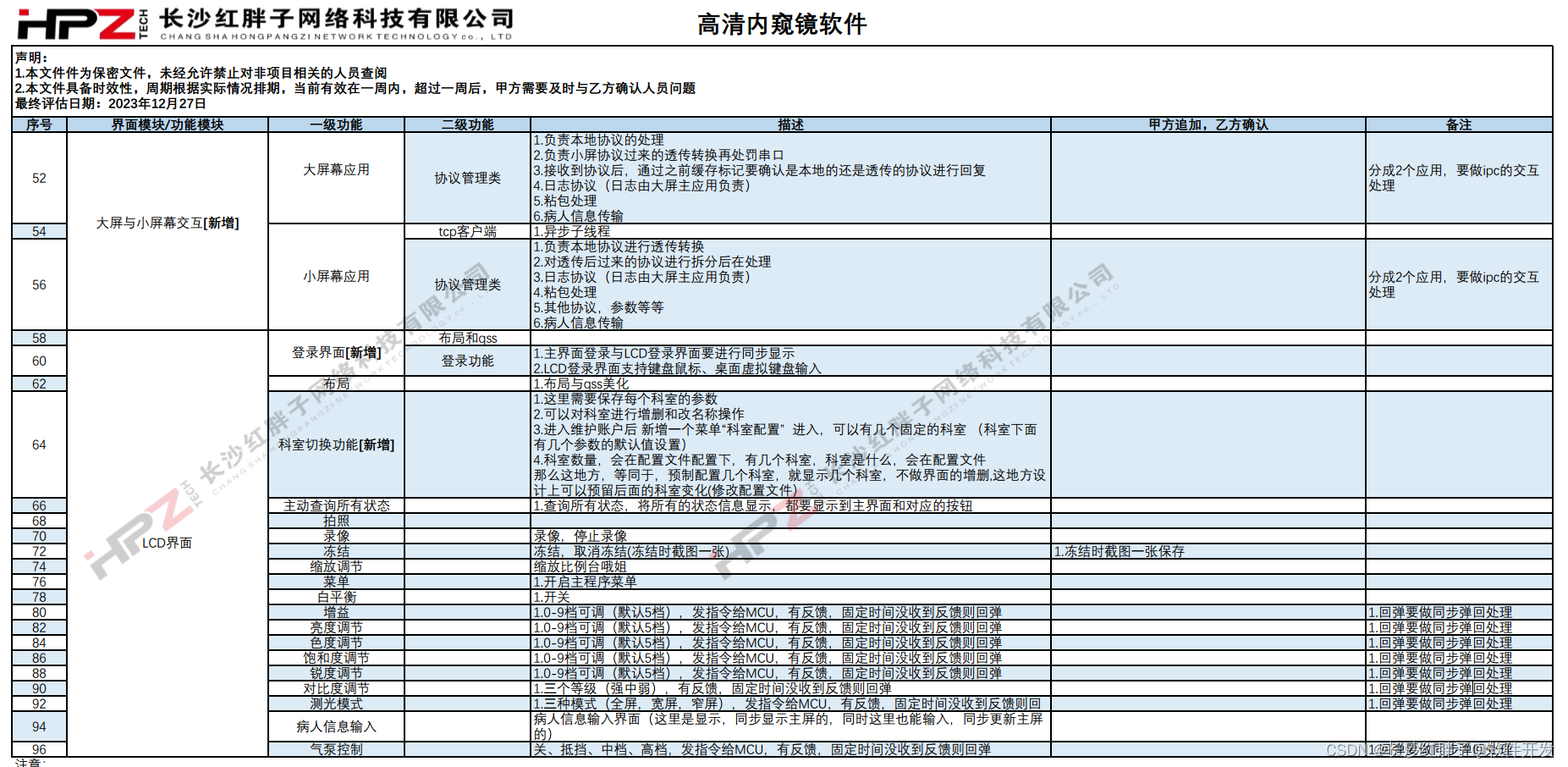
案例分享:长沙红胖子公司内部评估高清内窥镜功能列表流程产出成果鉴赏
若该文为原创文章,转载请注明出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/135898723
红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软硬结…
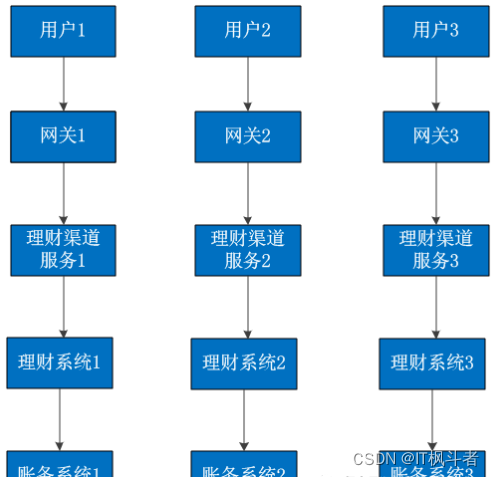
多地多活与单元化架构
多地多活与单元化架构
背景
在业务发展到一定阶段之后,任何因故障而导致的服务中断都会带来巨大的损失。为了提高系统的伸缩能力与高可用能力,我们都不断的在努力消除系统单点瓶颈。如使用应用集群是为了解决服务层的单点问题,使用主从数据…
FreeRTOS任务知识详解
前言 本篇文章旨在记录我学习FreeRTOS实时操作系统中,有关于Free RTOS的任务知识的记录。由于RTOS系统的核心就是任务管理,而且我们大多数人学习RTOS的初衷就是为了使用RTOS的多任务处理功能! 初步上手RTOS首先应该掌握的就是任务的创建、删除…