今天继续给大家介绍Python爬虫相关知识,本文主要内容是Python爬虫编写乱码问题、验证码登录问题和IP代理问题解决。
一、乱码问题解决
我们在使用Python爬虫爬取网页信息时,有时会遇上乱码问题(特别是爬取中文网页信息时),如果出现了乱码问题,那么解决方法大致如下:
第一种方法是设置响应数据编码,相关代码如下所示:
response=requests.get(url)
reponse.encoding='utf-8'
page_text=response.text
另一种方法是对出现乱码的字符串进行处理,相关代码如下所示:
name=tree.xpath('……')
name=name.encode('【乱码变量本来的编码】').decode('Python设置的编码格式')
在上述代码中,我们在获取到了指定内容后,是一个字符串形式的变量。我们对该变量进行encode()编码处理后,就把一个字符串类型的变量转化为一个字节流类型的变量,然后把一个字节流类型的变量进行解码后,就又恢复为一个字符串类型的变量。我们使用该变量原有的编码格式进行编码,使用Python自带的编码格式进行解码,就可以解决乱码问题了。
二、验证码登录问题解决
有时,我们在使用Python爬虫模拟登录时,会遇上需要我们输入验证码的情况。验证码是进行人机识别的有效步骤,但是通过一定的步骤,我们可以编写程序来实现这一验证操作。现在网上有很多验证码在线识别平台,可以帮助我们识别各种种类的验证码。例如:云码,URL为:https://zhuce.jfbym.com/test/
可以识别的验证码类型如下所示:
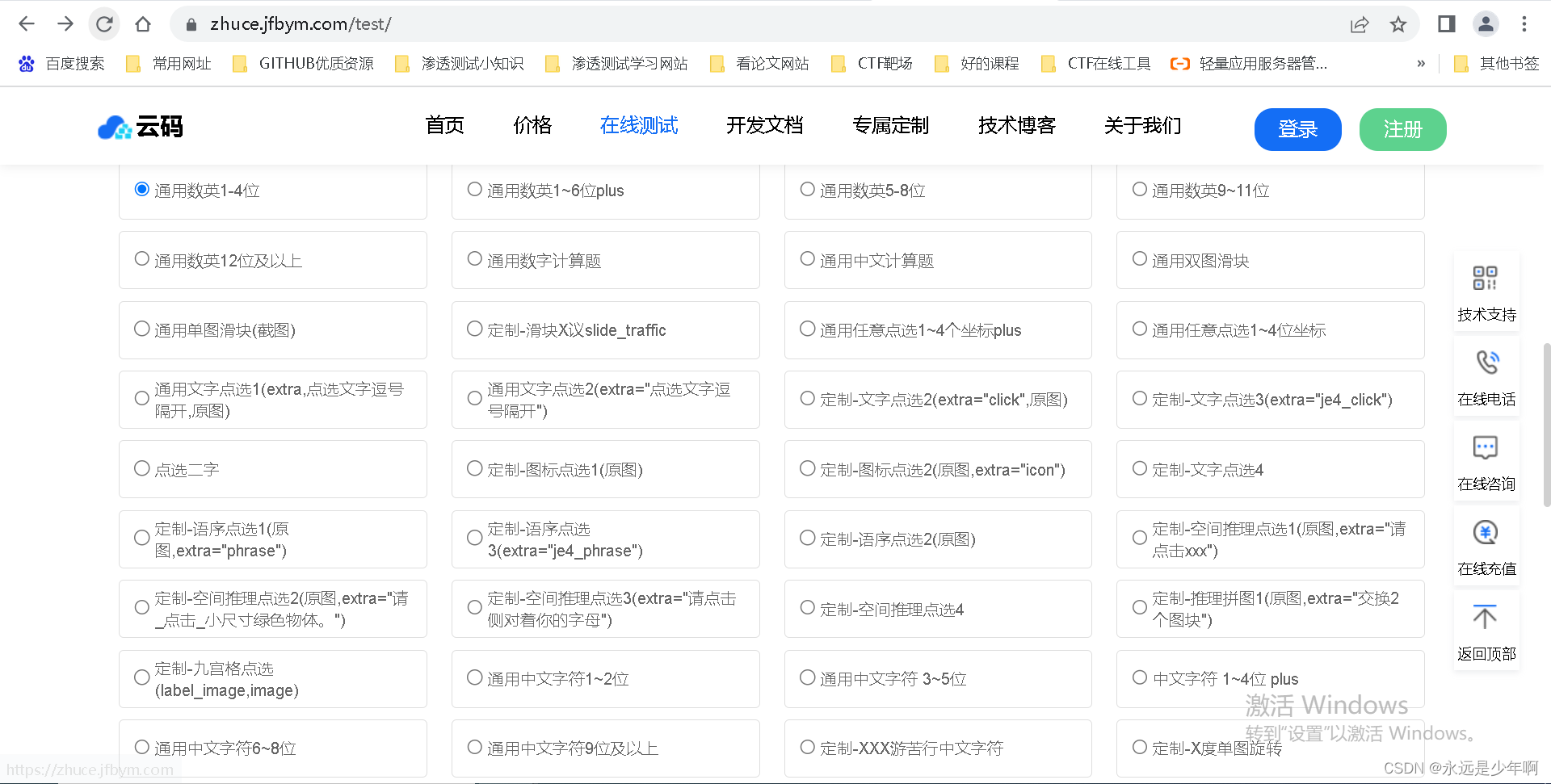
我们可以登录这样的平台,并注册该平台账号(这样的平台很多都是要花钱的,但是如果识别量不大的话,花的钱不多),这样就可以在Python爬虫登录时,将验证码交给该网页处理,然后该网页会把处理结果反馈,我们就可以使用这种反馈的结果来进行输入或其他处理了。
三、IP代理问题解决
我们在使用爬虫爬取网页时,如果爬取速度过快,容易被网页封禁IP,这是各种网页常用的反爬机制(也是防CC流量攻击的一种措施)。针对这种机制,我们以方便可以设置访问的速度,Python在引入time库后,调用sleep()函数,在爬取操作后人为延时一段时间,避免访问速度过快,也可以使用IP代理技术。
IP代理类似一个“中转站”,可以隐藏自身的真实IP,但是不同的代理有不同的匿名度,匿名度可以粗略的可以分为四类——透明代理、匿名代理、混淆代理和高匿代理。这四类代理主要区分在HTTP访问中,区别在于REMOTE_ADDR、HTTP_VIA和HTTP_X_FORWARDED_FOR三个HTTP头字段。
这四种代理方式的三个HTTP头字段区别如下表所示:
| 代理方式\HTTP字段 | REMOTE_ADDR | HTTP_VIA | HTTP_X_FORWARDED_FOR |
|---|---|---|---|
| 透明代理 | 代理IP地址 | 代理IP地址 | 真实IP地址 |
| 匿名代理 | 代理IP地址 | 代理IP地址 | 代理IP地址 |
| 混淆代理 | 代理IP地址 | 代理IP地址 | 随机IP地址 |
| 高匿代理 | 代理IP地址 | 无该字段 | 无该字段 |
简单来看,如果使用了透明代理,那么服务器明确知道了访问的数据包使用了代理,并且也知道了请求者的真实IP地址。如果使用了匿名代理,那么服务器知道了访问的数据包使用了代理,但是不知道请求者的真实IP地址。如果使用了混淆代理,那么服务器知道访问的数据包使用了代理,但是知道的请求者的真实IP地址是错误的。如果使用了高匿代理,那么攻击者就不知道请求者使用了代理。
如果我们申请了一个代理池的访问接口,那么我们在使用该代理时,应当在requests.get()方法中,设置proxies字段,来指定代理IP和端口。该字段是一个字典变量,字典的键是代理采用的协议,可以是http或https,该键对应的值是代理的IP和端口。例如:
response=requests.get(url,headers,proxies={"https":"X.X.X.X:X"})
这样,Python就会使用代理对指定网页进行爬取了。
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200