文件的存储方式
- 在计算机中,文件是以 二进制的方式保存在磁盘上的
文本文件和二进制文件
- 文本文件
- 可以使用文本编辑软件查看
- 本质上还是二进制文件
- 二进制文件
- 保存的内容 不是给人直接阅读的,而是提供给其它软件使用的
- 二进制文件不能使用 文件编辑软件 查看
文件基本操作
操作文件的套路
在计算机 中要操作文件一共包含三个步骤:
1.打开文件
2.读、写文件
读 将文件内容读入内容
写 将内存内容写入文件
3.关闭文件
操作文件的函数/方法
| 序号 | 函数/方法 | 说明 |
|---|---|---|
| 1 | open | 打开文件,并且返回文件操作对象 |
| 2 | read | 将文件内容读取到内存 |
| 3 | write | 将指定内容写入文件 |
| 4 | close | 关闭文件 |
- open 函数负责打开文件,并且返回文件对象
- read /write / close 三个方法都需要通过文件对象 来调用
read方法——读取文件
- open 函数的第一个参数是要打开的文件名(文件名区分大小写)
- 如果文件存在,返回 文件操作对象
- 如果文件不存在,会抛出异常
- read 方法可以一次性 读入 并 返回文件的所有内容
- close 方法负责关闭文件
- 如果忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
# 打开文件
f=open("D:\测试.txt","r",encoding="UTF-8")
print(f"{type(f)}")
# 读取文件 -read()
x=f.read(10)
print(f"读取10个字节的结果是:{x}")
print(f"read方法读取全部内容是:{f.read()}")
# 读取文件 -readlines()
lines=f.readlines()
print(f"lines对象的类型是:{type(lines)}")
print(f"lines对象的内容是:{lines}")
# 读取文件 -readline()
line1=f.readline()
line2=f.readline()
line3=f.readline()
print(f"第一行的内容是:{line1}")
print(f"第二行的内容是:{line2}")
print(f"第三行的内容是:{line3}")
# for循环读取文件行
for line in f.read():
print(line,end="")
for line in f:
print(line)
# 文件的关闭
f.close()
# with open 语法的操作文件
with open("D:\测试.txt","r",encoding="UTF-8") as f:
for line in f:
print(line)
打开文件的方式
- open 函数默认以 只读方式 打开文件,并且返回文件对象
语法如下:
| 访问方式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常 |
| w | 以只写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a | 以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的末尾。如果文件不存在,创建新文件进行写入 |
| r+ | 以读写方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常 |
| w+ | 以读写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a+ | 以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
代码演示:
"""
演示文件的写入操作
"""
import time
# 打开文件,不存在的文件
f=open("D:/test.txt","w",encoding="UTF-8")
# write写入
f.write("Hello World!!")
# flush刷新
# f.flush()
# close关闭
f.close() # close内置了flush功能
# 打开一个存在的文件
f=open("D:/test.txt","w",encoding="UTF-8")
# write写入,flush刷新
f.write("黑马程序员")
# close关闭
f.close()以追加方式打开文件:
"""
演示文件的追加操作
"""
# 打开文件
f=open("D:/test.txt","a",encoding="UTF-8")
# write写入
f.write("黑马程序员")
# flush刷新
f.flush()
# close关闭
f.close()
# 打开一个存在的文件
f=open("D:/test.txt","a",encoding="UTF-8")
# write写入、flush刷新
f.write("\n是一个非常棒的官网")
f.flush()
# close关闭
f.close()按行读取文件内容
- read 方法默认会把文件的 所有内容一次性读取到内存
- 如果文件太大,对内存的占用会非常严重
readline 方法
- readline 方法可以一次读取一行内容
- 方法执行后,会把文件指针移动到下一行,准备再次读取
代码演示:
# 读取文件 -readlines()
lines=f.readlines()
print(f"lines对象的类型是:{type(lines)}")
print(f"lines对象的内容是:{lines}")
# 读取文件 -readline()
line1=f.readline()
line2=f.readline()
line3=f.readline()
print(f"第一行的内容是:{line1}")
print(f"第二行的内容是:{line2}")
print(f"第三行的内容是:{line3}")课后小练习:
1,单词计数
通过Windows的文本编辑器软件,将如下内容复制保存到:word.txt,文件可以存储在任意位置

通过文件读取操作,读取此文本,统计itheima单词出现的次数
# 打开文件,一读取模式打开
f=open("D:/word.txt","r",encoding="UTF-8")
# 方式1:读取全部内容,通过字符串count方法统计单词itheima的个数
content=f.read()
count=content.count("itheima")
print(f"ieheima一共出现了{count}次")
# 方式2:读取内容,一行一行读取
count=0
for line in f:
line=line.strip()
words=line.split(" ")
for word in words:
if word=="itheima":
count+=1
# 判断单词出现次数并累计
print(f"ieheima一共出现了{count}次")
# 关闭文件
# f.close()
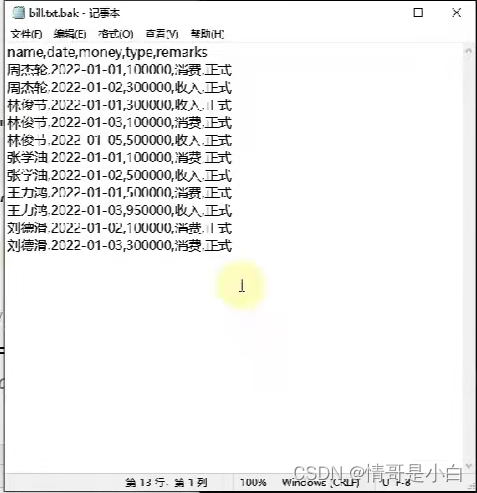
2,需求:有一份账单文件,记录了消费收入的具体记录,内容如下:
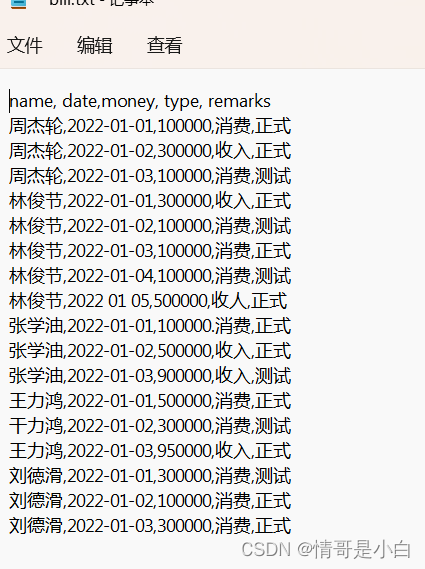
可以将内容复制并保存为bill.txt
代码如下:
# 打开文件得到文件对象,准备读取
fr=open("D:/bill.txt","r",encoding="UTF-8")
# 打开文件得到文件对象,准备写入
fw=open("D:/bill.txt.bak","w",encoding="UTF-8")
# for循环读取文件
for line in fr:
line = line.strip()
# 判断内容,将满足的内容写出
if line.split(",")[4]=="测试":
continue # continue进入下一次循环,这一次后面的内容就跳过了
# 将内容写出去
fw.write(line)
# 由于前面对内容进行了strip操作,所以要手动的写出换行
fw.write("\n")
# close2个文件对象
fw.close()
fr.close()
运行结果: