文章目录
- 🧡🧡实验内容🧡🧡
- 🧡🧡数据预处理🧡🧡
- 认识数据
- 填充缺失值(“ ?”)
- 将income属性替换为0-1变量
- 筛除无效属性
- 编码和缩放
- 🧡🧡朴素贝叶斯分类🧡🧡
- 原理
- 代码
- 结果
- 🧡🧡逻辑回归分类🧡🧡
- 原理
- 代码
- 结果
- 🧡🧡总结🧡🧡
🧡🧡实验内容🧡🧡
基于Adult数据集,完成关于收入是否大于50K的逻辑回归分类、朴素贝叶斯模型训练、测试与评估。
🧡🧡数据预处理🧡🧡
"""
数据预处理
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 导入数据,并添加header
df=pd.read_csv('data/adult-data.csv',header=None,names =
['age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'race', 'sex',
'capital_gain', 'capital_loss', 'hours_per_week', 'native_country', 'income'])
# 导入test数据,并添加header
df_test=pd.read_csv('data/adult-test.csv',header=None,names =
['age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'race', 'sex',
'capital_gain', 'capital_loss', 'hours_per_week', 'native_country', 'income'])
# 将income属性替换为0-1变量
df.replace(" >50K", 1, inplace = True)
df.replace(" <=50K", 0, inplace = True)
df_test.replace(" >50K.", 1, inplace = True)
df_test.replace(" <=50K.", 0, inplace = True)
# 按行合并两个df
merged_df = pd.concat([df, df_test], axis=0, ignore_index=True)
# 填充缺失值
print(merged_df.apply(lambda x : np.sum(x == " ?"))) # 统计各属性缺失值个数
merged_df.replace(" ?", pd.NaT, inplace = True) # 将缺失值处先用NaT填充
trans_mode = {'workclass' : merged_df['workclass'].mode()[0],
'occupation' : merged_df['occupation'].mode()[0],
'native_country' : merged_df['native_country'].mode()[0]} # 众数
merged_df.fillna(trans_mode, inplace = True)# 用众数填充
# 筛除无效连续型变量
# merged_df.describe()
merged_df.drop(['fnlwgt','capital_gain','capital_loss'], axis = 1, inplace = True)
# 筛除无效离散变量——统计各离散值对Income关系
fig, axes = plt.subplots(nrows=4, ncols=2, figsize=(12, 16))
discreate_feature=['workclass','education','marital_status','occupation','relationship','race','sex','native_country'] # 离散属性名
for feature, ax in zip(discreate_feature, axes.flatten()):
counts = merged_df.groupby(feature)['income'].value_counts().unstack()
counts.plot(kind='bar', stacked=True, ax=ax)
ax.set_xlabel(feature)
ax.set_ylabel('Count')
plt.tight_layout() # 自适应
plt.show()
merged_df.drop('native_country', axis = 1, inplace = True)
merged_df.info()
### 对离散数据进行标签编码
from sklearn import preprocessing
encoder = preprocessing.LabelEncoder()
for col in merged_df.columns:
if merged_df[col].dtype==object: # 字符型数据
merged_df[col]=encoder.fit_transform(merged_df[col])
print(encoder.inverse_transform(list(range(merged_df[col].nunique())))) # 查看每个编码对应的原始分类
### 对连续型数据进行数值缩放
continuous_col=['age','education_num','hours_per_week']
for col in continuous_col:
merged_df[col]=preprocessing.MinMaxScaler(feature_range=(-1,1)).fit_transform(merged_df[[col]]) # 注意这里fit_transform接受二维数组,所以要两个[]
### 独热编码
# merged_df = pd.get_dummies(merged_df, columns=['workclass', 'education', 'marital_status', 'occupation', 'relationship', 'race', 'sex'])
merged_df
merged_df.to_csv("data/merged_data.csv")
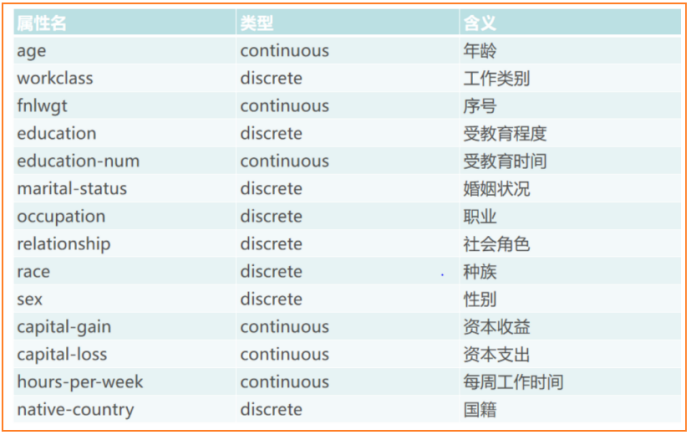
认识数据
14个特征变量如下
1个目标变量:Income:>50K 或 <50K
填充缺失值(“ ?”)
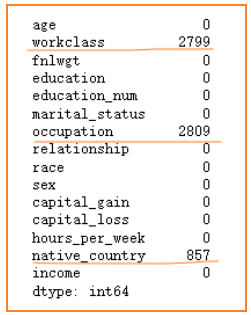
统计各类型数据缺失个数如下,这三种缺失数据类型均为离散型(discrete),因此采用众数填充较为合理。众数分别为private、Prof-specially、United-States。
将income属性替换为0-1变量
Income>50K的设置为1,Income<50K的设置为0
筛除无效属性
对于连续型数据,可以看到,captial-gain和captial-loss这两列数据有75%是0,可以认为是无关属性,另外,序号fnlwgt(序号)根据其含义也认为是无关属性,对它们进行删除。
对于离散型数据,统计各离散值对Income关系,从最后一个图明显可以看到超过95%的人是来自United-States的,因此考虑删除这native-country这一列属性
筛除后,剩下3个连续变量、7个离散变量

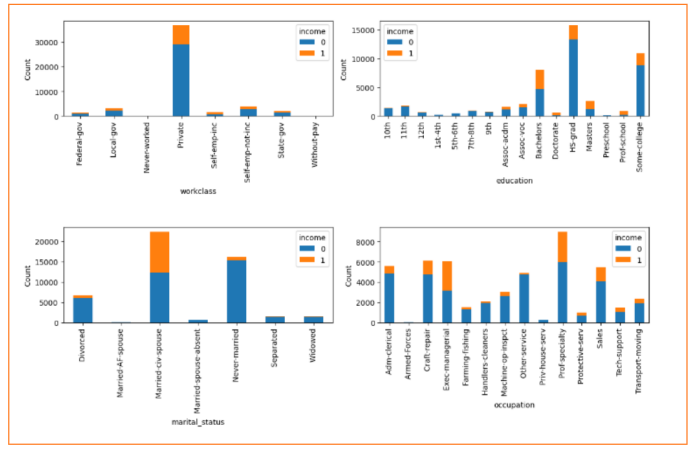
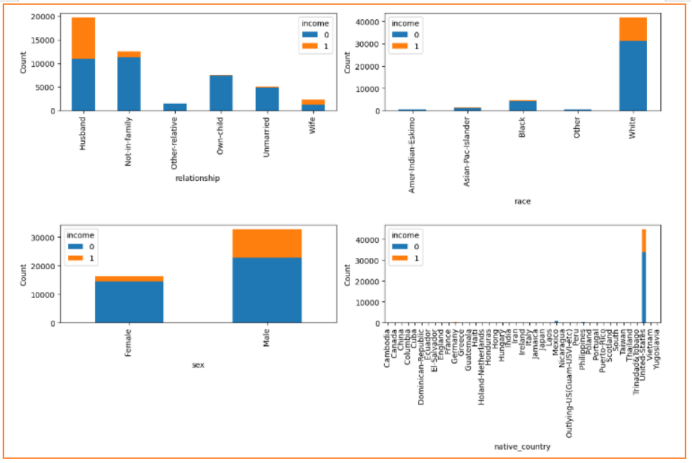

编码和缩放
对离散型数据进行标签编码,鉴于某些特征分类值较多(workclass、occupation),不易直接评判哪种分类值取较高权重,因此直接采用计算机自行编码,避免主观性。
对连续型数据进行数值缩放,缩放到-1到1之间,避免量纲不一样带来的影响。
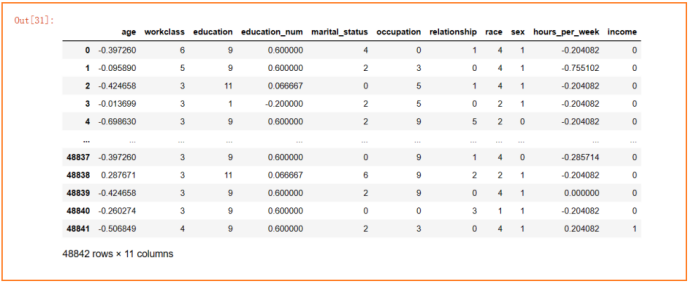
🧡🧡朴素贝叶斯分类🧡🧡
原理
核心公式
对于二分类问题,在已知样本特征的情况下,分别求出两个分类的后验概率:P(类别1 | 特征集),P(类别2 | 特征集),选择后验概率最大的分类作为最终预测结果。
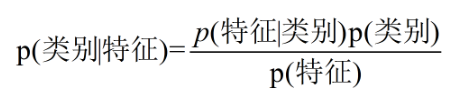
为何需要等式右边?
对于某一特定样本,很难直接计算它的后验概率(左边部分),而根据贝叶斯公式即可转为等式右边的先验概率(P(特征)、P(类别))和条件概率(P(特征 | 类别)),这些可以直接从原有训练样本中求得,其次,由于最后只比较相对大小,因此分母P(特征)在计算过程中可以忽略。
右边P(特征 | 类别)和P(特征)如何求?
例如,对于adult这个数据集,假设特征只有race、sex、education,目标为income。
对于某个样本,他的特征是白人、男性、硕士。
则他income>50K的概率是
P(>50K | 白人、男性、硕士) =
P(白人、男性、硕士 | >50K) * P(>50K) / P(白人、男性、硕士)
- 对于P(>50K),即原训练样本集中的income>50K的频率。
- 对于P(白人、男性、硕士 | >50K),并不是直接求原训练样本集中满足income>50K条件下,同时为白人、男性、硕士的概率,这样由于数据的稀疏性,很容易导致统计频率为0, 因此朴素贝叶斯算法就假设各个特征直接相互独立,即P(白人、男性、硕士 | >50K) = P(白人 | >50K)*P(男性 | >50K)*P(硕士 | >50K),朴素一词由此而来。
- 对于P(白人、男性、硕士),同上述,其等于P(白人)*P(男性)*P(硕士)
代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
merged_df=pd.read_csv("data/merged_data.csv")
merged_df.drop(['age','education_num','hours_per_week'],axis=1,inplace=True)
merged_df
from sklearn.metrics import accuracy_score
class NaiveBayes:
def fit(self, X, y):
self.X = X
self.y = y
self.classes = np.unique(y) # 目标分类名称集:(0 、 1),ex:嫁、不嫁
self.prior_probs = {} # 先验概率
self.cond_probs = {} # 条件概率
# 计算先验概率——分子项 P(类别), ex:P(嫁)、P(不嫁)
for c in self.classes:
self.prior_probs[c] = np.sum(y == c) / len(y)
# 计算条件概率——分子项 P(特征/类别), ex:P(帅、性格好、身高矮、上进 | 嫁)
for feature_idx in range(X.shape[1]): # 0....featureNum 表示每一列特征索引,ex:是否帅、是否性格好、身高程度、上不上进
self.cond_probs[feature_idx] = {}
for c in self.classes:
feature_values = np.unique(X[:, feature_idx]) # featureValue1、featureValue2、...ex:帅、不帅
self.cond_probs[feature_idx][c] = {}
for value in feature_values:
idx = (X[:, feature_idx] == value) & (y == c) # [0,1,0,0,0.......]
self.cond_probs[feature_idx][c][value] = np.sum(idx) / np.sum(y == c) # ex:P[是否帅][嫁][帅]
def predict(self, X_test):
pred_label = []
pred_scores = []
# 对每个测试样本进行预测
for x in X_test:
posterior_probs = {}
# 计算后验概率——P(嫁|帅、性格好、身高矮、上进) 和 P(不嫁|帅、性格好、身高矮、上进)
for c in self.classes:
posterior_probs[c] = self.prior_probs[c]
for feature_idx, value in enumerate(x):
if value in self.cond_probs[feature_idx][c]:
posterior_probs[c] *= self.cond_probs[feature_idx][c][value]
# 选择后验概率最大的类别作为预测结果
predicted_class = max(posterior_probs, key=posterior_probs.get) # 获得最大的value对应的key
pred_score = posterior_probs[predicted_class] # 获得最大的value
pred_label.append(predicted_class)
pred_scores.append(pred_score)
return pred_label, pred_scores
## =====================拆分train和test=====================
train=merged_df.iloc[:35000]
test=merged_df.iloc[35000:]
y_train=train['income'].values # array类型
x_train=train.drop('income',axis=1).values # array类型
y_test=test['income'].values
x_test=test.drop('income',axis=1).values
# 训练+预测
nb = NaiveBayes()
nb.fit(x_train, y_train)
y_pred, y_scores = nb.predict(x_test)
y_train
# 计算AUC
def cal_AUC(y_true_labels, y_scores): # y_labes中0,1代表正负样本, y_scores中0.2表示有0.2概率预测为正样本
pos_sample_ids = [i for i in range(len(y_true_labels)) if y_true_labels[i] == 1]
neg_sample_ids = [i for i in range(len(y_true_labels)) if y_true_labels[i] == 0]
sum_indicator_value = 0
for i in pos_sample_ids:
for j in neg_sample_ids:
if y_scores[i] > y_scores[j]:
sum_indicator_value += 1
elif y_scores[i] == y_scores[j]:
sum_indicator_value += 0.5
auc = sum_indicator_value/(len(pos_sample_ids) * len(neg_sample_ids))
return auc
# 混淆矩阵
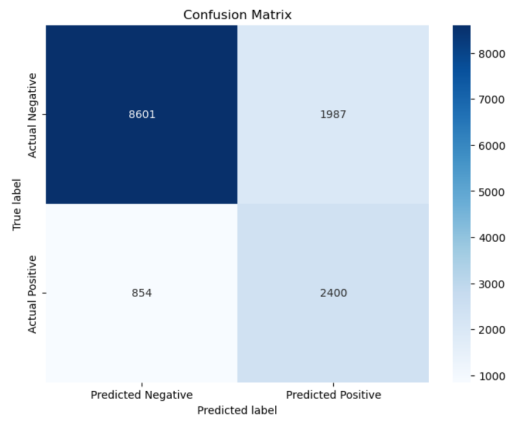
def cal_ConfusialMatrix(y_true_labels, y_pred_labels):
cm = np.zeros((2, 2))
for i in range(len(y_true_labels)):
cm[ y_true_labels[i], y_pred_labels[i] ] += 1
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=['Predicted Negative', 'Predicted Positive'], yticklabels=['Actual Negative', 'Actual Positive'])
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.title('Confusion Matrix')
plt.show()
# 计算准确率
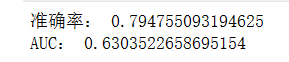
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
print("AUC:", cal_AUC(y_test, y_scores))
y_pred=[int(x) for x in y_pred]
cal_ConfusialMatrix(y_test, y_pred)
结果
分类准确率达0.79,跟逻辑回归迭代到10000次差不多,可以看出其相对逻辑回归更加简单高效,但是AUC值确只有0.64,理论上,朴素贝叶斯模型与其他分类方法相比,具有最小的误差率,但这个的前提是要求各特征变量两两相互独立,而在现实中,各特征属性之间往往都具有一定的关系,例如本实验中adult集中education(受教育程度)、education_num(受教育时间)、martial_status(婚姻状况)、relationship(社会角色)等等,它们之间会存在一些相关关系,从而影响模型分类。
🧡🧡逻辑回归分类🧡🧡
原理
逻辑回归可以简单理解为 == 线性回归 + sigmod函数。
即将线性回归的结果(连续型),通过sigmod函数映射到(0,1)之间,将连续的值转为0-1之间的概率值,然后如果概率值>0.5,则认为是正样本,反之是负样本,从而达到二分类效果。
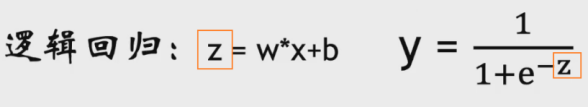
那么以什么为标准(目标)优化参数w和b呢?
通过最小化以下这个交叉熵函数来优化参数
其中y代表真实值0或1;p(x)代表预测为1的概率值0~1。
当y=1时,L=-log ( p(x) ),此时P(x)越大(即预测为1越准确),L越小
当y=0时,L=-log ( 1-p(x) ),此时P(x)越小(即预测为0越准确),L越小
因此以最小化该交叉熵为目标,从而实现参数优化。
那么如何进行极小化交叉熵呢?
通过梯度下降,将交叉熵函数比作一座山,在山上每次确定最佳下坡方向(也即对交叉熵L求w的偏导),确定步幅(即学习率大小),这样逐渐下去,就能找到极小化交叉熵L,从而得到较优的(全局最优/局部最优)的模型参数。
代码
# logitic
from sklearn import datasets
# 加载数据并简单划分为训练集/测试集
def load_dataset():
dataset = datasets.load_breast_cancer()
train_x,train_y = dataset['data'][0:400], dataset['target'][0:400]
test_x, test_y = dataset['data'][400:-1], dataset['target'][400:-1]
return train_x, train_y, test_x, test_y
# logit激活函数sigmod, z = wx+b (线性回归结果)
def sigmoid(z):
y = z.copy()
y[z >= 0] = 1.0 / (1 + np.exp(-z[z >= 0])) # 1 / (1+e^-x)
y[z < 0] = np.exp(z[z < 0]) / (1 + np.exp(z[z < 0])) # 若z接近负无穷np.exp(-z)会溢出,因此采用 e^x / (1+e^x)
return y
# 权重初始化0 或 1
def initialize_with_zeros(dim):
w = np.zeros((dim, 1))
b = 0
return w, b
# 定义学习的目标函数,计算梯度
def propagate(w, b, X, Y): # X:每一列为一个样本
m = X.shape[1] # 样本数
A = sigmoid(np.dot(w.T, X) + b) # 逻辑回归输出预测值 (0~1的概率值)
cost = -1 / m * np.sum(Y * np.log(A+1e-8) + (1 - Y) * np.log((1 - A)+1e-8)) # 交叉熵损失为目标函数
dw = 1 / m * np.dot(X, (A - Y).T) # 计算权重w梯度
db = 1 / m * np.sum(A - Y)
cost = np.squeeze(cost) # 去掉维数为1 那一维
grads = {"dw": dw,
"db": db}
return grads, cost
# 定义优化算法
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost):
costs = []
for i in range(num_iterations): # 梯度下降迭代优化
grads, cost = propagate(w, b, X, Y)
dw = grads["dw"] # 权重w梯度
db = grads["db"]
w = w - learning_rate * dw # 按学习率(learning_rate)负梯度(dw)方向更新w
b = b - learning_rate * db
if i % 500 == 0:
costs.append(cost)
if print_cost and i % 500 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
#传入优化后的模型参数w,b,模型预测
def predict(w, b, X):
m = X.shape[1] # m为样本数
Y_prediction = np.zeros((1,m))
Y_score = sigmoid(np.dot(w.T, X) + b)
for i in range(Y_score.shape[1]):
if Y_score[0, i] <= 0.5:
Y_prediction[0, i] = 0
else:
Y_prediction[0, i] = 1
return Y_prediction, Y_score
def model(X_train, Y_train, X_test, Y_test, num_iterations, learning_rate, print_cost):
# 初始化
w, b = initialize_with_zeros(X_train.shape[0])
# 梯度下降优化模型参数
parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
w = parameters["w"]
b = parameters["b"]
# 模型预测结果
Y_prediction_test, Y_score_test = predict(w, b, X_test)
Y_prediction_train, Y_score_train = predict(w, b, X_train)
# 模型评估准确率
train_acu=100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100
test_acu=100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100
print("train accuracy: {} %".format(train_acu))
print("test accuracy: {} %".format(test_acu))
paras = {
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations": num_iterations,
"train_acu": train_acu,
"test_acu": test_acu,
"costs": costs,
"Y_score_test": Y_score_test,
"Y_score_train": Y_score_train,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train" : Y_prediction_train
}
return paras
# 加载癌细胞数据集 train_set_x:400*30 test_set_x:168*30 train_set_y:长度为400的list test_set_y:长度为168的list
train_set_x, train_set_y, test_set_x, test_set_y = load_dataset()
# print(train_set_x.shape)
# print(test_set_x.shape)
# print(train_set_y)
# print(test_set_y)
# 转置一下 每一列为一个样本
train_set_x = train_set_x.reshape(train_set_x.shape[0], -1).T
test_set_x = test_set_x.reshape(test_set_x.shape[0], -1).T
# print(train_set_x.shape)
# print(test_set_x.shape)
#训练模型并评估准确率
paras = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 500, learning_rate = 0.001, print_cost = True)
## =====================拆分train和test=====================
train=merged_df.iloc[:35000]
test=merged_df.iloc[35000:]
y_train=train['income'].values # 转为array
x_train=train.drop('income',axis=1).values
y_test=test['income'].values
x_test=test.drop('income',axis=1).values
x_train = x_train.reshape(x_train.shape[0], -1).T ## 转置一下 每一列为一个样本
x_test = x_test.reshape(x_test.shape[0], -1).T
## =====================evaluate=====================
import seaborn as sns
def cal_AUC(y_true_labels, y_scores): # y_labes中0,1代表正负样本, y_scores中0.2表示有0.2概率预测为正样本
pos_sample_ids = [i for i in range(len(y_true_labels)) if y_true_labels[i] == 1]
neg_sample_ids = [i for i in range(len(y_true_labels)) if y_true_labels[i] == 0]
sum_indicator_value = 0
for i in pos_sample_ids:
for j in neg_sample_ids:
if y_scores[i] > y_scores[j]:
sum_indicator_value += 1
elif y_scores[i] == y_scores[j]:
sum_indicator_value += 0.5
auc = sum_indicator_value/(len(pos_sample_ids) * len(neg_sample_ids))
print('AUC calculated by function1 is {:.2f}'.format(auc))
return auc
def cal_ConfusialMatrix(y_true_labels, y_pred_labels):
cm = np.zeros((2, 2))
for i in range(len(y_true_labels)):
cm[ y_true_labels[i], y_pred_labels[i] ] += 1
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=['Predicted Negative', 'Predicted Positive'], yticklabels=['Actual Negative', 'Actual Positive'])
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.title('Confusion Matrix')
plt.show()
## =====================画图=====================
y_iter_acu=[]
y_iter_AUC=[]
for iter_num in range(500,11000,1000):
print(f"=====iter: {iter_num}====")
paras = model(x_train, y_train, x_test, y_test, num_iterations = iter_num, learning_rate = 0.01, print_cost = False)
y_iter_acu.append(paras["test_acu"])
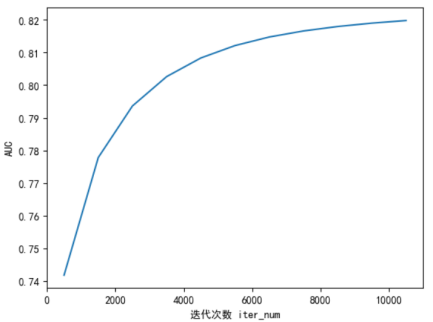
y_iter_AUC.append(cal_AUC( y_test, paras["Y_score_test"][0].tolist() ))
plt.rcParams['font.sans-serif'] = ['SimHei'] # # 设置中文字体
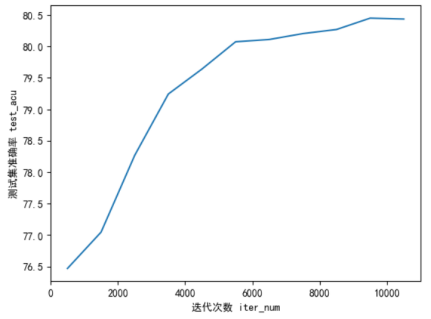
plt.plot(list(range(500,11000,1000)), y_iter_acu )
plt.xlabel("迭代次数 iter_num")
plt.ylabel("测试集准确率 test_acu")
plt.show()
plt.plot(list(range(500,11000,1000)), y_iter_AUC)
plt.xlabel("迭代次数 iter_num")
plt.ylabel("AUC")
plt.show()
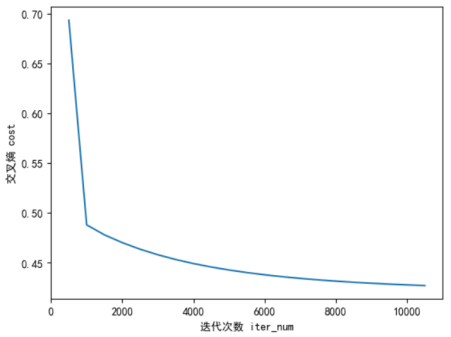
plt.plot(list(range(500,11000,500)),paras["costs"])
plt.xlabel("迭代次数 iter_num")
plt.ylabel("交叉熵 cost")
plt.show()
## =====================打印iter=10500时 参数=====================
# paras = model(x_train, y_train, x_test, y_test, num_iterations = 10500, learning_rate = 0.01, print_cost = False)
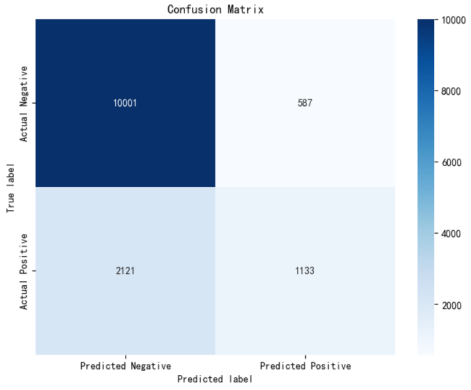
# 混淆矩阵
Y_prediction_test=paras["Y_prediction_test"][0].tolist()
Y_prediction_test=[int(x) for x in Y_prediction_test]
cal_ConfusialMatrix(y_test, Y_prediction_test)
# weight
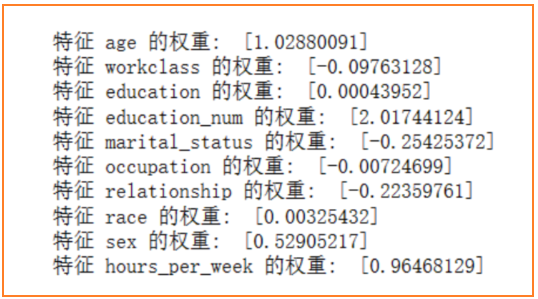
for col,w in zip(merged_df.columns, paras['w']):
print(f"特征 {col} 的权重: ", w)
结果
随着迭代次数增加,准确率保持在80.4%左右、AUC值保持在0.82,而sklearn的高层逻辑回归API中,准确率在84%左右,因此实验结果符合预期。
🧡🧡总结🧡🧡
分析各个特征与目标预测类别的正负相关性
由逻辑回归各个特征权重如下
- 首先可以看到连续型变量(age、education_num、hours_per_week)都与income成强正相关,也即年龄越高、受教育时间越多、每周工作时间越多,收入越高。其中,受教育时间与income的收入相关性程度最大,这与现实情况相符,一般来说,受过更高教育的人群往往拥有更高的收入。
- 对于离散型变量,具有正相关性的是education、race、sex,表明教育水平、种族、性别对收入有一定的正相关性,对应于编码中,raceWhite、sexMale的人收入较高(这从前面统计图中也能看出)。其他具有负相关性的特征:workclass、marital_status、occupation、relationship,表明:
- 某些工作类别下的收入相对较低,或者是某些特定的工作类别对收入产生负面影响;职业与收入呈负相关,但权重较小,只有0.007,这可能意味着特定职业对收入影响较小,或者是该模型中职业对收入的解释力度较弱。
- 某些婚姻状态下的家庭责任和支出、家庭关系状态对个人收入构成负面影响,对应于marital_status编码,编码赋值较高的是Never-Married、Separated、Widowed,即无稳定婚姻状况或单身的人的收入会偏低。
扩展
准确率有时不仅跟模型参数有关,数据预处理格式也很重要,本实验中我对于离散型特征同一采用标签编码的方式进行处理,或许可以尝试对于某些分类种别较少 且 没有明显程度排序的特征使用独热编码(如sex、workclass等等)。
另外,对于朴素贝叶斯模型,常常适用于离散型特征,而本实验中adult集含有少数连续型变量,网上了解到可以采用高斯朴素贝叶斯进行分类。