文章目录
- GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Using Generalizable NeRF
- 针对痛点和贡献
- 摘要和结论
- 引言
- 模型框架
- 实验
- 不足之处
GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Using Generalizable NeRF
基于多视角的透明和镜面物体6自由度抓取检测
Project page
针对痛点和贡献
痛点:
- 深度相机在感知透明和镜面物体的几何形状方面失败了。
贡献:
- 我们的方法将可泛化的 NeRF 扩展到抓取,无需优化即可实现稀疏输入和直接实时推理。即场景表示和抓取的联合学习,以利用它们之间的协同作用。
- 我们在杂乱的桌面场景中生成了一个大规模的合成多视图抓取数据集,利用域随机化来弥合模拟到真实的差距。
摘要和结论
本文首次提出了一种基于多视图rgb的六自由度抓取检测网络GraspNeRF,该网络利用可推广的神经辐射场(NeRF)在杂波中实现与材料无关的物体抓取。
我们的系统可以使用稀疏 RGB 输入执行零样本 NeRF 构造,并实时可靠地检测 6-DoF 抓取。
引言
- 第二段【其他工作缺陷与挑战,进而引出动机和方法】:ClearGrasp[8]、TransCG[7]、SwinDRNet[9]致力于深度恢复和基于rgb的抓取方法,利用RGBD输入,学习恢复缺失的深度,并在执行抓取之前将错误的深度纠正为一个单独的步骤。DexNeRF [10] 提供了一种有价值的替代方案,只需要 RGB 输入。它首先构建一个 NeRF,完成对物体的三维重构inverse rendering。但这种方法有几个重要的局限性。①它的NeRF构造需要耗时的每个场景训练,这需要至少几个小时,这与所需的实时运行相差甚远。②对于多目标顺序抓取,这变得更糟,因为场景在每次抓取后都会发生变化,因此需要重新训练 NeRF。
EvoNeRF[12] 提出了一个并行工作,EvoNeRF[12]提出使用Instant-NGP[13]来加速NeRF训练,并在每个抓取后进化NeRF。然而,每次更新仍然需要 7 秒,依赖于密集的图像输入,并且只能从自上而下的视图执行 3-DoF 抓取。 使用 vanilla NeRF 的另一个大缺点是从 NeRF 中提取的场景几何通常不完美,并且对于由透明物体和无纹理背景组成的场景,质量非常低,因为 NeRF 只过度拟合它们的 RGB 颜色。 错误的几何图形会严重降低下游预训练抓取算法的性能。 - 第三段:为了缓解这些问题,我们建议利用可推广的NeRF (generalizable NeRF) ,例如MVSNeRF[14]、NeuRay[15],它在许多不同的场景上进行训练,并学习聚合多视图观察和零镜头构造nerf,用于没有训练的新场景。此外,它只需要稀疏的输入视图,这对于现实世界的应用更实用。我们的框架首先构建了一个类似 3D 网格的工作空间,并通过聚合多视图图像特征来获得网格特征。在这些网格点上,我们建议预测截断符号距离函数 (TSDF,truncated signed distance function) 以获得完整的 3D 几何场景表示,这使我们不必计算深度。 输入这个TSDF,我们的体积抓取检测网络可以预测每个网格点的6自由度抓取。请注意,这个 TSDF 也可以变成密度并用于体绘制。
NeRF,这是一种强大的隐式 3D 表示,它使用 MLP 对场景几何进行编码,通过从不同视点捕获一组RGB 图像,然后使用体积渲染来渲染进一步传递到 3-DoF 抓取模块的俯视图深度图。
truncated signed distance function:TSDF地图算法分析 实时三维重建
模型框架
-
问题陈述和方法概述
我们将6-DoF自由度抓取检测,公式化为一个学习问题。该问题映射来自N个输入视图的一组图像{Ii}i=1…N,到一组6-DoF抓取{gj|gj=(tj,Rj,wj,qj)},其中,对于每个检测到的抓握(grasp)gj,tj∈R3是3D位置,Rj∈SO(3)是3D旋转,wj∈R是开口宽度,qj∈{0,1}是质量。
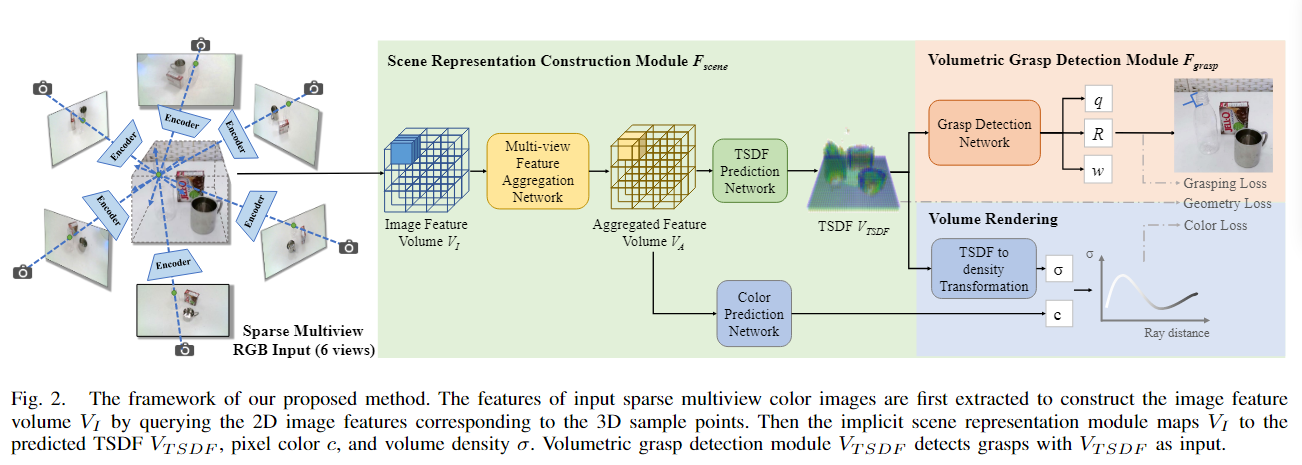
框架由场景表示构建模块(scene representation construction module)Fscene和体积抓取检测模块(volumetric grasp detection module)Fgramp组成,如图2所示。
在Fscene中,我们首先提取并聚合多视点图像,两个目的是:提取的几何特征(geometric feature)形成一个特征网格(feature grid),并将其传递到我们的TSDF预测网络,以构建场景的TSDF,该TSDF对场景几何结构以及底层NeRF的密度进行编码;同时,这些特征被用于预测颜色,这与密度输出一起实现了NeRF渲染。将预测的TSDF作为输入,我们的体积抓取检测模块Fgravity然后学习预测TSDF的每个体素处的6-DoF抓取。 -
场景表示构建
我们利用可泛化的NeRF来学习聚合来自多个视图的观察结果并形成体积特征网格。我们的场景表示构建模块中使用的可泛化 NeRF 受到 NeuRay [15] 的启发。(输出密度和颜色) -
体积抓取检测
3D CNN抓取检测器Fgrasp学习从TSDF网格到密集抓取候选体积的映射,灵感来自[2]。我们将体积内每个体素的中心视为抓取位置候选。在给定位置 t∈R3时,检测器从单独的解码器头预测三个输出,包括抓取质量q、旋转R和开口宽度w。
为了选择合适的抓取执行,我们根据预测的TSDF丢弃远离表面的抓取位置候选。随后,我们使用高斯平滑质量体积,过滤掉低于阈值的抓取,并利用非最大抑制。我们还选择满足夹持器最大开口宽度的抓取。最后,我们从剩余的候选中随机选择抓取进行机器人执行,以防止由于假阳性而重复执行不成功的抓取 -
基于域随机化的合成数据生成
提出了一种基于大规模合成多视图RGB的抓取数据集,该数据集包含100K场景,对象范围从漫反射、镜面反射到透明、240万个RGB图像和200万个6自由度抓取姿势。
为了弥合 sim2real 差距,我们利用域随机化,它随机化对象材料和纹理、背景、照明和相机姿势。在对具有足够变化的合成数据集进行训练后,网络在测试时将真实数据视为训练数据的变化,从而推广到真实数据。 -
Network End-to-End Training
端到端训练来联合学习场景表示和抓取,鼓励这两个任务相互受益。对于抓取,感知和重建场景几何至关重要;准确的抓取预测,反过来又需要高质量的场景表示。训练目标由三部分组成。
**抓取损失:**对于抓取学习,我们监督所做的抓取质量、方向和开口宽度,公式为: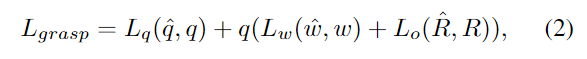 颜色损失: 学习一个可推广的辐射场,我们随机抽取6个训练视图作为每个训练场景的输入,并随机选择另一个目标视图进行渲染。我们使用 L2 损失监督新颖的视图合成。
颜色损失: 学习一个可推广的辐射场,我们随机抽取6个训练视图作为每个训练场景的输入,并随机选择另一个目标视图进行渲染。我们使用 L2 损失监督新颖的视图合成。
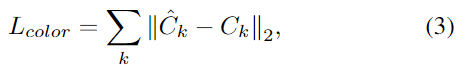
几何损失:
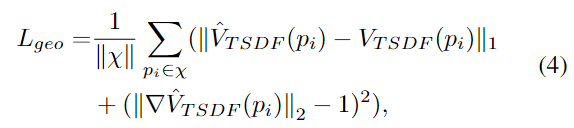
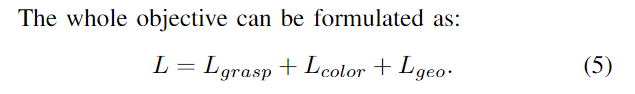
实验
在本节中,我们通过仿真和实际机器人实验来评估我们提出的方法抓取任务的性能。我们还对模拟数据进行了消融研究,以分析我们框架中包含的主要设计的影响。
-
Experiment Setup:
Grasping Environment Setup: Franka Emika Panda机器人手臂,RealSense D415 RGBD 相机(我们的方法没有使用深度)连接到夹具的手腕上。
Simulation Environment Setup: 我们在 PyBullet 和 Blender 上构建了模拟环境,分别用于物理抓取模拟和多视图逼真图像渲染。 -
评估指标: 我们通过 1)Success Rate (SR) 来衡量性能:成功抓取次数与尝试次数的比率,以及 2) 整洁率 (DR):所有轮次中移除对象的平均百分比
-
模拟抓取实验:
利用广泛的模拟数据来评估所有方法。我们的实验包括:
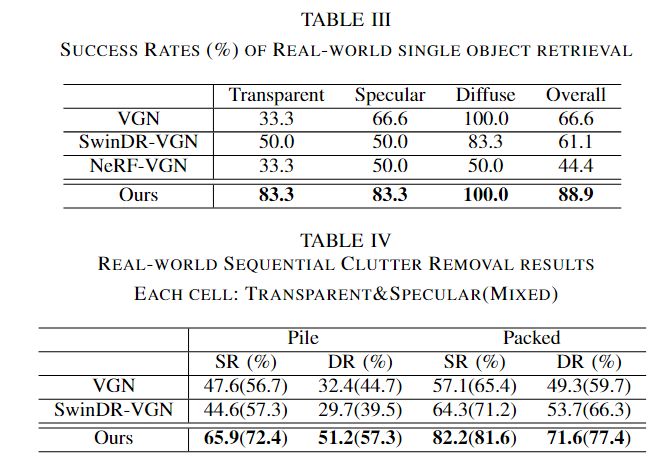
1)单个对象检索:一个对象被放置在工作空间的中心。机械臂执行基线预测的抓取,成功的抓取表明对象被抓取在工作空间之外。我们使用 12 个测试对象、4 个每个透明、镜面或漫反射材料进行评估。每个对象经过三次测试,遵循与EvoNeRF[12]相同的协议,并报告抓取成功率。
2) 顺序去杂:我们在成堆和拥挤的场景中进行了200次圆桌清理实验,每个实验包含5个对象。每一轮都共享相同的对象和对象姿势,具有两种材质组合:A)透明和高光,以及B)所有漫反射、透明和高反射材质的混合。在一轮的每次试验中,机械臂抓取并移除一个物体,直到工作空间被清空或抓取检测失败或达到两个连续的失败。报告了两种材料组合的结果。
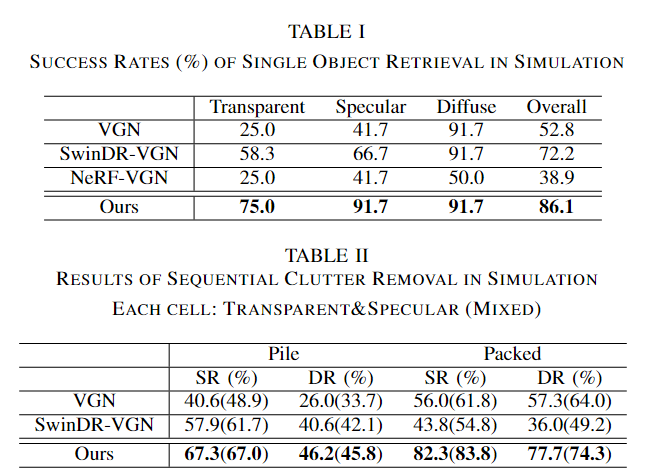
与其他方法相比,我们的方法显著提高了透明和镜面物体抓取的性能。
- real 机器人实验:
我们遵循模拟实验的协议。
1)对于单个对象检索,我们选择6个对象,包括透明、镜面反射和漫反射各2个,并将它们以相同的姿势放置在相同的位置。抓取迭代重复三次。
2)对于顺序杂波去除,我们对堆积场景和压缩场景进行了15轮迭代,报告了透明和镜面对象场景以及混合材料场景的结果。每个场景包括4-6个随机选择的对象,我们从6个视图中捕获RGB图像,就像在模拟环境中一样。网络接收多视点输入并输出6-DoF抓取候选者,其中机械臂执行顶部抓取。如果将对象从工作空间中移除,我们认为抓取是成功的。当抓取失败两次或所有物体都被清除时,一轮结束。
尽管如此,我们确实注意到了一些失败案例。例如,当抓取填充场景中的直立圆柱形物体时,如硬玻璃瓶,由于摩擦不足,夹持器可能会滑掉瓶子。

不同方法的TSDF比较。直接从原始深度观测融合的VGN的几何形状是不完整的。即使SwinDRNet恢复,几何图形仍然过于平滑,难以进行抓取检测。NeRF-VGN 也由于它在无纹理背景下渲染深度不准确而失败。由于对不同数据的学习,我们的方法仅对镜面和透明物体产生良好的 TSDF。
不足之处
一个局限性在于体积网格,其有限的分辨率可能是几何重建和抓取性能的瓶颈。我们将进一步改进留给未来的工作。