一,ORM查询的补充:
1,连接查询:
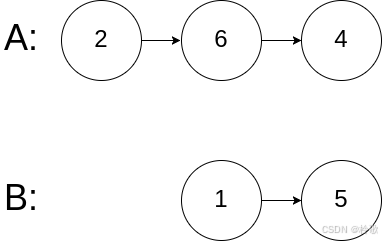
反向查询:
先介绍一下什么是正向查询,比如我们之前的数据表之间建立的一对多的关系,我们通过文章找到相应的作者是属于正向查询的(由多到一),而反向查询就恰恰相反,从一出发,找多。


注意反向查询的代码: article是我们的表名小写,后面跟_set.all是反向查询的固定写法。
articles = author.article_set.all()
2,聚合查询
聚合,就好比统计数目。比如说我们搜索一个作者名,它返还给我们它的作品,以及数量等种种聚合在一起的信息,所以比较重要,也是难点。


注意:Count也是个聚合函数,我们需要在导入Q函数的相同位置导入它,我们annotate函数查到的内容是这个:
![]()
for循环拿出来是这样:
 ,
,
但他不仅仅只是一个作者名,它更是一个容器,里面装着该作者的信息,所以我们可以调用;
3,条件判断查询:
条件比如>,<,>=,<=,等。
大于查询: ---gt
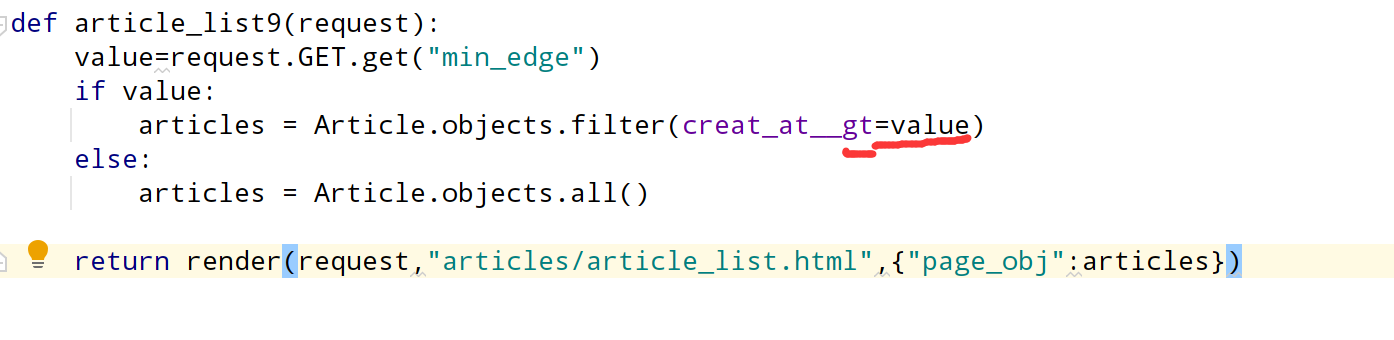
与之前的查找日期相比,就在后面加了一个gt,小于就是lt。后面加e是加上等于。当然我们也可以同时设置最大和最小边界值进行查找。
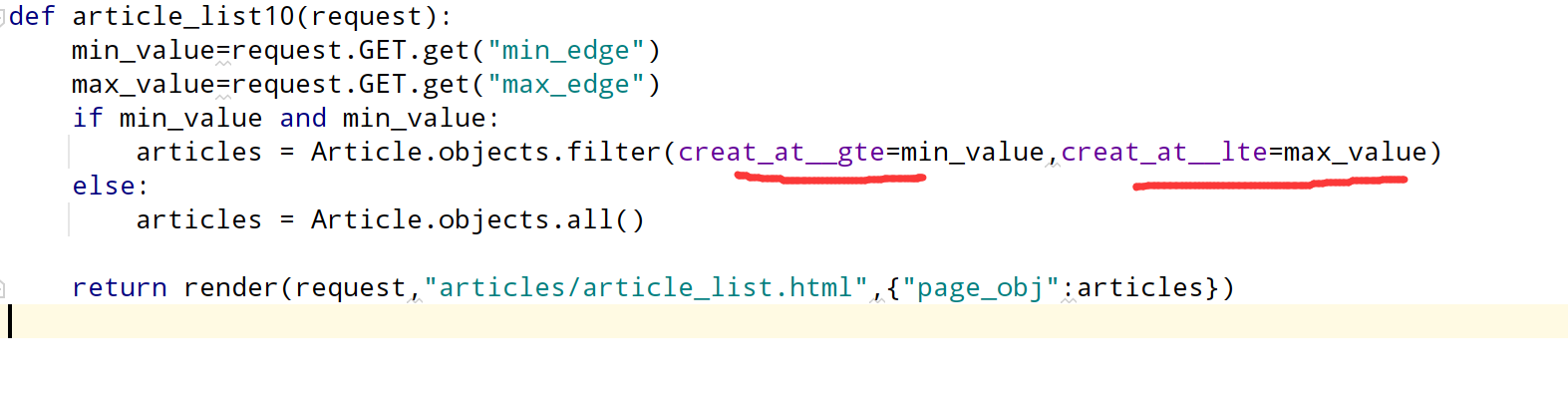
组合查询(范围查询):
![]()

相比之下就是多了一个creat_at.lte跟上最大值。
4,模糊查询
(1)包含查询 -----最普遍的查询
我们大多浏览器的查询都是该查询
区分大小写包含:
def article_list11(request):
query = request.GET.get("q")
if query:
articles = Article.objects.filter(title__contains = query)
# 或者先写articles = Article.objects.all()
# 然后if里面写articles = articles.filter(title__contains = query)也可以
else:
articles = Article.objects.all()
return render(request,"articles/article_list.html",{"page_obj":articles})

不区分大小写包含:
把title__contains = query改成title__icontains = query即可

首位包含:
把title__contains = query改成title__startwith = query即可首部查询

把title__contains = query改成title__endwith = query即可尾部查询

不匹配包含:
exclude:排除
def article_list13(request):
query = request.GET.get("q")
if query:
articles = Article.objects.exclude(title__icontains=query)
else:
articles = Article.objects.all()
return render(request,"articles/article_list.html",{"page_obj":articles})