import requests
import re
import os
filename = '试卷\\'
if not os.path.exists(filename):
os.mkdir(filename)
url = 'https://www.shijuan1.com/a/sjsxg3/list_727_1.html'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
href_list = re.findall("<td width='52%' height='23'><a href=\"(.*?)\" class=\"title\" target='_blank'>",response.text)
title_list = re.findall("class=\"title\" target='_blank'>(.*?)</a>",response.text)
# https://www.shijuan1.com/a/sjywg3/243565.html
for title,href in zip(title_list,href_list):
href = 'https://www.shijuan1.com'+href
data_html = requests.get(url=href,headers=headers)
data_html.encoding = data_html.apparent_encoding
data_url = 'https://www.shijuan1.com'+re.findall('<li><a href="(.*?)" target="_blank">本地下载</a></li>',data_html.text)[0]
doc = requests.get(url=data_url,headers=headers).content
with open('试卷\\'+title+'.rar',mode='wb') as f:
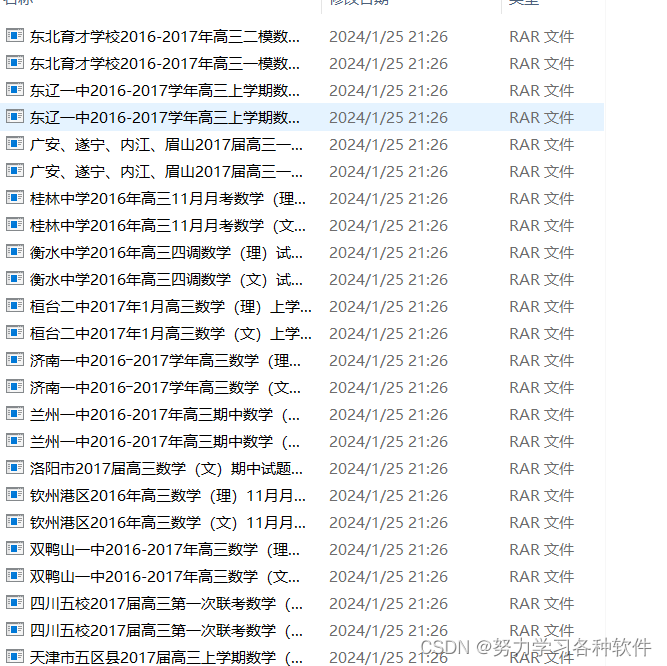
f.write(doc)结果展现:
改进代码:
import requests
import os
import re
def get_html_data(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
return response
def get_analyse_html(response):
href_list = re.findall("<td width='52%' height='23'><a href=\"(.*?)\" class=\"title\" target='_blank'>",
response.text)
title_list = re.findall("class=\"title\" target='_blank'>(.*?)</a>", response.text)
return title_list,href_list
def save(title_list,doc_list):
filename = '试卷\\'
if not os.path.exists(filename):
os.mkdir(filename)
for title,doc in zip(title_list,doc_list):
with open('试卷\\' + title + '.rar', mode='wb') as f:
f.write(doc)
print(f'{title}已经下载完成')
def get_doc(href_list):
doc_list = []
for href in href_list:
href = 'https://www.shijuan1.com' + href
doc_html = get_html_data(href)
data_url = 'https://www.shijuan1.com' + re.findall('<li><a href="(.*?)" target="_blank">本地下载</a></li>', doc_html.text)[0]
doc = get_html_data(data_url).content
doc_list.append(doc)
return doc_list
if __name__ == '__main__':
url = 'https://www.shijuan1.com/a/sjsxg3/list_727_1.html'
response = get_html_data(url)
title_list,href_list = get_analyse_html(response)
doc_list = get_doc(href_list)
save(title_list,doc_list)进一步写成类:
import requests
import os
import re
class save_doc():
def get_html_data(self,href):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=href, headers=headers)
response.encoding = response.apparent_encoding
return response
def get_analyse_html(self,response):
href_list = re.findall("<td width='52%' height='23'><a href=\"(.*?)\" class=\"title\" target='_blank'>",
response.text)
title_list = re.findall("class=\"title\" target='_blank'>(.*?)</a>", response.text)
return title_list, href_list
def save(self,title_list,doc_list):
filename = '试卷\\'
if not os.path.exists(filename):
os.mkdir(filename)
for title, doc in zip(title_list, doc_list):
with open('试卷\\' + title + '.rar', mode='wb') as f:
f.write(doc)
print(f'{title}已经下载完成')
def get_doc(self,href_list):
doc_list = []
for href in href_list:
href = 'https://www.shijuan1.com' + href
doc_html = self.get_html_data(href)
data_url = 'https://www.shijuan1.com' + re.findall('<li><a href="(.*?)" target="_blank">本地下载</a></li>', doc_html.text)[0]
doc = self.get_html_data(data_url).content
doc_list.append(doc)
return doc_list
save = save_doc()
response = save.get_html_data('https://www.shijuan1.com/a/sjsxg3/list_727_1.html')
title_list,href_list = save.get_analyse_html(response)
doc_list = save.get_doc(href_list)
save.save(title_list,doc_list)对于类还是很不熟,我想要类中的方法返回的值,可以直接传入类中的其他方法,应该怎么写呢?我想要写一个类,传入一个url,直接下载所需要的数据,即最终代码为
save = save_doc("https://www.shijuan1.com/a/sjsxg3/list_727_1.html")不需要上面那么复杂的传来传去,应该怎么做呢?