▐ 摘要
视频延展(Video Outpainting)是对视频的边界进行扩展的任务。与图像延展不同,视频延展需要考虑到填充区域的时序一致性,这使得问题更具挑战性。在本文中,我们介绍了一个新颖的基于扩散模型的视频尺寸延展方法——分层遮掩3D扩散模型(Hierarchical Masked 3D Diffusion Model, M3DDM)。通过遮掩建模的训练方法以及把全局视频片段引入交叉注意力层,该模型不仅能够通过引导帧的技术来保证在多次推理的视频片段中确保时序一致性,还能降低相邻帧之间的抖动。此外,我们还提出了一种混合由粗到细(Hybrid Coarse-to-Fine)的推理流程来减轻长视频延展中的错误累积问题。我们的方法在视频延展任务中取得了最先进的结果。该视频尺寸延展算法已在阿里妈妈创意中心上线,同时基于该项工作整理的论文已发表在 ACM MM2023 ,相关代码现已开源,欢迎大家关注。
论文题目:Hierarchical Masked 3D Diffusion Model for Video Outpainting
论文下载:https://arxiv.org/abs/2309.02119
项目主页:https://fanfanda.github.io/M3DDM/
代码链接:https://github.com/alimama-creative/M3DDM-Video-Outpainting
1. 背景介绍
|
|
|
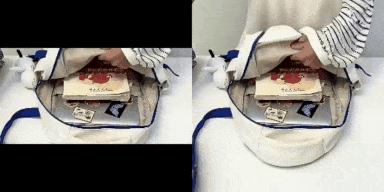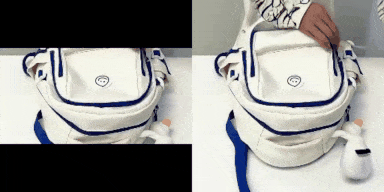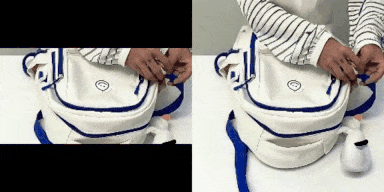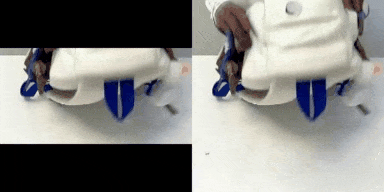


表1: 我们M3DDM算法在垂直、水平以及四周方向的视频延展结果
在我们电商场景中,广告主提供的视频素材存在不适配 APP 展示区域的尺寸的情况。直接拉伸素材视频容易导致展示效果变差,因此我们可以采用视频延展的算法来扩展素材视频的边界,使得延展之后的视频的长宽比适配我们的广告展示区域的尺寸。表一分别展示了我们M3DDM算法在垂直、水平以及四周方向的视频延展结果。考虑到广告主的视频长度普遍大于10s,视频延展任务与图像延展任务相比,带来了以下额外的两个挑战:1). 考虑到 GPU 的显存,我们在推理阶段需要把视频分成多个片段来预测。如何保证多个片段间的时序一致性?2). 长视频延展存在错误累积的问题。
2. 解决方案
为了解决上述的两个挑战,我们在文中提出了以下技术: 1). 我们基于2D图像扩散模型——Stable Diffusion [1]的参数先验构建了3D视频扩散模型。;2). 我们采用引导帧的方式来连接同一视频的多个片段,为此我们提出了一种新的遮掩策略来训练3D视频扩散模型;3). 为了更好的保持时序一致性,我们从视频中抽取了全局帧,经过编码后,放入了模型的交叉注意力层。这使得模型能够在预测当前视频片段时,感知到全局的视频信息,以期望在有空间信息重叠时,模型能够填补更加合理的结果。4). 我们提出了一种混合策略的 Coarse-to-Fine 的推理流水线来缓解长视频错误累积的问题。我们将分别从训练(2.1)和推理(2.2)两方面来讲解算法细节。
2.1 训练: 遮掩扩散3D模型
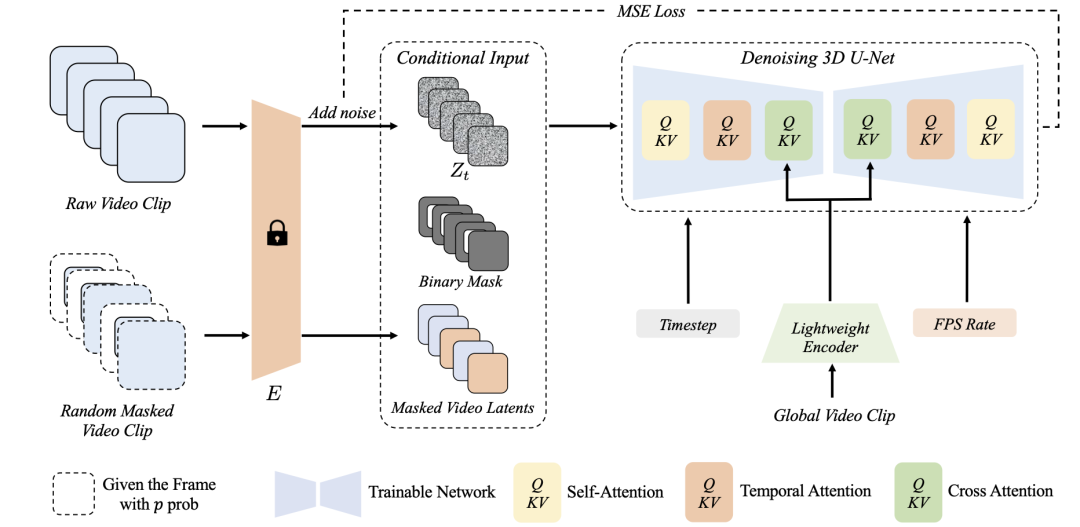
我们在图1展示了M3DDM的训练过程。我们的方法是基于扩散模型 [2, 3, 4]的。扩散模型是一类生成式模型,它对原始分布加噪并通过一个深度网络来预测噪声的方式来训练一个去噪网络,以便于在推理阶段,我们能够从标准正态分布随机采样一个噪声来逐步推理原始数据分布。在视频延展场景中,我们在训练阶段要学习一个3D U-Net [5]的去噪网络去拟合视频样本中的噪声。我们网络的输入是添加了次高斯分布噪声的视频样本、二值的掩码来指示哪部分区域是需要被填充的以及遮掩过后的视频,同时在交叉注意力层输入全局的视频帧(遮掩过后的,避免泄漏),输出是添加的高斯噪声。降噪网络通过以下损失函数进行训练:
其中是我们的条件输入。我们将在下面的小节分别介绍主体的网络结构,训练的遮掩策略以及如何用全局帧为提示来训练网络。
2.1.1 以Stable Diffusion模型参数为先验
我们的视频延展方法基于Stable Diffusion [1]。Stable Diffusion是一个文本到图像的潜在扩散模型。选择它在这里有两大好处:
它们在潜在空间而非像素空间对视频帧进行编码,因此需要更少的内存并且能够实现更好的效率;
2D图像扩散模型的参数先验有利于我们在视频延展任务的快速收敛。
为了使其原始的Stable Diffusion的网络适应我们的视频延展任务,我们增加了了时序卷积,同时修改了自注意力层以及交叉注意力层来确保不同帧之间的交互。
2.1.2 遮掩策略
为了构建视频延展的训练样本,我们随机地遮掩每个帧的边缘部分。我们采用不同方向策略对帧进行遮蔽:全方向、单一方向、双向(左右或上下)、任意四个方向中的随机一个方向,以及全遮掩。考虑到实际应用场景,我们分别采用这五种策略的比例为0.2、0.1、0.35、0.1和0.25。“全遮掩”策略使模型能够进行无条件生成,这允许我们在推理阶段采用无分类器引导技术 [6]。考虑到实际应用场景中需要外部延展的边缘区域的大小,我们均匀地从[0.15, 0.75]中随机采样帧的遮掩比例。我们称遮掩过后的帧为上下文帧。
为了能够在推理阶段使用引导帧,我们在每一个训练batch中,用以下三种模式中的一种:
所有帧仅给出上下文信息,每个帧都采用上述遮掩策略。
第一帧或第一和最后一帧被原始未遮掩的帧替换,其余帧仅给出上下文信息。
任何帧都有0.5的概率被未遮掩的原始帧替换。
这些训练模式允许模型不仅基于上下文信息预测边缘区域,还基于相邻的引导帧。相邻的引导帧可以帮助生成更连贯、抖动更少的结果。我们平均三种情况的训练比例。这三种情况的比例分别是0.3、0.35和0.35。我们不仅仅使用第3种模式进行训练,因为我们考虑到在预测阶段前两种情况可能会更频繁地使用。
2.1.3 用全局帧为提示
为了使模型能够感知当前片段之外的全局视频信息,我们均匀地从视频中采样16帧。这些全局帧通过一个可学习的轻量级编码器来获取特征图,然后通过交叉注意力机制输入到3D-UNet中。我们没有在3D-UNet的输入层中加入全局帧,因为我们认为交叉注意力可以使模型更加关注遮掩的帧与全局帧的交互,而不是全局帧自己的交互。值得注意的是,在这里输入的全局帧与当前视频片段的遮掩策略对齐,并且与其他帧一样采用相同的方式进行遮蔽,以避免信息泄露。
2.2 推理: 混合由粗到细的推理流水线

在长视频延展中,我们往往需要对视频进行上百次的推理拼接,前面片段生成的坏结果由于引导帧的作用会持续累积到后面的片段中。为了缓解这个问题,我们提出了混合由粗到细(Hybrid Coarse-to-Fine)的推理流水线。如图2所示,我们的推理流水线先稀疏的生成关键帧,再根据关键帧填补更多的中间结果,最后采用前后引导帧的形式密集的对视频未填充的部分进行填补。由于关键帧的间隔比较大,因此我们的方法可以以较少的迭代次数生成视频的关键帧,从而有效的缓解了错误累积的问题。与传统的只包含了无条件(Uncondition)和前后引导(Infilling)策略的方法比,我们的混合策略引入了插值(Interplotation)的方式,缓解了3级结构中第一级结构中关键帧间距过大带来的效果退化。
3. 实验分析

我们在图3中展示了我们的M3DDM在Davis和YouTube-VOS数据集与Dehan [7]和简单的扩散模型的方案 [1](Simple Diffusion Model)方法的定量对比。我们测试了水平方向的视频延展,遮掩比例为0.25以及0.666。我们在256的分辨率下计算了这5个评价指标在所有视频样本的平均值(FVD是整体计算的)。可以看出我们的方案显著的优越于基于flow预测的Dehan [7]和SDM [1]。

我们在图4展示了我们的M3DDM与Dehan [7]和SDM [1]的定性评估。可以看出我们的方法能够更好的保证时序一致性,生成更连贯合理的视频结果。更多的定性评估可以参考我们的论文和项目主页。
4. 算法落地
该算法已在阿里妈妈-创意中心(https://chuangyi.taobao.com/)素材库上线,商家可以对素材库中的视频以外扩的形式进行多种尺寸修改,以适配各种尺寸的广告位,提升广告的流量覆盖。
5. 总结
在本文中,我们提出了一种基于遮掩建模的3D扩散模型,用于视频延展(Video Outpainting)。我们使用遮掩建模的学习策略并将全局视频片段的编码作为交叉注意力层的输入。遮掩建模的双向学习方法使我们在推理阶段可以有更灵活的策略,同时更好地感知相邻帧的信息。添加全局视频片段作为提示进一步提高了我们方法的性能。在大多数摄像机移动和前景主体滑动的情况下,全局视频片段帮助模型在待填充区域生成更合理的结果。我们还提出了一种用于视频延展的混合由粗到细的推理流水线,它结合了前后引导和插值策略,以避免由于多级结构对齐问题而在最粗糙阶段产生的关键帧之间的大时间间隔问题。实验表明,该方法已达到较为先进的结果。目前,该算法已在阿里妈妈创意中心素材库上线,相关代码已开源,欢迎关注&试用体验。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入,一起拥抱 AIGC 时代!感兴趣同学欢迎投递简历加入我们。
投递链接(点击下方↓阅读原文):https://talent.taotian.com/off-campus/position-detail?lang=zh&positionId=1049709
▐ 参考文献
[1] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695.
[2] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning. PMLR, 2256–2265.
[3] Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 33 (2020), 6840–6851.
[4] Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning. PMLR, 8162–8171.
[5] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolu- tional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 234–241.
[6] Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022).
[7] Loïc Dehan, Wiebe Van Ranst, Patrick Vandewalle, and Toon Goedemé. 2022. Complete and temporally consistent video outpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 687–695.
END

也许你还想看
🔥《计算机视觉 in 阿里妈妈》文章合集
丨ACM MM’23 | 4篇论文解析阿里妈妈广告创意算法最新进展
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨实现"模板自由"?阿里妈妈全自动无模板图文创意生成
丨告别拼接模板 —— 阿里妈妈动态描述广告创意
丨如何快速选对创意 —— 阿里妈妈广告创意优选
丨化繁为简,精工细作——阿里妈妈直播智能剪辑技术详解
丨CVPR 2023 | 基于内容融合的字体生成方法
丨CVPR 2023 | 基于无监督域自适应方法的海报布局生成
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~