1. 问题引入,相较于有序链表我们为什么需要跳表?
1.1 首先我们需要了解什么是有序链表
如图:
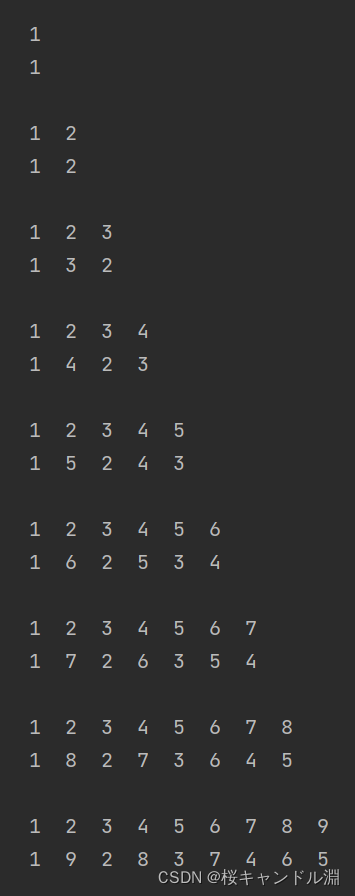
每个链表存在一个指向下一节点的指针,如果我们要对其任一节点进行增删改,都需要先使用迭代器进行查询,找到指定节点进行修改,复杂度较高。
1.2 因此我们可以对有序列表进行分层

如果next节点大于我们查找的值或者指向null那么就需要从当前节点下降一层,继续向后查找,如此一来可以极大提高查找效率。
2. 跳表性质
- 跳表由很多层组成。
- 跳表有一个头节点(header),头结点中有一个64层结构,每层结构包含指向本层下个节点的指针,只想本层下个节点中间跨越的节点个数称为本层跨度(span)。
- 除头节点外,层数最多的节点的层高为跳表的高度(level)。
- 每层都是一个有序链表,数据递增。
- 除头节点外,,一个元素若在上层出现那么一定会在下层出现。
- 每层最后一定指向null,表示本层有序链表结束。
- 跳表存在一个tail指针,指向跳表最后一个节点。
- 最底层的有序链表包含所有节点,最底层节点个数为跳表长度(不包括头节点)
- 每个节点都包含了一个后退指针,头节点和第一个结点指向NULL;其他节点指向最底层前一个结点。
3. 跳表的创建实现
1. 创建跳表节点
查看redis源码可知我们需要先创建一个节点,跳跃表节点存在如下参数:
- ele: 用于存储字符串类型数据
- score: 用于存储排序的分值
- backward:后退指针
- level:柔性数组,包含:
- forward: 指向本层下一个节点,前进指针
- span: 跨度,用于增删改找寻修改节点位置
我们在java中可以使用Object 对象obj来存储ele这个对象
/**
* 定义节点内容
*/
private static class ZSkipListNode implements SkipList.Node{
// 存储数据对象
Object obj;
// 用于存储排序的分值
double score;
// 后退指针
ZSkipListNode backward;
@Override
public double getScore() {
return score;
}
@Override
public Object getObject() {
return obj;
}2. 创建跳跃表结构
在c语言底层跳表结构是通过一个叫 zskiplist 结构体来实现的,用来管理节点。
包含以下属性:
- header:指向跳表头节点。
- tail:指向尾节点(在最底层)
- length:跳表长度
- level:跳表高度
java实现如下:
/**
* 1. level 是一个柔性数组,每个节点的数组长度不一样,
* 在生成跳跃表节点时,随机生成一个 1 ~ 64 的值,值越大出现概率越低。
* 2. level数组包含两个元素:
* a. forward 前进指针
* 指向本层下一个节点,最终指向 null
* b. span 跨度
* 指向的节点与本节点之间的元素个数
*/
static class ZSkipListLevel{
// 前进指针
ZSkipListNode forward;
// 跨度
int span;
}
// 定义层
ZSkipListLevel[] level;
// 初始化构造器
public ZSkipListNode(int level, double score, Object obj){
// 设置层数大小
ZSkipListLevel[] skipListLevels = new ZSkipListLevel[level];
this.level = skipListLevels;
// 设置属性
this.score = score;
this.obj = obj;
} /**
* 1. 定义表头节点和尾节点
* 2. 注意头节点中不存储仍和 member和 score值,obj为 null,score为 0; 也不计入跳表总长度。
*/
ZSkipListNode header;
ZSkipListNode tail;
// 定义表节点数量(注意:不包括头节点)
long length;
// 表示跳表高度
int level;
// 创建跳表
public ZSkipList() {
// 设置高度和起始层数
this.length = 0;
this.level = 1;
// 创建初始化具有64层的头节点
this.header = new ZSkipListNode(ZSKIPLIST_MAXLEVEL, 0, null);
// 头节点每层都有一个level软列表
// 头节点每层forward指向null
// 头节点层数是0
for (int i = 0; i < ZSKIPLIST_MAXLEVEL; i++){
this.header.level[i] = new ZSkipListNode.ZSkipListLevel();
this.header.level[i].forward = null;
this.header.level[i].span = 0;
}
// 回调节点和尾节点都为null
this.header.backward = null;
this.tail = null;
}4. 增删改查方法
然后我们就需要进行增删改查,但是由于查是增删改基础所以就不单独展示,而删除只是对增改方法进行一定的简化改写,所以下面只展示增改加方法。
根据redis源码,我们可以看到增改方法由两个很重要的数组分别是:
- update[]:用于记录需要被跟新/插入节点前一个几点。
- rank[]:用于记录当前层从header头节点到update[i]节点的跨度。
所以可以简单通过java来实现一下找寻节点的操作:
/**
* 1. 为了找到要更新的节点,我们需要以下两个长度为64的数组来辅助操作
* a. update[]: 插入节点时,需要更新被插入节点每层的前一个节点。
* 由于每层更新结点不一样,所以需要将每层需要更新的节点记录在update[i]中
* b. rank[]: 记录当前层从header节点到update[i]节点所经历的步长,
* 更新 update[i]的span和设置新插入节点的span时使用
* 2.
* @param score
* @param obj
* @return
*/
@Override
public Node insert(double score, Object obj) {
ZSkipListNode[] update = new ZSkipListNode[ZSKIPLIST_MAXLEVEL];
int[] rank = new int[ZSKIPLIST_MAXLEVEL];
// 定义一个节点
ZSkipListNode x;
int i, level;
// 在各层查找节点插入位置
x = this.header;
for (i = this.level - 1; i>= 0; i--){
// 如果 i 不是 zsl->level-1 层
// 那么 i 层的起始 rank 值为 i+1 层的rank值
// 各层rank的rank值一层层累积
// 最终 rank[0] 的值加一就是新节点的前置节点的排位
// rank[0] 会成为计算span和rank的值基础
rank[i] = i == (this.level - 1) ? 0 : rank[i + 1];
// 沿着前进指针遍历跳跃表
// 当前分支小于目标分值或者分值相同但是对象字典小于目标
while (x.level[i].forward != null &&
(x.level[i].forward.score < score ||
(x.level[i].forward.score == score &&
compareStringObjects(x.level[i].forward.obj, obj) < 0))){
// 记录跨越节点数
rank[i] += x.level[i].span;
// 移动到下一节点指针
x = x.level[i].forward;
}
// 记录将要和新节点相连的节点
// 新节点在i层,指向该节点第i层前进节点
update[i] = x;
}1. 调整跳表高度
由于我们插入新节点,高度是随机的,所以我们需要新增高度,并且进行一些记录参数的调整:
level = randomLevel();
// 如果新节点的层数比表中其他节点的层数都要大
// 那么初始化header节点中未使用的这层,并将他记录到 update 数组中
// 将来也指向新节点
if (level > this.level){
// 初始化未使用层
for (i = this.level; i < level; i++){
rank[i] = 0;
update[i] = this.header;
update[i].level[i].span = (int) this.length;
}
this.level = level;
}2. 插入节点
由于我们已经做完了准备工作,接下来就可以对节点进行一个简单的插入就🆗了:
x = new ZSkipListNode(level, score, obj);
// 将前面记录的指针指向新节点,并做对应设置
for (i = 0; i < level; i++){
x.level[i] = new ZSkipListNode.ZSkipListLevel();
//设置新节点的 forward 指针
x.level[i].forward = update[i].level[i].forward;
// 将沿途记录各个节点的 forward 指针指向新节点
update[i].level[i].forward = x;
// 计算新节点跨越节点数量
x.level[i].span = update[i].level[i].span - (rank[0] - rank[i]);
// 更新新节点插入之后,沿途节点的span值
// 其中的 +1 计算的是新节点
update[i].level[i].span = (rank[0] - rank[i]) + 1;
}
// 由于新增了节点,所以未接触节点的跨度也要增加1,这些节点直接从表头指向新节点
for (i = level; i < this.level; i++){
update[i].level[i].span++;
}3. 接下来我们在调整后退指针就完成了增改方法:
// 调整新节点的后退指针
x.backward = (update[0] == this.header) ? null : update[0];
// 调整第1层
if (x.level[0].forward != null){
x.level[0].forward.backward = x;
}else {
this.tail = x;
}感悟:
由于java没有结构体,所以许多结构定义采用interface进行的,然后通过实现接口,以达到结构体的实现。redis源码给作者带来了极大的震撼,揣摩Sanfilippo的想法然后豁然开朗,比反复刷springboot+mysql+vue这种商城项目框架有趣多了。写完代码后还是忍不住赞叹,卧槽牛逼!打到余麻子!Sanfilippo才是神。(狗头)



![[BJDCTF 2020]Easy](https://img-blog.csdnimg.cn/direct/26bb607deff243c2b5c47ac06d6b9fb1.png)





![[UI5 常用控件] 03.Icon, Avatar,Image](https://img-blog.csdnimg.cn/direct/54738f73de1744bc99b1e9a3dc79b489.png)