时隔一年,很久没更新博客了。今天给大家带来一个python3采集中国知网 :出版来源导航

这个是网址是中国知网的,以下代码仅限于此URL(出版来源导航)采集,知网的其他网页路径采集不一定行,大家可以试试。
在发布代码前,大家先看下下载文件数据。
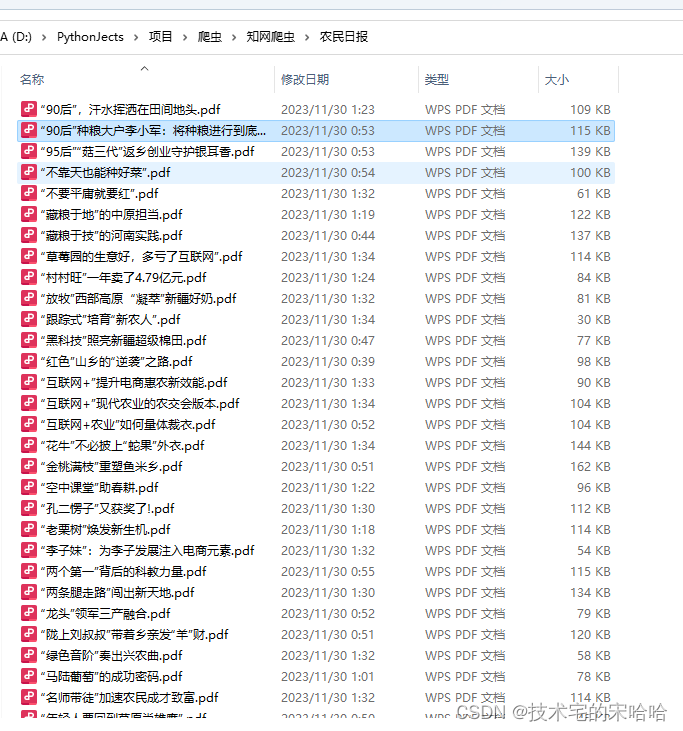
以上的数据基本来源于以下图片的导航中。
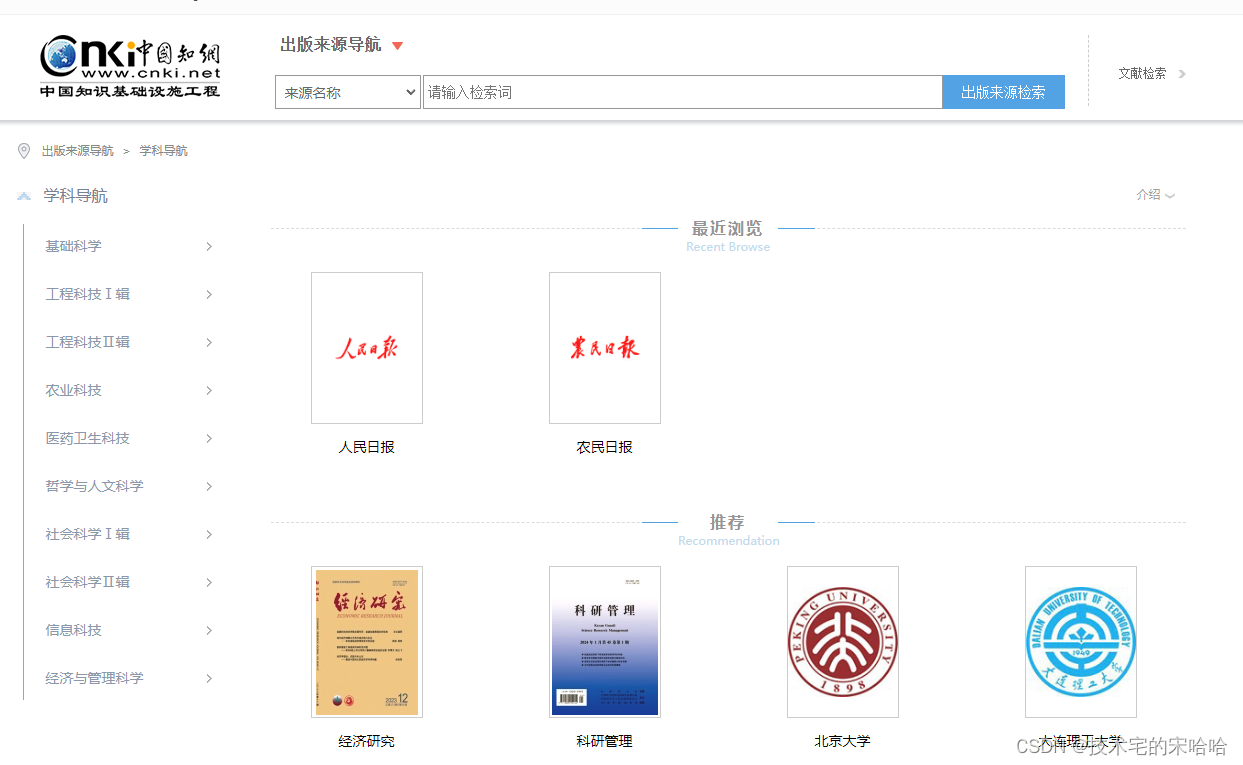
主要采集栏目搜索出自己想要的文档,然后进行采集下载本地中。
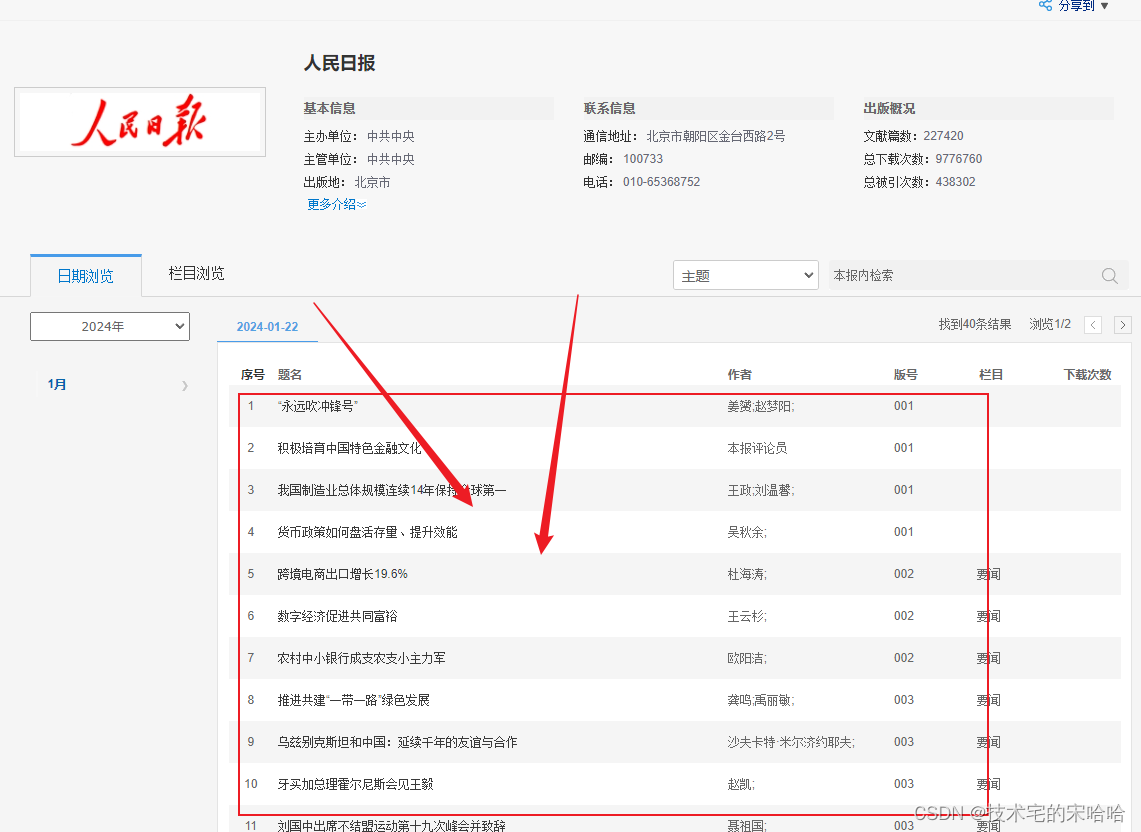
以下是完整代码,在使用代码请安装好对应的包,如果是pycharm 在设置 和 控制台终端 都可以安装。需要注意的是 自己需要替换 headers 内容。
我使用的环境是:
Windows 11 64位教育版
Pycharm 2023.2.3版本
python 3.6.8
# encoding:utf-8
import json
import random
import time
import requests
from bs4 import BeautifulSoup
import csv
import os
import urllib.parse
"""
1、excel格式,只要标题加 HTML阅读连接
2、把内容写入到WORD或者直接下载PDF
要求:全文设置关键字新农人,爬取标题、文章链接 。就这2个内容
"""
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh,zh-CN;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie':"请替换自己的COOKIE",
'Referer': 'https://navi.cnki.net/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
def get_index(page,baseId,key_words):
form_data = {
'pcode': 'CCND',
'baseId': baseId,
'where': '%28QW%25%27%7B0%7D%27%29',
# 'where': '%28QW%25%27%7B0%7D%27%29',
'searchText': key_words,
'condition': '',
'orderby': 'FFD',
'ordertype': 'DESC',
'scope': '',
'pageIndex': page,
'pageSize': '20',
'searchType': '全文',
}
headers = {
'Accept': '*/*',
# 'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Content-Length': '223',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': "请替换自己的COOKIE",
'Host': 'navi.cnki.net',
'Origin': 'https://navi.cnki.net',
'Referer': 'https://navi.cnki.net/knavi/newspapers/NMRB/detail?uniplatform=NZKPT',
'Sec-Ch-Ua': '"Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
}
url = 'https://navi.cnki.net/knavi/newspapers/search/results'
response = requests.post(url, headers=headers, data=form_data)
html = BeautifulSoup(response.content, 'lxml')
for tag in html(['thead']):
tag.extract()
try:
content = html.find_all('table', class_="tableStyle")[0]
except:
print('采集完成!')
else:
content_tr = content.find_all('tr')
for ct in content_tr:
td = ct.find('td', class_="name")
try:
href = td.find('a')['href']
except:
href = ''
try:
name = td.find('a').text
except:
name = ''
try:
releaseDate = ct.find_all('td', align="center")
releaseDate = [rd.text for rd in releaseDate if '-' in str(rd.text)][0]
except:
releaseDate = ""
data = [name, releaseDate, href]
saveCsv(baseIds, data)
get_download_urls(href)
try:
pageCount = html.find('input', id="pageCount")['value']
except:
print('爬取完成!!!')
else:
page += 1
print(f'正在爬取{page + 1}页')
t = random.randint(1, 2)
print(f'休息 {t} 秒后继续爬取')
time.sleep(t)
get_index(page,baseIds)
def saveCsv(filename, content):
"保存数据为CSV文件 list 写入"
fp = open(f'{filename}.csv', 'a+', newline='', encoding='utf-8-sig')
csv_fp = csv.writer(fp)
csv_fp.writerow(content)
fp.close()
print(f'正在写入:{content}')
def get_download_urls(url):
response = requests.get(url, headers=headers)
html = BeautifulSoup(response.content, 'lxml')
title = str(html.find('h1').text).replace('/', '').replace('\\', '')
dlpdf = html.find('li', class_="btn-dlpdf").find('a')['href']
downfiles(dlpdf, title)
def downfiles(url, filename):
session = requests.Session()
content = session.get(url=url, headers=headers).content
with open(f'{baseIds}/{filename}.pdf', 'wb') as f:
f.write(content)
print(filename, '下载成功')
def create_directory(directory):
if not os.path.exists(directory):
os.makedirs(directory)
def text_to_urlencode(chinese_str):
# 中文字符串
# chinese_str = '新农人'
# 将中文字符串编码为UTF-8格式
chinese_bytes = chinese_str.encode('utf-8')
# 将字节串转换为URL编码格式
url_encoded = urllib.parse.quote(chinese_bytes, safe='/:')
return url_encoded
if __name__ == '__main__':
# 采集网址:https://navi.cnki.net/knavi/newspapers/search?uniplatform=NZKPT
# 再网址搜索 相关报纸的关键词信息
data = ['标题', '日期', '内容链接']
pa = 0
baseIds = 'NMRB' #
create_directory(baseIds)
saveCsv(baseIds, data)
key_words = "新农人" # 关键词
key_words = text_to_urlencode(key_words)
get_index(pa,baseIds,key_words)
声明:代码仅限于学习,学术研究使用,请勿用于非法用途,如有利用代码去违法犯罪,与作者无关。
不懂得请留言。不一定及时回复,但肯定会回复。