xml
1.概述【理解】
-
万维网联盟(W3C)
万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。
建立者: Tim Berners-Lee (蒂姆·伯纳斯·李)。
是Web技术领域最具权威和影响力的国际中立性技术标准机构。
到目前为止,W3C已发布了200多项影响深远的Web技术标准及实施指南,-
如广为业界采用的超文本标记语言HTML(标准通用标记语言下的一个应用)、
-
可扩展标记语言XML(标准通用标记语言下的一个子集)
-
以及帮助残障人士有效获得Web信息的无障碍指南(WCAG)等
-

-
xml概述
XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言
标记语言: 通过标签来描述数据的一门语言(标签有时我们也将其称之为元素)
可扩展:标签的名字是可以自定义的,XML文件是由很多标签组成的,而标签名是可以自定义的 -
作用
- 用于进行存储数据和传输数据
- 作为软件的配置文件
-
作为配置文件的优势
- 可读性好
- 可维护性高
2.标签的规则【应用】
-
标签由一对尖括号和合法标识符组成
<student> -
标签必须成对出现
<student> </student> 前边的是开始标签,后边的是结束标签 -
特殊的标签可以不成对,但是必须有结束标记
<address/> -
标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来
<student id="1"> </student> -
标签需要正确的嵌套
这是正确的: <student id="1"> <name>张三</name> </student> 这是错误的: <student id="1"><name>张三</student></name>
3.语法规则【应用】
-
语法规则
-
XML文件的后缀名为:xml
-
文档声明必须是第一行第一列
<?xml version=“1.0” encoding=“UTF-8” standalone=“yes”?>version:该属性是必须存在的
encoding:该属性不是必须的 打开当前xml文件的时候应该是使用什么字符编码表(一般取值都是UTF-8)
standalone: 该属性不是必须的,描述XML文件是否依赖其他的xml文件,取值为yes/no
-
必须存在一个根标签,有且只能有一个
-
XML文件中可以定义注释信息
-
XML文件中可以存在以下特殊字符
< < 小于 > > 大于 & & 和号 ' ' 单引号 " " 引号 -
XML文件中可以存在CDATA区
<![CDATA[ …内容… ]]>
-
代码
<?xml version="1.0" encoding="UTF-8" ?>
<!--注释的内容-->
<!--本xml文件用来描述多个学生信息-->
<students>
<!--第一个学生信息-->
<student id="1">
<name>张三</name>
<age>23</age>
<info>学生< >>>>>>>>>>>的信息</info>
<message> <![CDATA[内容 <<<<<< >>>>>> ]]]></message>
</student>
<!--第二个学生信息-->
<student id="2">
<name>李四</name>
<age>24</age>
</student>
</students>
4.xml解析【应用】
-
概述
xml解析就是从xml中获取到数据
-
常见的解析思想
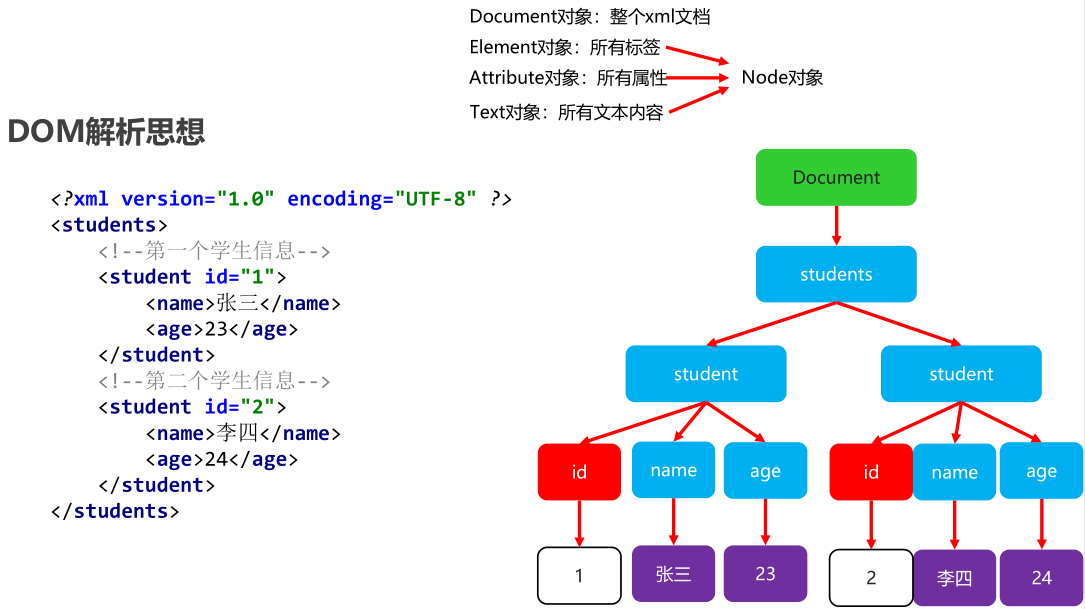
DOM(Document Object Model)文档对象模型:就是把文档的各个组成部分看做成对应的对象。
会把xml文件全部加载到内存,在内存中形成一个树形结构,再获取对应的值
-
常见的解析工具
- JAXP: SUN公司提供的一套XML的解析的API
- JDOM: 开源组织提供了一套XML的解析的API-jdom
- DOM4J: 开源组织提供了一套XML的解析的API-dom4j,全称:Dom For Java
- Jsoup:功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便(项目中讲解)
-
两种基本的xml解析方式:
- DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象。
- SAX:是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都触发对应的事件。(了解)
- PULL:Android内置的XML解析方式,类似SAX。(了解)
-
解析的准备工作
-
可以通过网站:https://dom4j.github.io/ 去下载dom4j
-
将dom4j-1.6.1.zip解压,找到里面的dom4j-1.6.1.jar
-
在idea中当前模块下新建一个libs文件夹,将jar包复制到文件夹中
-
选中jar包 -> 右键 -> 选择add as library即可
-
-
DOM4j的API介绍
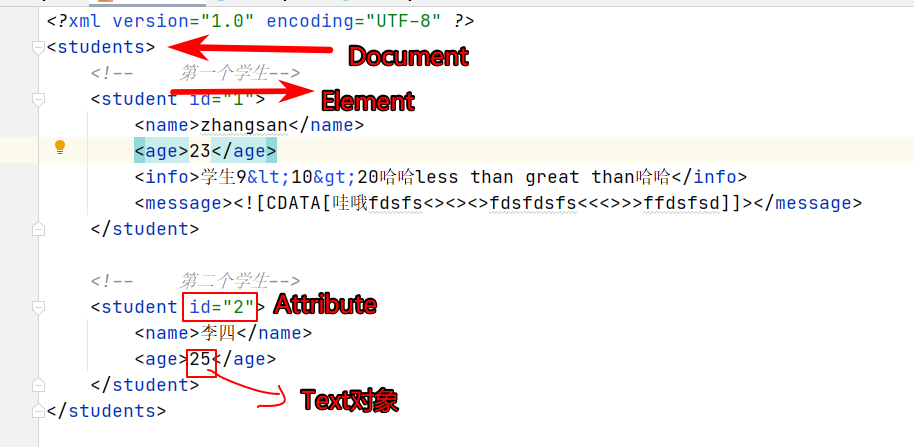
解析过程中必须记住的几个单词:Document文档 Element标签 Attribute属性
- SaxReader对象
返回值 方法名 说明 SAXReader new SAXReader() 构造器 Document Document read(String url) 加载执行xml文档 - Document对象
返回值 方法名 说明 Element getRootElement() 获得根元素 - Element对象
返回值 方法名 说明 List elements([String ele] ) 获得指定名称的所有子元素。可以不指定名称 Element element([String ele]) 获得指定名称第一个子元素。可以不指定名称 String getName() 获得当前元素的元素名 String attributeValue(String attrName) 获得指定属性名的属性值 String elementText(Sting ele) 获得指定名称子元素的文本值 String getText() 获得当前元素的文本内容
练习需求
- 解析提供好的xml文件
- 将解析到的数据封装到学生对象中
- 并将学生对象存储到ArrayList集合中
- 遍历集合
代码
<?xml version="1.0" encoding="UTF-8" ?>
<!--注释的内容-->
<!--本xml文件用来描述多个学生信息-->
<students>
<!--第一个学生信息-->
<student id="1">
<name>张三</name>
<age>23</age>
</student>
<!--第二个学生信息-->
<student id="2">
<name>李四</name>
<age>24</age>
</student>
</students>
// 上边是已经准备好的student.xml文件
public class Student {
private String id;
private String name;
private int age;
public Student() {
}
public Student(String id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* 利用dom4j解析xml文件
*/
public class XmlParse {
public static void main(String[] args) throws DocumentException {
//1.获取一个解析器对象
SAXReader saxReader = new SAXReader();
//2.利用解析器把xml文件加载到内存中,并返回一个文档对象
Document document = saxReader.read(new File("myxml\\xml\\student.xml"));
//3.获取到根标签
Element rootElement = document.getRootElement();
//4.通过根标签来获取student标签
//elements():可以获取调用者所有的子标签.会把这些子标签放到一个集合中返回.
//elements("标签名"):可以获取调用者所有的指定的子标签,会把这些子标签放到一个集合中并返回
//List list = rootElement.elements();
List<Element> studentElements = rootElement.elements("student");
//System.out.println(list.size());
//用来装学生对象
ArrayList<Student> list = new ArrayList<>();
//5.遍历集合,得到每一个student标签
for (Element element : studentElements) {
//element依次表示每一个student标签
//获取id这个属性
Attribute attribute = element.attribute("id");
//获取id的属性值
String id = attribute.getValue();
//获取name标签
//element("标签名"):获取调用者指定的子标签
Element nameElement = element.element("name");
//获取这个标签的标签体内容
String name = nameElement.getText();
//获取age标签
Element ageElement = element.element("age");
//获取age标签的标签体内容
String age = ageElement.getText();
// System.out.println(id);
// System.out.println(name);
// System.out.println(age);
Student s = new Student(id,name,Integer.parseInt(age));
list.add(s);
}
//遍历操作
for (Student student : list) {
System.out.println(student);
}
}
}
5.DTD约束【理解】
-
什么是约束
用来限定xml文件中可使用的标签以及属性
-
约束的分类
- DTD
- schema
-
编写DTD约束
-
步骤
-
创建一个文件,这个文件的后缀名为.dtd
-
看xml文件中使用了哪些元素
<!ELEMENT> 可以定义元素 -
判断元素是简单元素还是复杂元素
简单元素:没有子元素。
复杂元素:有子元素的元素;
-
-
代码实现
<!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)>
-
-
引入DTD约束(会根据约束 写正确的xml文档)
-
引入DTD约束的三种方法
-
引入本地dtd
-
在xml文件内部引入
-
引入网络dtd
-
-
代码实现
-
引入本地DTD约束
// 这是persondtd.dtd文件中的内容,已经提前写好 <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> // 在person1.xml文件中引入persondtd.dtd约束 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons SYSTEM 'persondtd.dtd'> <persons> <person> <name>张三</name> <age>23</age> </person> </persons> -
在xml文件内部引入
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons [ <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> <persons> <person> <name>张三</name> <age>23</age> </person> </persons> -
引入网络dtd
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons PUBLIC "dtd文件的名称" "dtd文档的URL"> <persons> <person> <name>张三</name> <age>23</age> </person> </persons>
-
-
-
DTD语法
-
定义元素
定义一个元素的格式为:<!ELEMENT 元素名 元素类型>
简单元素: EMPTY: 表示标签体为空
ANY: 表示标签体可以为空也可以不为空
PCDATA: 表示该元素的内容部分为字符串
复杂元素:
直接写子元素名称. 多个子元素可以使用",“或者”|"隔开;
","表示定义子元素的顺序 ; “|”: 表示子元素只能出现任意一个
"?"零次或一次, "+"一次或多次, "*"零次或多次;如果不写则表示出现一次

-
-
定义属性
格式
定义一个属性的格式为:<!ATTLIST 元素名称 属性名称 属性的类型 属性的约束>
属性的类型:
CDATA类型:普通的字符串属性的约束:
// #REQUIRED: 必须的
// #IMPLIED: 属性不是必需的
// #FIXED value:属性值是固定的
代码
<!ELEMENT persons (person+)>
<!ELEMENT person (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ATTLIST person id CDATA #REQUIRED>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE persons SYSTEM 'persondtd.dtd'>
<persons>
<person id="001">
<name>张三</name>
<age>23</age>
</person>
<person id = "002">
<name>张三</name>
<age>23</age>
</person>
</persons>
6.schema约束【理解】
-
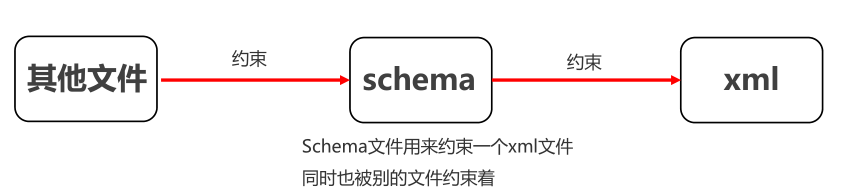
schema和dtd的区别
- schema约束文件也是一个xml文件,符合xml的语法,这个文件的后缀名.xsd
- 一个xml中可以引用多个schema约束文件,多个schema使用名称空间区分(名称空间类似于java包名)
- dtd里面元素类型的取值比较单一常见的是PCDATA类型,但是在schema里面可以支持很多个数据类型
- schema 语法更加的复杂
-
编写schema约束
-
步骤
1,创建一个文件,这个文件的后缀名为.xsd。
2,定义文档声明
3,schema文件的根标签为:
4,在中定义属性:
xmlns=http://www.w3.org/2001/XMLSchema
5,在中定义属性 :
targetNamespace =唯一的url地址,指定当前这个schema文件的名称空间。
6,在中定义属性 :
elementFormDefault="qualified“,表示当前schema文件是一个质量良好的文件。
7,通过element定义元素
8,判断当前元素是简单元素还是复杂元素

-
代码
<?xml version="1.0" encoding="UTF-8" ?>
<schema
xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itheima.cn/javase"
elementFormDefault="qualified"
>
<!--定义persons复杂元素-->
<element name="persons">
<complexType>
<sequence>
<!--定义person复杂元素-->
<element name = "person">
<complexType>
<sequence>
<!--定义name和age简单元素-->
<element name = "name" type = "string"></element>
<element name = "age" type = "string"></element>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
-
引入schema约束
-
步骤
1,在根标签上定义属性xmlns=“http://www.w3.org/2001/XMLSchema-instance”
2,通过xmlns引入约束文件的名称空间
3,给某一个xmlns属性添加一个标识,用于区分不同的名称空间
格式为: xmlns:标识=“名称空间地址” ,标识可以是任意的,但是一般取值都是xsi
4,通过xsi:schemaLocation指定名称空间所对应的约束文件路径
格式为:xsi:schemaLocation = "名称空间url 文件路径“
-
代码
<?xml version="1.0" encoding="UTF-8" ?>
<persons
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itheima.cn/javase"
xsi:schemaLocation="http://www.itheima.cn/javase person.xsd"
>
<person>
<name>张三</name>
<age>23</age>
</person>
</persons>
- schema约束定义属性
代码
<?xml version="1.0" encoding="UTF-8" ?>
<schema
xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itheima.cn/javase"
elementFormDefault="qualified"
>
<!--定义persons复杂元素-->
<element name="persons">
<complexType>
<sequence>
<!--定义person复杂元素-->
<element name = "person">
<complexType>
<sequence>
<!--定义name和age简单元素-->
<element name = "name" type = "string"></element>
<element name = "age" type = "string"></element>
</sequence>
<!--定义属性,required( 必须的)/optional( 可选的)-->
<attribute name="id" type="string" use="required"></attribute>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
<?xml version="1.0" encoding="UTF-8" ?>
<persons
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itheima.cn/javase"
xsi:schemaLocation="http://www.itheima.cn/javase person.xsd"
>
<person id="001">
<name>张三</name>
<age>23</age>
</person>
</persons>
框架中会给出如何引入约束,我们会引入然后按规则写xml
单元测试
1概述【理解】
JUnit是一个 Java 编程语言的单元测试工具。JUnit 是一个非常重要的测试工具
2特点【理解】
- JUnit是一个开放源代码的测试工具。
- 提供注解来识别测试方法。
- JUnit测试可以让你编写代码更快,并能提高质量。
- JUnit优雅简洁。没那么复杂,花费时间较少。
- JUnit在一个条中显示进度。如果运行良好则是绿色;如果运行失败,则变成红色。
3使用步骤【应用】
-
使用步骤
- 将junit的jar包导入到工程中
- 编写测试方法该测试方法必须是公共的无参数无返回值的非静态方法
- 在测试方法上使用@Test注解标注该方法是一个测试方法
- 选中测试方法右键通过junit运行该方法
-
代码示例
public class JunitDemo1 { @Test public void add() { System.out.println(2 / 0); int a = 10; int b = 20; int sum = a + b; System.out.println(sum); } }
4相关注解【应用】
-
注解说明
注解 含义 @Test 表示测试该方法 @Before 在测试的方法前运行 @After 在测试的方法后运行
代码
public class JunitDemo2 {
@Before
public void before() {
// 在执行测试代码之前执行,一般用于初始化操作
System.out.println("before");
}
@Test
public void test() {
// 要执行的测试代码
System.out.println("test");
}
@After
public void after() {
// 在执行测试代码之后执行,一般用于释放资源
System.out.println("after");
}
}
断言
-
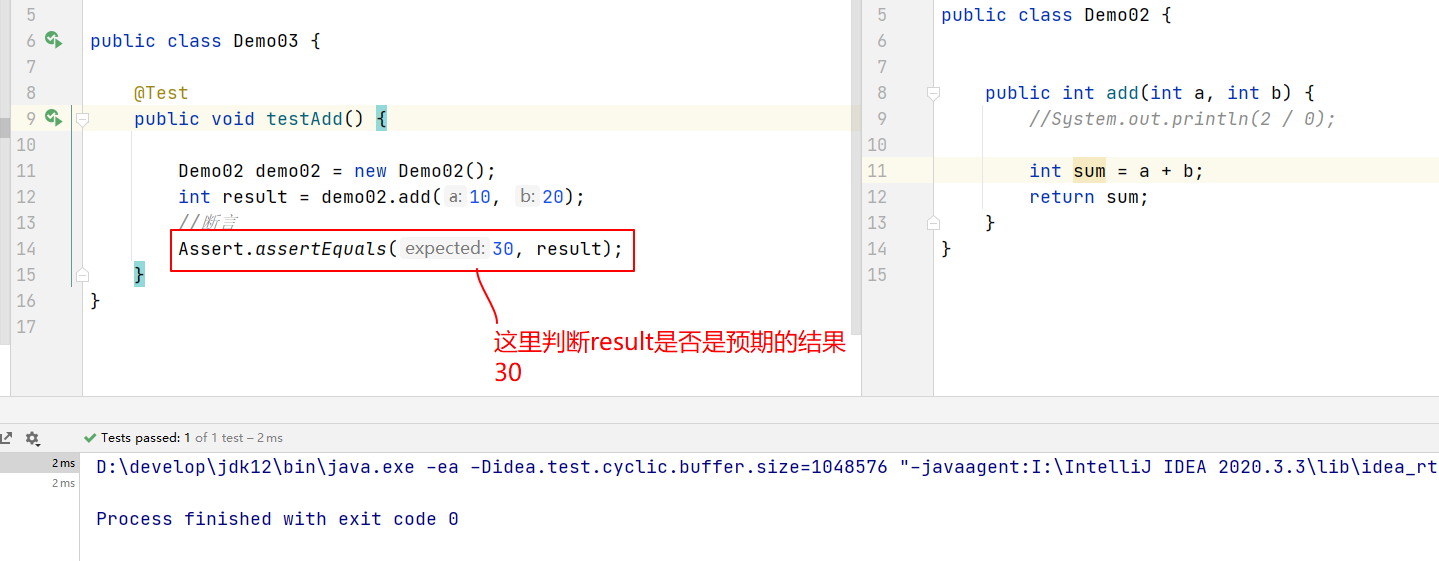
Assert.assertEquals(); -
成功的结果
- 失败的结果
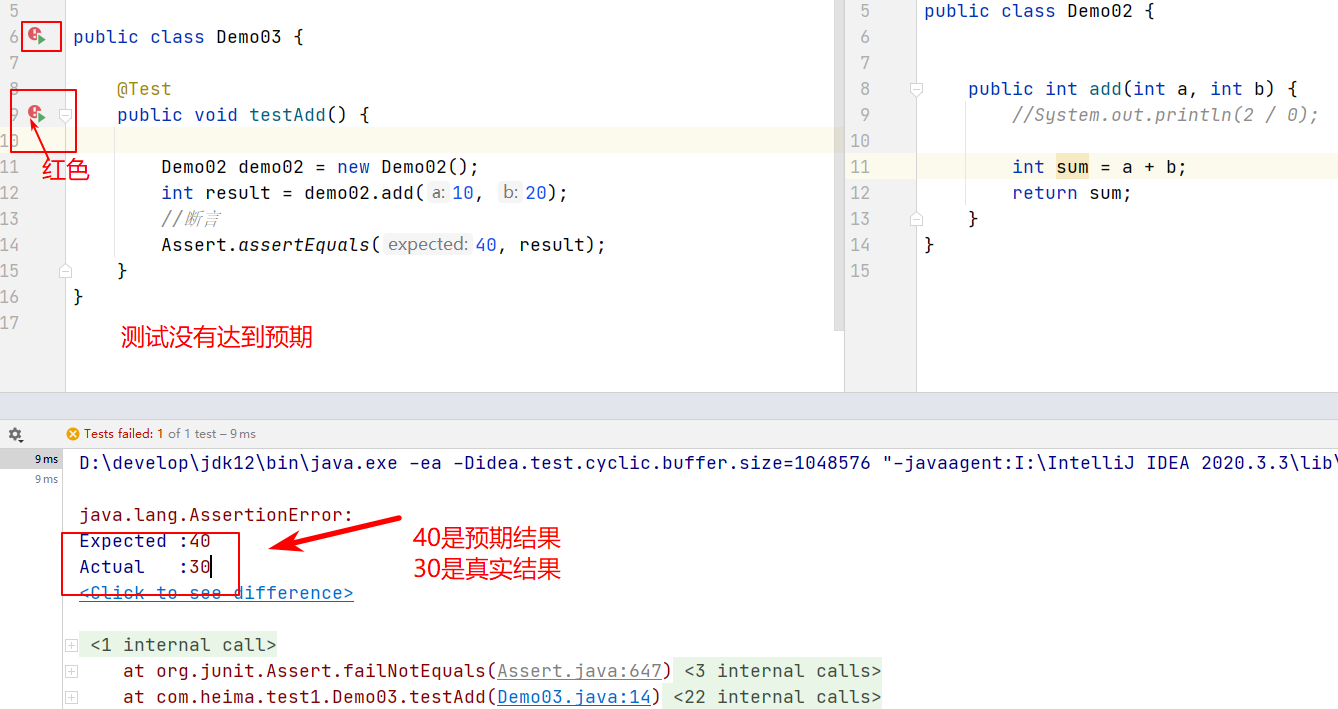
注解
1概述【理解】
-
概述
对我们的程序进行标注和解释
-
注解和注释的区别
- 注释: 给程序员看的
- 注解: 给编译器看的
-
使用注解进行配置配置的优势
代码更加简洁,方便
2自定义注解【理解】
-
格式
public @interface 注解名称 {
public 属性类型 属性名() default 默认值 ;
}
-
属性类型
- 基本数据类型
- String
- Class
- 注解
- 枚举
- 以上类型的一维数组
-
代码演示
public @interface Anno2 { } public enum Season { SPRING,SUMMER,AUTUMN,WINTER; } public @interface Anno1 { //定义一个基本类型的属性 int a () default 23; //定义一个String类型的属性 public String name() default "itheima"; //定义一个Class类型的属性 public Class clazz() default Anno2.class; //定义一个注解类型的属性 public Anno2 anno() default @Anno2; //定义一个枚举类型的属性 public Season season() default Season.SPRING; //以上类型的一维数组 //int数组 public int[] arr() default {1,2,3,4,5}; //枚举数组 public Season[] seasons() default {Season.SPRING,Season.SUMMER}; //value。后期我们在使用注解的时候,如果我们只需要给注解的value属性赋值。 //那么value就可以省略 public String value(); } //在使用注解的时候如果注解里面的属性没有指定默认值。 //那么我们就需要手动给出注解属性的设置值。 //@Anno1(name = "itheima") @Anno1("abc") public class AnnoDemo { } -
注意
如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可
3元注解【理解】
-
概述
元注解就是描述注解的注解
-
元注解介绍
元注解名 说明 @Target 指定了注解能在哪里使用 @Retention 可以理解为保留时间(生命周期) @Inherited 表示修饰的自定义注解可以被子类继承 @Documented 表示该自定义注解,会出现在API文档里面。 -
Target取值
@Target({ElementType.FIELD, 成员变量 ElementType.METHOD, 成员方法 ElementType.TYPE, 类 ElementType.CONSTRUCTOR, 构造方法 ElementType.LOCAL_VARIABLE, 局部变量 ElementType.PARAMETER}) 方法的参数 -
RetentionPolicy
1、RetentionPolicy.SOURCE:注解只保留在源文件,当Java文件编译成class文件的时候,注解被遗弃;
2、RetentionPolicy.CLASS:注解被保留到class文件,但jvm加载class文件时候被遗弃,这是默认的生命周期;
3、RetentionPolicy.RUNTIME:注解不仅被保存到class文件中,jvm加载class文件之后,仍然存在; -
示例代码
@Target({ElementType.FIELD,ElementType.TYPE,ElementType.METHOD}) //指定注解使用的位置(成员变量,类,方法) @Retention(RetentionPolicy.RUNTIME) //指定该注解的存活时间 @Inherited //指定该注解可以被继承 public @interface Anno { } @Anno public class Person { } public class Student extends Person { public void show(){ System.out.println("student.......show.........."); } } public class StudentDemo { public static void main(String[] args) throws ClassNotFoundException { //获取到Student类的字节码文件对象 Class clazz = Class.forName("com.itheima.myanno4.Student"); //获取注解。 boolean result = clazz.isAnnotationPresent(Anno.class); System.out.println(result); } }
4注解解析
注解的解析:用反射的方式获取使用了注解的类的组成部分,获取该部分上的注解,获取注解中的数据,使用这些数据完成需求。
相关API:
相关方法1:
Class类上,Method方法上,Constructor构造上,Field成员变量上
* 可以获取注解
* 获取注解方法:
* public A getAnnotation(Class<A> annotationClass)
相关方法2:
获取注解对象后,成员变量名就是获取成员变量的方法名
案例1:
需求:
- 1、定义注解Info,里边有成员变量name姓名,有age年龄,有address地址
- 2、在Person3类上使用Info注解,
- 为Person3创建一个对象,
- 该对象的name、age、address三个成员变量的值来自注解
注解类:
/**
* 信息注解
*
*/
//在类上加该注解
@Target(ElementType.TYPE)
//注解可以参与程序运行
@Retention(RetentionPolicy.RUNTIME)
public @interface Info {
String name();
int age();
String address();
}
package com.itheima.annotation;
//在类上使用了注解
@Info(name="xiaoming",age=16,address="普利大厦")
public class Person3 {
private String name;
private int age;
private String address;
public Person3() {
}
public Person3(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "Person3{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
main方法所在的解析类:
package com.itheima.annotation;
import java.lang.annotation.Annotation;
/**
* 注解解析
*
* 需求:
* 1、定义注解Info,里边有成员变量name姓名,有age年龄,有address地址
* 2、在Person3类上使用Info注解,
* 为Person3创建一个对象,
* 该对象的name、age、address三个成员变量的值来自注解
*
* Class类上,Method方法上,Constructor构造上,Field成员变量上
* 可以获取注解
* 获取注解方法:
* public A getAnnotation(Class<A> annotationClass)
*
* 获取注解对象后,成员变量名就是获取成员变量的方法名
*/
public class Demo02 {
public static void main(String[] args) {
//获取类的字节码文件对象
Class clazz = Person3.class;
//获取注解
Class<Info> AnnoClass = Info.class;
//Person3类获取Info注解
Info info = (com.itheima.annotation.Info) clazz.getAnnotation(AnnoClass);
System.out.println(info);
//从注解中获取三个属性值
String name = info.name();
int age = info.age();
String address = info.address();
Person3 p3 = new Person3(name,age,address);
System.out.println(p3);
}
}
案例2:模拟JUnit单元测试
- 涉及到的API:
public boolean isAnnotationPresent(Class<? extends Annotation> annotationClass)
判断指定组件上是否有指定的注解
- 注解类:
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
@Retention(RetentionPolicy.RUNTIME)//注解的生命周期 存在于代码运行时
@Target(ElementType.METHOD)//只能用在方法上
public @interface MyTest {
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@interface MyBefore {
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@interface MyAfter {
}
- 使用了注解的类
- 模拟JUnit测试的@MyTest @Mybefore @MyAfter
public class Demo01 {
int age = 10;
@MyBefore
public void add() {
age += 10;
System.out.println(age); //20
}
@MyTest
public void go() {
age *= 2;
System.out.println(age); //40
}
@MyAfter
public void minus() {
age -= 10;
System.out.println(age); //30
}
public void show() {
System.out.println(age);
}
}
- 解析注解的类:
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
*
* API:
* public boolean isAnnotationPresent(Class<? extends Annotation> annotationClass)
* 判断指定组件上是否有指定的注解
*/
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Demo02 {
public static void main(String[] args) throws ClassNotFoundException, InvocationTargetException, IllegalAccessException, InstantiationException {
//1先获取Demo01的class对象
Class clazz = Class.forName("com.heima.test7.Demo01");
//创建一个demo01对应 用于后面的方法调用
Object demo01 = clazz.getConstructor().newInstance();
//2获取里面的所有的方法对象
Method[] ms = clazz.getMethods();
//3遍历所有的方法对象
for (Method m : ms) {
//4判断是不是MyBefore注解 如果是 就运行
if(m.isAnnotationPresent(MyBefore.class))
m.invoke(demo01);
}
//3遍历所有的方法对象
for (Method m : ms) {
//4判断是不是MyBefore注解 如果是 就运行
if(m.isAnnotationPresent(MyTest.class))
m.invoke(demo01);
}
//3遍历所有的方法对象
for (Method m : ms) {
//4判断是不是MyBefore注解 如果是 就运行
if(m.isAnnotationPresent(MyAfter.class))
m.invoke(demo01);
}
}
}
单例(能说出区别和不建议使用的原因)
饿汉式(静态常量) 可以用
优点:写法比较简单,就是在类装载的时候就完成实例化。避免了线程同步问题。
缺点:在类装载的时候就完成实例化,没有达到Lazy Loading(懒加载)的效果。如果从始至终从未使用过这个实例,则会造成内存的浪费。
public class Singleton {
private final static Singleton INSTANCE = new Singleton();
private Singleton() {}
public static Singleton getInstance(){
return INSTANCE;
}
}
懒汉式(线程不安全)【不建议用】
- 起到了Lazy Loading(懒加载)的效果,
- 只能在单线程下使用。如果在多线程下,一个线程进入了if (singleton == null)判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。所以在多线程环境下不可使用这种方式。
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
懒汉式(线程安全,同步方法)【不建议用】
- 对getInstance()方法进行了线程同步。
- 缺点:效率太低了,每个线程在想获得类的实例时候,执行getInstance()方法都要进行同步。每次判断instance == null也同步了
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
懒汉式 同步代码快+双重检查【建议使用】
优点:线程安全;延迟加载;效率较高。
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
静态内部类【建议使用】
- 外部类加载时,并不会加载内部类,也就不会执行
new Singleton(),这属于懒加载。只有第一次调用getInstance()方法时才会加载 Singleton类。
public class Singleton {
private Singleton() {}
private static class SingletonInstance {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}







![[MySQL]-双主+keepalived实现高可用](https://img-blog.csdnimg.cn/3dc2c82c1d6445a9a05c05e75d98d5b0.png#pic_center)