import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
一、数据处理部分
①定义数据转换 ②加载训练和测试数据,实验数据转换 ③使用dataloader加载数据,类似与生成器,需要多少数据取多少数据
#数据转换
transforms = torchvision.transforms.Compose([
transforms.ToTensor() #将array转换为tensor 才能作为神经网络的输入
])
train = torchvision.datasets.MNIST('/mnist',train=True,download=True,transform = transforms) #mnist中训练集和测试集已经分好了
test = torchvision.datasets.MNIST('/mnist',train=False,download=True,transform= transforms) # 要记得加上transforms进行数据的转换
#定义批次 一次性给神经网络输入的数据量 是否进行打乱
dl_train = torch.utils.data.DataLoader(train,batch_size=64,shuffle=True)
dl_test = torch.utils.data.DataLoader(test,batch_size=64,shuffle=True)
以下可以查看图像
image,label = next(iter(dl_train)) #图片和真实的标签,取一个batch也就是64张
image.shape#64批量大小,1是黑白图像,28*28是图像大小
#查看一张图片
im = image[0]#tensor
im = im.numpy()#转换为np
im.shape#(1,28,28)
#灰度图
im= np.squeeze(im)#将维度为1 的维度删掉
im.shape #(28,28)
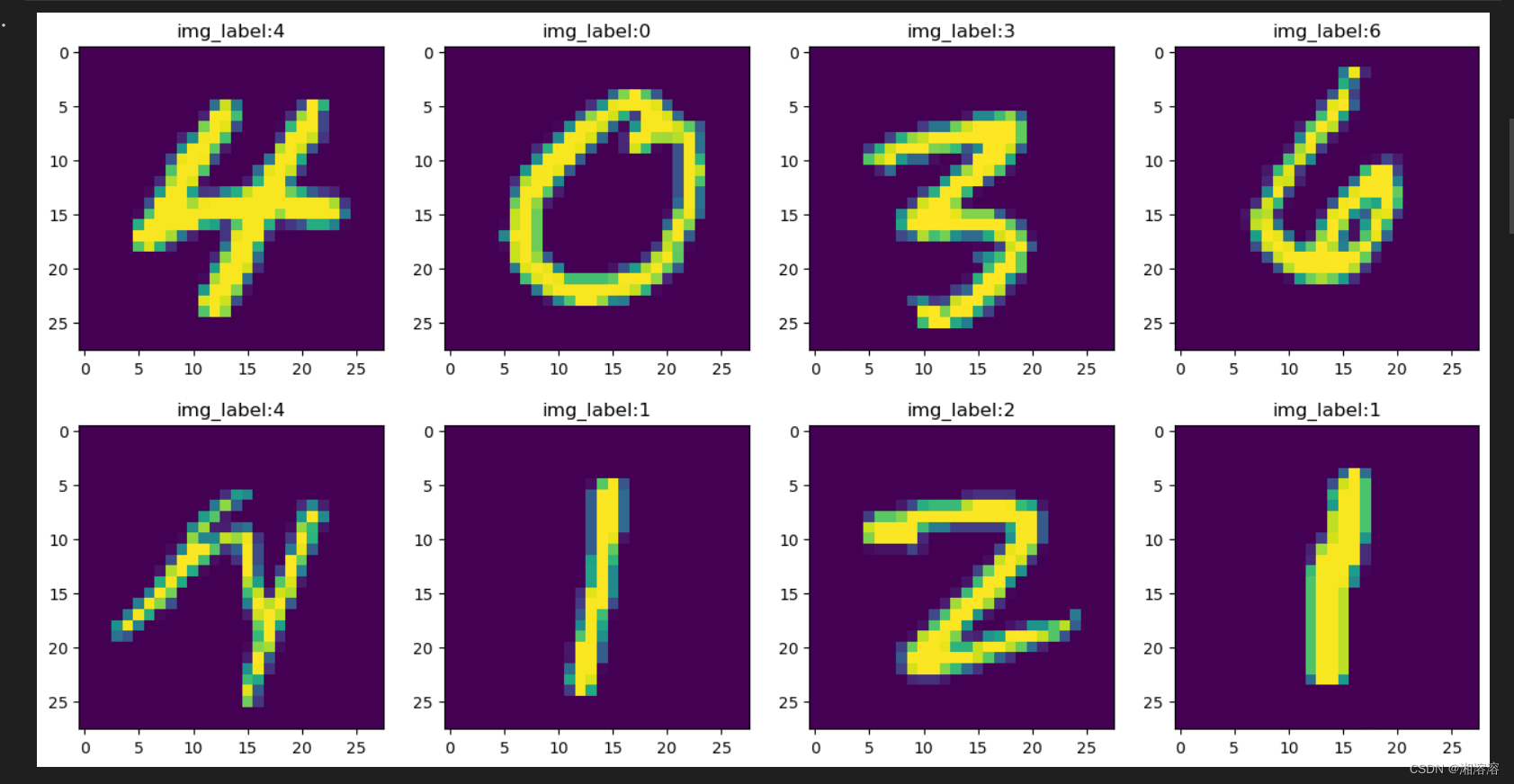
#图片批量展示
plt.figure(figsize=(16,8)) ##长为16高为8的画板
#写循环输出
for i in range(len(image[:8])): #image[0:8] 的维度是【8,1,28,28】 也就是从一个批次中取了八张图片
#每次取一张图片
img = image[:8][i].numpy()
img = np.squeeze(img)##(1,28,28)的图像需要删除1 才可以show
label_img = label[:8][i].numpy()#将标签作为标题
plt.subplot(2,4,i+1)#在大图中绘制小图
plt.title('img_label:{}'.format(label_img))
plt.imshow(img)
二、 定义模型 定义一个class
class IMNet(nn.Module):
def __init__(self): #定义神经网络
super(IMNet,self).__init__() #从nn.module中继承一些基本的参数
self.layer1 = nn.Sequential(
nn.Conv2d(1,32,kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(32,64,kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.fc = nn.Sequential(
nn.Linear(64*5*5,1024),
nn.Linear(1024,10)
)
#self.conv1 = nn.Conv2d(1,32,kernel_size=3) #输入通道 卷积核个数 卷积核大小
#self.conv2 = nn.Conv2d(32,64,kernel_size=3)
#self.pool = nn.MaxPool2d(2,2) #卷积核大小 步长
#self.fc1 = nn.Linear(64*5*5,1024)
#self.fc2 = nn.Linear(1024,10) #十分类
def forward(self,x): #前向传播,定义神经网络的使用
#x = F.relu(self.conv1(x))
#x = self.pool(x)
#x = F.relu(self.conv2(x))
#x = self.pool(x)
#print(x.shape)#知道图片的大小 torch.Size([64,64,5,5])
#x = x.view(-1,64*5*5)#压缩数据 linear层的数据需要的是一维的,而输入数据是四维的需要进行压缩
#x = self.fc1(x)
#x = self.fc2(x)
x = self.layer1(x)
x = self.layer2(x)
x = x.view(-1,64*5*5)
x = self.fc(x)
return x#返回预测值
model = IMNet() #实例化模型 #可以通过模型中的print知道 图片的大小
三、定义损失函数优化器,训练函数
#损失函数
loss_func = nn.CrossEntropyLoss()
#优化器
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = model.to('cuda')#放到GPU上
import time#查看学习时间
from tqdm import tqdm #查看学习的速度
correct = 0 #正确率
total_number = 0
running_loss = 0
epochs = 5
def trainNet(epochs,model,dl_train,dl_test):
correct = 0
total_number = 0
running_loss = 0
test_correct = 0
test_total_number = 0
test_running_loss = 0
for epoch in range(epochs):
model.train()#训练模式
for x,y in tqdm(dl_train):#x是数据,y是label #显示进度
x,y = x.to('cuda'),y.to('cuda')
y_prediction = model(x) #输入到图像中输出预测值
loss = loss_func(y_prediction,y)#真实值与预测值之间差距
optimizer.zero_grad()#对优化器进行初始化
loss.backward()#通过loss进行反向传播
optimizer.step() #把模型放到优化器中进行梯度下降,对loss进行梯度下降的计算
#统计准确率
with torch.no_grad(): #以下内容不放到梯度中,统计准确度(要优化的只有神经网络的权重)
y_finalPred = torch.argmax(y_prediction,dim=1)#取出最大值,dim=1在10中找到最大值
#输出是【64,10】(64张图片每张图片有10个预测值)最大的值是预测的值
correct += (y_finalPred==y).sum().item() #64张图中预测正确也就是一个批次中预测正确的
total_number += y.size(0) #总数
running_loss += loss.item() #一个批次中的loss 累加成总体的损失值
#一整个epoch中的loss 所有图片加起来的loss/图片数量(一个epoch60000) 平均到每张图片的loss
epoch_loss = running_loss/len(dl_train.dataset)
epoch_acc = correct / total_number
model.eval()#预测模式
for x,y in tqdm(dl_test):
x,y = x.to('cuda'),y.to('cuda')
y_prediction = model(x)
loss = loss_func(y_prediction,y)
with torch.no_grad():
y_finalPred = torch.argmax(y_prediction,dim=1)
test_correct += (y_finalPred==y).sum().item()
test_correct += y.size(0)
test_running_loss += loss.item()
test_epoch_loss = test_running_loss/len(dl_test.dataset)
test_epoch_acc = test_correct / test_correct
print(epoch,'accuracy:{}'.format(round(epoch_acc,3)),'loss:{}'.format(round(epoch_loss,3)))
print(epoch,'test_accuracy:{}'.format(round(test_epoch_acc,3)),'test_loss:{}'.format(round(test_epoch_loss,3)))
trainNet(epochs,model,dl_train,dl_test)