每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 。

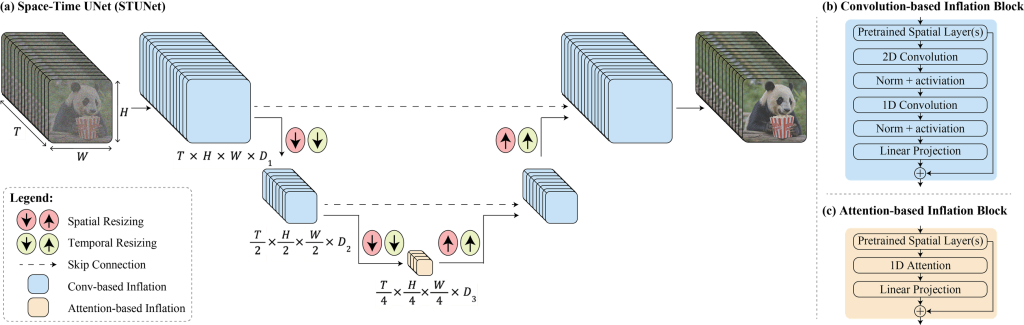
哇塞,最新研发出来的"LUMIERE"可不得了,它是一个文字转视频的扩散模型,专门用来合成展现逼真、多样且连贯动作的视频。你们知道在视频合成领域,这简直是个大挑战!不同于那些老派的视频模型,它们总是先合成一些关键帧,再通过时间超分辨率处理,这样全局时间一致性可就难以实现了。"LUMIERE"可不走寻常路,采用了一种空间-时间U型网络架构,一次性生成整个视频的时间长度,整个过程只需模型单次处理。
这意味着啥?就是它能够同时进行空间和(更重要的是)时间的上下采样,还整合了一个预先训练好的文字到图像的扩散模型。这样一来,"LUMIERE"学习如何直接生成全帧率、低分辨率的视频,并且在多个空间-时间尺度上处理视频。而且,它还展示了顶尖的文字到视频生成效果,轻松地支持各种内容创作任务和视频编辑应用,包括图像到视频、视频修补和风格化生成。
总之,"LUMIERE"简直是视频合成界的黑科技,让视频创作变得像玩儿一样,简直不要太酷!来看看 https://lumiere-video.github.io/