多地多活与单元化架构
背景
- 在业务发展到一定阶段之后,任何因故障而导致的服务中断都会带来巨大的损失。为了提高系统的伸缩能力与高可用能力,我们都不断的在努力消除系统单点瓶颈。如使用应用集群是为了解决服务层的单点问题,使用主从数据库是为了解决数据库层面的单点问题。
- 尽管我们使用微服务架构,很好的解决了服务治理与监控问题,使得少数服务器出现故障仍不影响整体服务质量。但是由于所有的设备都存放在同一个机房内部,对于机房级的故障是无法承受的,如机房断电、火灾、地震等,造成的后果是灾难性的。虽然机房内部很好的解决了单点故障,但是机房本身却是单点的。
- 为了提升机房级的容灾能力,业界多采用 “两地三中心” 方案。
两地三中心
- 顾名思义,两地指的是两个城市:同城,异地。三中心指的是三个数据中心:生产中心、同城容灾中心、异地容灾中心。
- 在同一个城市或者临近的城市建设两个相同的系统,双中心具备相当的业务处理能力,机房之间通过高速网络实时同步数据。
- 在异地建设灾备中心,通过异步传输的方式,将双机房的数据备份至异地灾备中心,以应对城市级别的灾难。
备份模式
- 由于金融行业对系统建设要求高,因此在早期绝大部分银行都采用“两地三中心”建设方案。在这种模式下,多个中心是主备关系,即只有生产中心对外提供服务,同城容灾中心是生产中心的备份,当生产中心无法提供服务时,将流量切换至同城容灾中心。当同城双机房都发生故障时,启用异地灾备中心。
- 这种模式建设方案简单,实际上是通过资源的堆砌与冗余来应对不确定事件的发生。但由于对灾难的响应和机房的切换周期非常长,无法实现业务的零中断,对设备资源的利用率低下,因此,近年来各个企业都开始寻求转变,将系统建设为双活,使同城双中心同时对外提供服务,节约成本,同时继续保留异地容灾中心。
双活模式
-
双活不仅仅是将流量切分至两个机房这么简单,更多的是要考虑如何能让用户的请求在一个机房中就能完成,避免跨机房调用带来的延时增加,从而影响客户体验。
-
因此,对于双活架构,要考虑以下几个方面的因素:
- 业务能否在一个机房内完成整个交易链路上所有处理;
- 应用程序如何进行双活;
- 中间件如何进行双活;
- 数据库能否双活,如何同步。
-
1.业务能否在一个机房内完成整个交易链路上所有处理
-
业务拆分微服务后,通常由多个服务协作共同完成一笔业务请求。以购买理财为例,请求链条为:互联网网关->理财渠道服务->理财系统->账务系统。如果这些服务部署在不同的机房,则每次请求都要进行跨机房的访问,必然会增加性能损耗,造成资源浪费。
-
2.应用程序如何进行双活
-
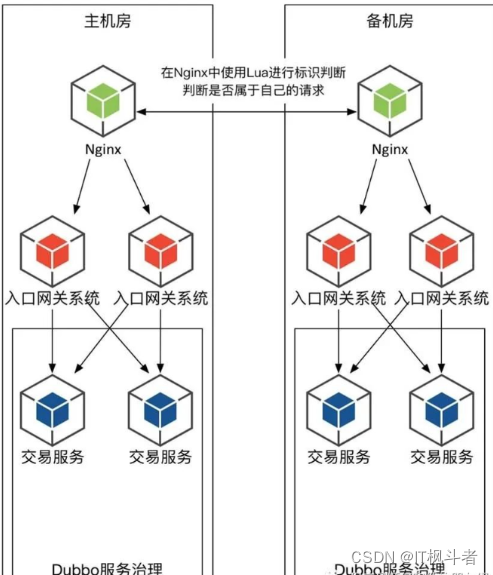
应用程序双活,主要需考虑的是业务请求是否是有状态的。如果是有状态的请求,则必须指定固定的机房来处理同一笔请求,如用户的理财数据在A机房,则应该由A机房来处理用户的购买请求。
-
为了达到上述要求,通常会在互联网网关(或者nginx)上,进行流量的分发,根据相应的规则,将请求分发到指定的机房处理。如下图:
-
-
3.中间件如何进行双活
-
对于常用的中间件,如redis、kafka、ZooKeeper等,需要考虑双机房如何进行数据同步。
-
以redis为例,官方并没有提供跨机房的主主同步机制。如果仅利用redis的主从数据同步机制的话,需要将主节点与从节点部署在不同的机房。当主节点所在机房出现故障时,从节点可以升级为主节点,应用可以持续对外提供服务。但这种模式下,若要写数据,则只能通过主节点写,写请求有一半还是会跨机房访问。
-
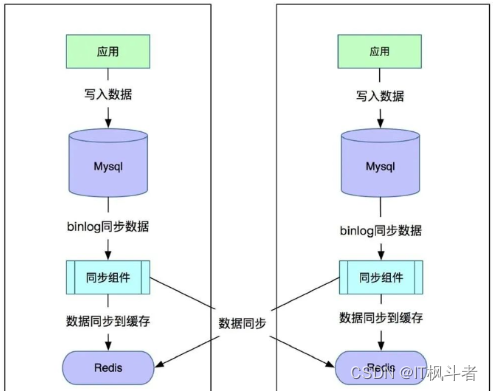
若要实现redis的主主同步,需自己研发相应的插件,例如可以通过订阅mysql的binlog日志来做缓存数据的同步。通过实现同步组件,监听mysql的binlog并解析,将数据同步到两个机房的redis集群中。如下图:
-
-
该方案看起来还不错,但是它具有以下弊端:
- 由于跨机房,数据同步会有几十到上百毫秒的延时。
- 同步组件将数据写入到本地redis和远程redis,由于没有事务的约束,不能保证两边都写成功,因此有可能会出现不一致。
- redis的数据可以同步,但数据的过期时间无法同步。
- redis具备5种数据结构,需要根据业务提前约定好使用哪种数据结构,业务侵入到了数据同步组件。
-
4.数据库能否双活,如何同步
-
应用的双活和中间件的双活,最终都依赖于数据如何存放。如果两个机房中各部署一个数据库,那么机房间的数据如何同步呢。
-
以mysql为例,业界最常用的做法就是利用binlog做数据同步,最具代表性的就是阿里开源的Canal+Otter数据同步方案。
-
Canal可以伪装成一个Mysql Slave,接收binlog文件,获取到Mysql Master的数据变更:
-
Otter可以将Canal获取的数据,同步到目标数据库
-
Canal+Otter不仅可以实现同构数据的同步,还能实现异构数据的同步,同时会简化压缩要传输的binlog,减少网络压力,传输速度更快。
小结
- 上面介绍了两地三中心的备份模式与双活模式,可以看到,这两种模式下,每个机房的数据量都是全量的,在某个机房故障时,另外一个机房会接管全部的流量。
- 然而,对于大的互联网公司来说,单个机房甚至两个机房都不能承载业务容量,需要更多的机房来共同对外提供服务,在这样的场景下,上述所说的双活方案就不太适用了。因此,支付宝等公司就提出了新的解决方案:单元化。
单元化
-
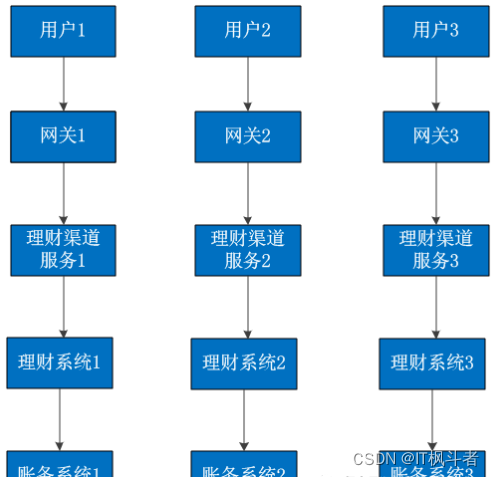
所谓单元化,就是将业务划分为一个个小的业务单元,每一个单元的功能完全相同,但只能处理一部分数据,所有单元的数据合并起来,才是完整的数据;麻雀虽小,五脏俱全,每个单元内部都能处理完整的业务流程。如下图:
-
-
单元化要求应用层也可以按照数据层的维度去分片,将整个请求收敛到一个单元内部完成,尽量不与别的单元交互。这样一个单元就是一个最小的逻辑单位,可以根据需要“搬迁”到不同的机房。在单元化架构下,机房可以横向扩展(增加或减少),而应用系统无需改造。
-
而要做到单元化,必须要满足以下要求:
- 业务必须是可分片的,如购买理财可根据客户号进行分片
- 单元内的业务是自包含的,调用尽量封闭
- 系统是面向逻辑分区的,而不是物理部署
-
为了实现单元化,需要由以下关键技术组件做支撑。
全局路由网关
- 由于实施单元化后,整个交易链路从前到后的分片规则都是一致的,因此需要在入口处识别用户请求的所属单元,直接将请求路由至目标单元处理。这就使得必须有一套机制或系统来专门完成在这项工作,而又因为是在网络入口处处理,因此需要一个全局路由网关。
- 此时,需要所有交易尽可能的带上分片键,以便全局路由网关判断当前交易属于哪个单元。然而实际应用过程中,并不是所有交易都能带上分片键,这种情况就需要应用跨单元交易转发组件来处理了。
应用跨单元交易转发
- 如上所述,当网关层无法识别交易所属单元时,就需要在业务层识别处理了。例如单元划分按用户uid分片,但在登录场景下,用户可能使用手机号登录,也可能使用身份证号登录,还有可能使用微信登录(此时使用的是unionid和openid),此时需要先按照请求信息查出uid,然后将交易转发至该uid所在单元处理。
- 此时肯定就有小伙伴们想,为什么应用不能直接跨单元访问数据库呢,还省去了应用转发处理的过程。主要原因:
- 当应用层直接跨单元访问数据库时,每个数据库都对应多个应用,然而数据库的连接数是非常宝贵的系统资源,不可能无限增长,这就导致当应用数量达到一定规模时,数据库连接数会被占满,此时应用将无法再进行横向扩容,业务将无法继续发展。因此不建议应用直接跨单元访问数据库,而是通过应用层直接的转发来处理,每个数据库只被本单元内的应用访问。当然,应用层的转发规则需要与全局路由网关的转发规则保持一致。
异构索引与分布式事务
- 上面所描述的登录过程中,在应用不能跨单元访问数据库时,是如何做到根据手机号、身份证号等信息查出用户的uid呢。这就需要异构索引来支持了。
- 异构索引即“按照不一样的结构再建一份索引”。如我们以uid存储用户信息,在分片时由于不知道手机号所属分片,无法直接使用手机号查询到用户信息,因此会再存储一份手机号到uid的映射关系,这个映射关系就是异构索引。通常为了提高性能,会使用redis或者es等中间件来存储异构索引。
- 当然,涉及到数据的多处存放,就会涉及到数据的一致性问题,就免不了要实现分布式事务。不仅多个单元之间要实现分布式事务,在数据库与异构索引之间也要使用分布式事务使其达到数据一致。关于分布式事务的详细概念及其实现方案,可参考文章《分布式事务的概念及实现方案》。
小结
- 通过单元化架构,每个单元内部都可以完整的完成业务流程,以尽可能避免跨单元的访问。通过全局路由网关、应用跨单元交易转发,可使用一致的单元划分规则,将交易转发至相应的单元处理。而在不带分片键的交易过程中,要找到目标单元,可通过异构索引实现。
多地多活
- 在实现单元化架构之后,此时系统是面向逻辑分区的,因此可将某个单元部署至任意数据中心,而应用无须改造。此时系统便实现了多地多活。
- 在实现多地多活后,需要注意的是,虽然系统是面向逻辑分区的,但是在容灾策略上还是要考虑部署位置,做好单元的数据备份工作。通常会将每个单元部署为2-3个备份,不同的备份部署在不同的机房,有一个主节点对外提供服务,在主节点故障时,可快速切换至备份节点,实现业务的零中断服务。